- The paper introduces the HORIZON framework to identify failure modes in long-horizon tasks using over 3100 cross-domain agent rollouts.
- It reveals that agents experience abrupt, horizon-conditioned performance collapses due to compounded planning, memory, and execution errors.
- The study establishes a seven-category failure taxonomy, distinguishing process-level (72.5%) from design-level issues to guide future system improvements.
Diagnosing Failure in Long-Horizon Agentic Systems: The HORIZON Framework
Introduction
Systematic long-horizon task execution with LLM-based agents exposes substantial limitations in the reliability and robustness of current architectures, despite state-of-the-art (SOTA) short-horizon performance. "The Long-Horizon Task Mirage? Diagnosing Where and Why Agentic Systems Break" (2604.11978) directly tackles two key research questions for agentic system reliability: (1) at what horizon levels does agent performance sharply degrade, and (2) what are the concrete causal mechanisms underlying these failures as horizon increases. The authors present HORIZON, a cross-domain diagnostic benchmark and analysis workflow addressing the urgent methodological deficits in horizon-conditioned agent evaluation, attribution, and failure taxonomization.
HORIZON: Structured Horizon and Failure Attribution
Agentic Execution and Breakdown Propagation
The paper begins by framing long-horizon agent rollouts as cyