The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping
Abstract: Despite the success of reinforcement learning for LLMs, a common failure mode is reduced sampling diversity, where the policy repeatedly generates similar erroneous behaviors. Classical entropy regularization encourages randomness under the current policy, but does not explicitly discourage recurrent failure patterns across rollouts. We propose MEDS, a Memory-Enhanced Dynamic reward Shaping framework that incorporates historical behavioral signals into reward design. By storing and leveraging intermediate model representations, we capture features of past rollouts and use density-based clustering to identify frequently recurring error patterns. Rollouts assigned to more prevalent error clusters are penalized more heavily, encouraging broader exploration while reducing repeated mistakes. Across five datasets and three base models, MEDS consistently improves average performance over existing baselines, achieving gains of up to 4.13 pass@1 points and 4.37 pass@128 points. Additional analyses using both LLM-based annotations and quantitative diversity metrics show that MEDS increases behavioral diversity during sampling.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching LLMs to make fewer repeated mistakes when they learn by trial and error. The authors introduce a training method called MEDS (Memory-Enhanced Dynamic reward Shaping) that remembers the model’s past errors and punishes repeated mistake patterns more strongly. This helps the model explore new, better ways to solve problems instead of getting stuck making the same kinds of errors over and over.
What questions did the researchers ask?
They focused on three simple questions:
- Why do LLMs often get “stuck” repeating similar wrong answers during training?
- Can we design rewards so the model actively avoids repeating the same mistake pattern?
- Will remembering past errors and penalizing repeats improve both accuracy and variety in the model’s solutions?
How did they do it? (Methods in everyday language)
Think of training an LLM like coaching a student who solves math problems by trying different steps (reasoning) and getting points (rewards) for correct answers. Normally, if the student keeps using the same wrong approach, they might keep losing points—but not more than usual—so they often fall back into the same bad habit. MEDS changes that by remembering mistake styles and making the penalty stronger each time the same mistake style shows up.
Here’s the idea with simple analogies:
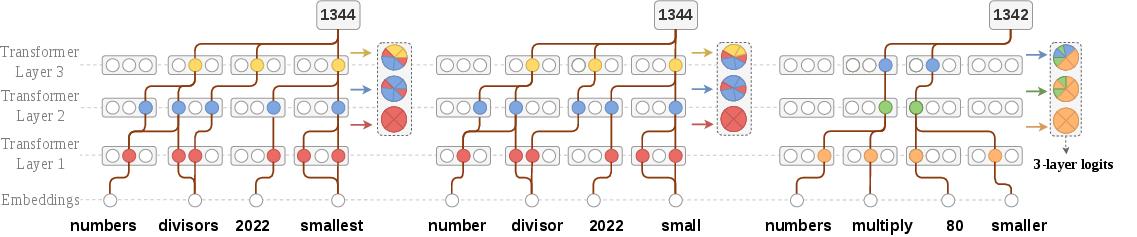
- The model tries to answer a question many times (these tries are called “rollouts”).
- Inside the model, before it chooses each word, it produces “logits,” which are like confidence scores for different words. Across the model’s layers (think “layers” as stages of thinking), those scores form a tiny “fingerprint” of how it reasoned.
- If two answers have similar fingerprints, they likely used a similar reasoning pattern—even if the words look different on the surface.
MEDS uses this in three steps:
- Step A: Make a fingerprint of the model’s reasoning. The authors reuse the model’s own internal scores (layer-wise logits) for a key token in the final answer. This costs almost nothing extra and acts like a compact signature of how the model reasoned.
- Step B: Group similar mistakes. For each problem, MEDS keeps a memory of fingerprints from previous wrong attempts. It uses an algorithm called HDBSCAN (a clustering method) to group similar fingerprints. You can think of this as sorting common mistake styles into “buckets.”
- Step C: Shape the reward. If the model’s new attempt falls into a large “mistake bucket” (meaning “we’ve seen this kind of wrong reasoning many times”), MEDS subtracts a bigger penalty from the reward. The more common the mistake pattern, the larger the penalty—up to a limit—encouraging the model to try something different next time.
They also provide a simple theoretical argument: if you punish repeated errors more, you don’t hurt the overall expected performance; you redirect the model away from low-value, overused mistakes toward new, potentially better strategies.
What did they find, and why is it important?
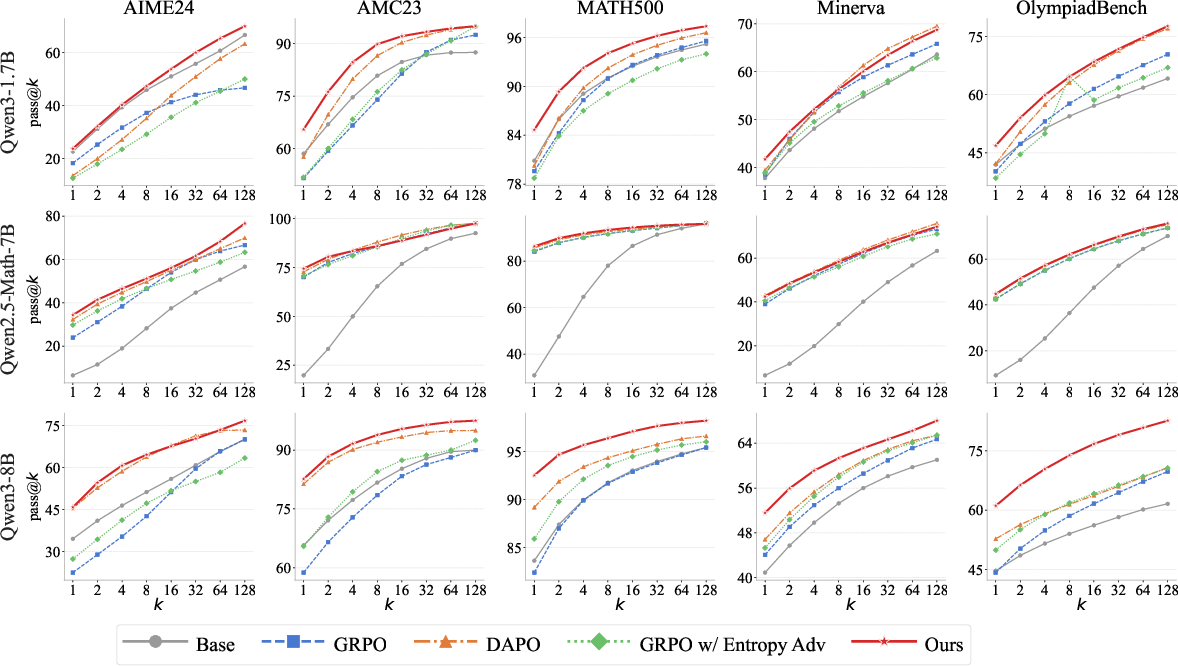
Across five math benchmarks and three different base models, MEDS consistently improved results compared to strong existing methods. Two common accuracy measures are:
- pass@1: Did the best single try solve the problem?
- pass@128: Did any of 128 tries solve the problem?
Key outcomes:
- MEDS improved pass@1 by up to about 4.13 points and pass@128 by up to about 4.37 points over the best baselines.
- On one model (Qwen3-8B) and one dataset, pass@128 jumped from 70.81 to 82.67—about a 17% relative improvement.
- MEDS increased the diversity of the model’s attempts. In other words, the model explored more different ways of reasoning instead of repeating the same failed approach. The authors checked this both with an LLM judge (which rated how varied the reasoning was) and with a math-y representation metric showing the internal fingerprints spread out more evenly.
Why this matters: Exploration is crucial. If a model keeps trying the same wrong reasoning, it wastes time and data. By discouraging repeated mistake patterns, MEDS helps the model search more widely and find better solutions faster.
What could this lead to? (Implications and impact)
- Smarter training: Adding memory of past errors to the reward system makes learning more like a good teacher who says, “You’ve made this exact mistake before—try a new approach.”
- Better reasoning: Models become less stuck in “error ruts,” which can lead to higher accuracy on tough problems.
- General use: Although tested on math problems, the idea—remembering and penalizing repeated failure modes—could help many tasks where exploration matters (coding, planning, scientific reasoning).
- Efficient and practical: MEDS reuses data the model already produces (logits), so it adds little extra cost.
A simple limitation: The way they build the “fingerprint” from logits is intentionally simple. There might be more advanced ways to combine internal signals to get even better results.
Quick glossary
- Reinforcement learning (RL): Learning by trying actions and getting rewards or penalties—like practicing and getting feedback.
- Reward shaping: Tweaking the reward rules to guide learning in a helpful way.
- Logits: The model’s internal “confidence scores” for possible next words, before they’re turned into probabilities.
- Clustering: Grouping similar items. Here, grouping similar “reasoning fingerprints” to find repeated mistake patterns.
- HDBSCAN: A clustering method that can find groups of different sizes without needing to pre-set how many groups you want.
- pass@k: The chance that at least one of k attempts is correct. For example, pass@1 is your best single try; pass@128 is your best out of 128 tries.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Generalization beyond math reasoning and RLVR tasks: MEDS is only evaluated on math benchmarks with verifiable (binary) rewards. Its effectiveness on other domains (e.g., open-ended natural language tasks, code generation with flaky executors, multimodal reasoning) and in RLHF/preference settings with noisy/subjective rewards is untested.
- Per-prompt memory only: The method maintains error memories per prompt, leaving open whether cross-prompt or task-level memories could capture global failure modes (e.g., systematic algebraic mistakes) and provide stronger generalization and sample efficiency.
- Representation drift across training: Clusters are created from historical logits while the policy changes; the paper does not address whether representational drift over training steps degrades cluster consistency or requires feature alignment (e.g., CCA, whitening, normalization schedules).
- Reliance on a single token position: MEDS uses layer-wise logits for only the first token of the final answer. It is unknown whether incorporating multiple positions (e.g., intermediate chain-of-thought tokens, final-span tokens) or token-agnostic features (e.g., pooled activations) would yield more reliable error pattern detection.
- Limited feature space exploration: Only simple concatenations/differences of layer-wise logits are tested. More expressive features (e.g., SAE latents, attention head patterns, MLP activations, representation projections) and their trade-offs in clustering quality and performance are left unexplored.
- Clustering design choices and sensitivity: The method fixes HDBSCAN with Euclidean distance (after L2 normalization) and specific hyperparameters. Sensitivity to:
- clustering algorithm (e.g., incremental/streaming clustering, DP-means, online HDBSCAN, density vs. centroid methods),
- distance metrics (cosine, learned metrics),
- min cluster size/samples and noise handling,
- memory pruning strategies,
- remains unstudied.
- Scalability and resource footprint: While small timing overhead is reported on one model/config, the paper does not quantify memory/storage growth of per-prompt histories, clustering cost over long training runs, or distributed synchronization overhead in large-scale settings.
- Hyperparameter robustness: The penalty schedule (α, β), warmup (first epoch memory-building), and layer count (e.g., “last 14”) lack comprehensive sensitivity analyses across models/datasets. Guidelines for tuning and stability across seeds are missing.
- Theoretical guarantees are limited: The theorem claiming non-decreasing expected return under repeated-error penalties relies on unspecified assumptions and does not account for KL-regularization, stochastic optimization, reward noise, or function approximation. Convergence, regret, and stability analyses are absent.
- Robustness to verifier noise and mislabels: MEDS penalizes clusters of “incorrect” rollouts based on verifiers. Its behavior under noisy/partial rewards (e.g., execution nondeterminism in code, ambiguous solutions) and the risk of penalizing actually-correct-but-mislabeled patterns are not investigated.
- Misclassification and false cluster assignments: Logit–LLM cluster agreement is ~61%, indicating moderate alignment. The impact of clustering errors (false merges/splits) on training dynamics and correctness has not been quantified or mitigated (e.g., with confidence thresholds or soft penalties).
- Evaluation and statistical rigor: Results are reported with a single random seed and without statistical significance tests or variance estimates. Stability across seeds, datasets, and training runs remains uncertain.
- Diversity metrics validation: The LLM-based diversity assessments depend on a single annotator model (Claude-Haiku-4.5) and bespoke prompts. Cross-annotator consistency, robustness to prompt variations, and correlation with human judgments or standardized diversity metrics are not established.
- Alternative, cheaper baselines: The paper does not compare against simpler deduplication/penalty schemes (e.g., n-gram/string-level novelty penalties, Levenshtein-based clustering), making it unclear how much of the gain comes from representation-level clustering versus any novelty-penalization heuristic.
- Interaction with other exploration regularizers: Only one entropy-advantage configuration is tested. How MEDS composes with KL constraints, entropy bonuses (swept across strengths), outcome-based exploration, or novelty bonuses for rare correct trajectories is not systematically explored.
- Tokenization and formatting sensitivity: Using the “first token of the final answer” assumes a predictable answer format (Qwen-Math template). Robustness to different templates, multi-token answers, or tasks where “final answer” is hard to parse is not examined.
- Reward shaping functional form: The penalty function min(α·log(|Ck|+1), β) is chosen without ablations against alternatives (e.g., power laws, inverse-frequency advantages, adaptive capping). Its effects on optimization stability and fairness across cluster sizes remain unclear.
- Potential unintended incentives: MEDS may encourage superficial variation to avoid cluster penalties rather than deeper reasoning changes. The extent to which diversity gains correspond to improved logical validity rather than error type switching is not rigorously analyzed.
- On-policy vs. off-policy applicability: The framework is demonstrated in on-policy RL; extensions to off-policy or replay-based regimes (and their memory/clustering implications) are unaddressed.
- Length, fluency, and format effects: Penalizing repeated errors might indirectly impact response length, verbosity, or formatting (e.g., to change logits). The paper does not analyze such side effects or include formatting/length controls.
- Cross-model portability: It is unknown whether learned error memories or clustering configurations transfer across model sizes/architectures or across training stages without re-initialization.
- Online/streaming clustering and pruning: The paper states online memory updates but HDBSCAN is typically batch. Practical strategies for incremental updates, periodic reclustering, pruning old samples, or time-decay weighting are not specified.
- Safety and harmful behavior: The impact of MEDS on safety-relevant failure modes (e.g., reducing repetitive harmful or dishonest patterns) is not explored, nor are any negative side effects on harmlessness or calibration.
- Real-world budgets and latency: MEDS is evaluated with 16 rollouts per prompt during training and pass@128 at evaluation. Its effectiveness under tighter sampling budgets (e.g., pass@1–5) and latency-constrained settings is only partially assessed (pass@1 reported, but not under varied training-time rollout budgets).
- Cross-dataset error-mode transfer: Whether penalizing an error cluster on one dataset reduces similar errors on another (transfer of “avoidance memory”) is untested.
- Monitoring and diagnostics: There is no procedure for detecting when clusters conflate distinct error types or for auditing cluster semantics during training—leaving practical debugging tools unexplored.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s MEDS framework (memory-enhanced dynamic reward shaping via logit-based clustering and density-aware penalties) and the open-source implementation.
- Software (code generation, program synthesis): Reduce repeated buggy patterns during RLVR training for coding assistants
- How: Integrate MEDS into execution-verified RL training (e.g., GRPO/DAPO pipelines) to penalize frequently recurring failure modes identified via HDBSCAN clusters of layer-wise logits from incorrect rollouts. Use sandbox execution as the verifier.
- Tools/Workflow: “MEDS module” for verl/TRL; LogitFeatureExtractor; ErrorMemory per prompt; ClusterPenalty; automated test runners for verifiable rewards.
- Assumptions/Dependencies: Availability of verifiable tasks (execution in sandbox), access to layer-wise logits in training, sufficient batch sizes/rollouts for clustering to be meaningful, careful tuning of α/β; storage budget for error memory.
- Education (math tutoring LLMs): Improve diversity of solution strategies and reduce repeated wrong reasoning
- How: Apply MEDS during RLVR with exact-match answer verification on math datasets; penalize clusters of recurring erroneous solution paths to increase exploration and pass@k.
- Tools/Workflow: Tutor RL Fine-tuner built on MEDS; pass@k evaluation; Qwen-Math-style templates; diversity monitoring via Top-1 Eigen Ratio.
- Assumptions/Dependencies: Verifiable math problems (answer checkers), per-prompt memory maintained online; alignment with curriculum goals; compute resources similar to DAPO.
- Search/RAG (reasoning augmentation): Encourage diversified reasoning chains for fact-based QA with verifiable answers
- How: Use MEDS in RL to suppress common failure chains (e.g., repeated irrelevant retrieval paths), based on logits-derived cluster membership of failed rollouts; reward shaping improves exploration of alternative chains.
- Tools/Workflow: RAG evaluator for verifiability (exact answers or grounded citations), per-query error memory store; cluster-aware sampling.
- Assumptions/Dependencies: Reliable verifiers, logging of logits at relevant positions (e.g., first answer token), enough samples per prompt to form meaningful clusters.
- Customer support and operations chatbots (task-oriented flows): Reduce repeated misrouting or incorrect procedural steps
- How: In workflows with deterministic/verifiable endpoints (order status, refund eligibility), train with MEDS to penalize frequent failure paths and diversify exploration before converging to correct flow.
- Tools/Workflow: Rule-based verifiers for business workflows; per-intent error memory; cluster penalties capped to avoid over-penalization.
- Assumptions/Dependencies: Existence of verifiable endpoints; conformity of response formats; privacy-compliant storage of failure memory.
- Finance and data science (quant QA, analytical assistants): Minimize recurrent calculation mistakes in numerical reasoning with verifiable outcomes
- How: Incorporate MEDS in RLVR for quantitative queries with known answers or unit tests; penalize repeat error clusters to push exploration toward correct arithmetic/logic.
- Tools/Workflow: Unit-test verifiers; exploration diversity dashboard; model monitoring (Top-1 Eigen Ratio) to detect error collapse.
- Assumptions/Dependencies: Availability of verifiable datasets; careful handling of floating-point tolerances; adherence to compliance/privacy when storing error memory.
- Robotics and planning (simulated task decomposition via language): Reduce repeated planning dead-ends in simulation
- How: Apply MEDS where task success can be verified in a simulator; penalize common failure plan clusters to broaden planning exploration.
- Tools/Workflow: Simulation-based verifiers; per-task error memory; logit collection and cluster formation inline with training.
- Assumptions/Dependencies: Fast simulators for verifiable rewards; mapping from language steps to simulation actions; sufficient samples to form clusters.
- ML engineering (training-pipeline augmentation): Drop-in adoption of memory-based reward shaping in existing RLVR setups
- How: Add MEDS to GRPO/DAPO training with minimal overhead (reuse logits from forward pass); monitor diversity and performance gains.
- Tools/Workflow: Integration with verl; HDBSCAN with recommended hyperparameters (min cluster size, sample count); capped penalties (α/β).
- Assumptions/Dependencies: Access to model internals (logits); reliable storage; consistent prompt templates; compute budget comparable to DAPO.
- Research (interpretability and training diagnostics): Monitor and act on error collapse using representation-level signals
- How: Adopt Top-1 Eigen Ratio monitoring and logit-based clustering to quantify and reduce exploration collapse; use MEDS penalties to reshape behavior.
- Tools/Workflow: Diversity metrics (Within-Step/Across-Step Diversity protocol); logit heatmaps; agreement checks with LLM annotations (~61% correlation reported).
- Assumptions/Dependencies: Logging infrastructure, annotation proxies (optional), consistent training checkpoints.
- Inference-time sampling/reranking (without retraining): Reduce selection of common failure patterns in n-best outputs
- How: Build a lightweight inference-time re-ranker that downweights candidates mapped to large historical error clusters (from dev-set memory).
- Tools/Workflow: Offline error memory built on dev data; logit extraction at inference; cluster-aware reranking of beams/samples.
- Assumptions/Dependencies: Approximation—no direct reward shaping; correlation between cluster membership and error (depends on domain and 61% proxy quality); careful thresholding to avoid suppressing rare but correct outputs.
Long-Term Applications
These will likely require additional research, scaling, domain-specific verifiers, or productization beyond the current math/code-focused RLVR context.
- Healthcare (clinical decision support and coding): Suppress recurrent harmful recommendations or miscodings via memory-aware penalties
- What: Penalize clusters of mistakes (e.g., diagnostic misclassification, CPT/ICD miscoding) during training to reduce persistent failure modes.
- Dependencies: High-quality, domain-approved verifiers; rigorous evaluation for safety/effectiveness; privacy-preserving error memory; regulatory compliance.
- AI safety and policy (governance of training processes): Encourage standards for diversity-preserving training and error-memory auditing
- What: Policy frameworks that recommend/require mechanisms mitigating error collapse (e.g., memory-informed reward shaping) and audit trails of recurrent failure clusters.
- Dependencies: Measurement standards (e.g., Top-1 Eigen Ratio, diversity metrics), transparency on training logs, privacy and fairness safeguards.
- Agentic systems (tool-using planners, autonomous workflows): Reduce repeated failed tool-use or planning paths across tasks and environments
- What: MEDS-like penalties at hierarchical levels (subtasks, tools, strategies) using richer feature representations (SAEs, attention circuits) rather than just final-answer token logits.
- Dependencies: Generalizable verifiers for multi-step tasks; improved feature extraction beyond simple logit concatenation; scalable cross-task memory.
- Personalized education (tutoring systems that model learners’ errors): Adaptively penalize a student’s recurrent error patterns to drive exploration of alternative solution paths
- What: Extend error memory from model-centric to student-centric signals; propose strategies encouraging diverse reasoning.
- Dependencies: Accurate detection of human error categories; user consent and privacy; careful design to avoid frustration or unfair penalty dynamics.
- Content safety and moderation (harmful pattern suppression): Memory-aware penalties to suppress recurring disallowed outputs or jailbreak strategies in training
- What: Identify clusters of unsafe outputs and penalize them during RLHF/RLVR; diversify safe behavior.
- Dependencies: Robust safety verifiers; strong false-positive controls; transparency in penalty policies; long-term tracking across prompts/users.
- Cross-domain generalization (beyond math and code): Apply MEDS to tasks with softer or proxy verifiers (e.g., factual QA, summarization correctness)
- What: Use hybrid verifiers (retrieval grounding, consistency checks) and richer features (intermediate chain-of-thought logits, token-level patterns) to broaden applicability.
- Dependencies: Reliable proxies for verifiability; better clustering signals than single-token logits; domain-specific evaluation.
- Production-scale training (multi-task, multi-lingual, cross-prompt memory): Scale error memory beyond per-prompt, enabling cross-prompt and cross-domain suppression of common failure modes
- What: Global/shared error memory services; distributed clustering; penalty policies across tasks.
- Dependencies: Efficient memory systems; data governance; performance guarantees across heterogeneous tasks and languages.
- Advanced tooling (feature learning and adaptive penalties): Replace simple concatenated logits with learned representations (SAEs/embeddings) and adaptive penalty schedules
- What: Feature learning modules that encode reasoning circuits; curriculum-aware penalty dynamics; meta-learning for cluster importance.
- Dependencies: Research into representation robustness; computational overhead management; stability of training.
- Evaluation standards and benchmarks (diversity metrics adoption): Institutionalize exploration diversity metrics in model evaluation and leaderboards
- What: Include metrics like Top-1 Eigen Ratio and LLM-scored diversity in benchmarks; track relationship between clustering quality and downstream performance.
- Dependencies: Community consensus; reproducibility protocols; tools to compute and report these metrics.
- Sustainability (compute efficiency and Green AI): Use MEDS to reduce wasted on-policy samples by avoiding repetitive failures
- What: Strategically penalize repeated errors to improve sample efficiency and reduce training compute over time.
- Dependencies: Longitudinal evidence of efficiency gains; integration with scheduling and resource management; trade-off studies vs. entropy/KL baselines.
Cross-cutting assumptions and dependencies
- Verifiability: MEDS is most effective in RLVR settings with reliable verifiers (exact match, execution, simulation, grounding).
- Feature access: Requires access to layer-wise logits at training time; inference-time variants are approximate.
- Cluster quality: Performance gains correlate with clustering quality; last-half-layer logits worked best in reported experiments, but may need domain-specific tuning.
- Hyperparameters and scaling: Penalty strength and caps (α, β) must be tuned; storage and compute overhead are modest but non-zero.
- Safety, privacy, and fairness: Error memories must be designed to avoid penalizing benign stylistic patterns, protect user data, and maintain fairness across populations.
- Generalization: The reported gains are in mathematical reasoning; additional validation needed for other domains before broad deployment.
Glossary
- Across-Step Diversity: An evaluation measure assessing whether samples generated at later training steps introduce new reasoning patterns compared to earlier steps. Example: "Across-Step Diversity instead evaluates whether later-stage rollouts exhibit new reasoning patterns relative to earlier ones for the same model and input prompt."
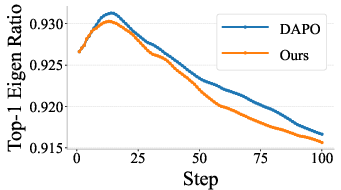
- covariance structure: The pattern of pairwise statistical relationships among feature dimensions (e.g., logits) across samples. Example: "we further analyze the covariance structure of the stored logits across all steps and compute the ratio between the largest eigenvalue and the sum of all eigenvalues."
- DAPO: A reinforcement learning algorithm/baseline for training LLMs used for comparison in this work. Example: "We compare the proposed MEDS with two commonly used RL algorithms: GRPO and DAPO."
- density-based clustering: A clustering approach that groups points based on regions of high sample density, enabling automatic detection of clusters and noise. Example: "use density-based clustering to identify frequently recurring error patterns."
- entropy regularization: An RL technique that adds an entropy bonus to the objective to encourage randomness and exploration in the policy. Example: "Classical entropy regularization encourages randomness under the current policy, but does not explicitly discourage recurrent failure patterns across rollouts."
- error basin: A region in parameter/output space where training dynamics concentrate on stable but incorrect behaviors. Example: "the policy evolves from a high-entropy distribution into a narrow, stable error basin."
- error collapse: The degeneration of model behavior into a small set of repeated failure modes during on-policy optimization. Example: "Illustration of error collapse in on-policy optimization and its effect on output diversity."
- HDBSCAN: A hierarchical density-based clustering algorithm that infers the number of clusters and labels noise points without requiring k as input. Example: "we maintain a per-prompt error memory G_x and apply HDBSCAN to group historical responses with similar logic features."
- KL regularization: Regularizing policy updates using the Kullback–Leibler divergence to limit deviation from a reference policy. Example: "Traditional approaches mitigate this by constraining policy shift via KL regularization"
- L2 normalization: Scaling a vector to unit length under the Euclidean norm, often used before distance-based clustering. Example: "we concatenate the logits from the last 14 Transformer layers and apply L2 normalization"
- layer-wise logits: The per-layer pre-softmax scores for tokens, used here as features to capture internal reasoning patterns across a model’s layers. Example: "By reusing the layer-wise logits already produced during the forward pass, we construct feature vectors of the model's implicit reasoning trajectory."
- logit: The unnormalized score (pre-softmax) for a token; its evolution can reflect internal computation. Example: "The evolution of logits for the final answer depends on feature activations across different layers"
- logit-based clustering: Grouping responses by similarity in their logit-derived feature representations to identify shared reasoning patterns. Example: "we further analyze the consistency between logit-based clustering and LLM-based clustering"
- MEDS (Memory-Enhanced Dynamic reward Shaping): The proposed framework that records historical error patterns and dynamically penalizes repeated failures to promote exploration. Example: "We propose MEDS, a Memory-Enhanced Dynamic reward Shaping framework that incorporates historical behavioral signals into reward design."
- pass@k: An evaluation metric indicating the fraction of problems solved correctly when up to k samples are considered. Example: "We also plot the pass@k curves, where k takes values in {1, 2, 4, 8, 16, 32, 64, 128}."
- proxy model: An auxiliary model used to approximate a desired evaluation or reward signal when direct verification is complex. Example: "whether derived from rule-based evaluation or proxy models"
- reference policy: A fixed or slowly changing policy used as an anchor to constrain updates via KL regularization. Example: "where $p_{\mathrm{ref}$ is the reference policy that constrains the update space"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL paradigm where rewards come from deterministic, automatable verifiers rather than subjective human judgments. Example: "Reinforcement Learning with Verifiable Rewards (RLVR) has become the dominant paradigm due to the simplicity of its reward signals."
- rollout: A sampled trajectory/response generated by a policy for a given prompt, used for training and evaluation. Example: "Rollouts assigned to more prevalent error clusters are penalized more heavily"
- reward shaping: Modifying or augmenting the reward function to guide learning toward desired behaviors. Example: "we can directly compute the indicator function and perform the corresponding reward shaping."
- Top-1 Eigen Ratio: The ratio of the largest eigenvalue to the sum of all eigenvalues of a covariance matrix; used here to quantify concentration in representation space. Example: "We refer to this metric as the Top-1 Eigen Ratio."
- trust region: A constraint on the magnitude of policy updates to ensure stable and conservative improvement. Example: "maximize the expected return within a trust region."
- UCB-style exploration rewards: Bonuses inspired by Upper Confidence Bound strategies that encourage exploration based on uncertainty or infrequent outcomes. Example: "introduces UCB-style exploration rewards based on historical outcome frequencies."
- Within-Step Diversity: An evaluation measure of the variety among multiple rollouts produced at the same training step for the same prompt. Example: "Within-Step Diversity measures the diversity of rollouts generated by DAPO and MEDS at the same training step for the same input prompt."
Collections
Sign up for free to add this paper to one or more collections.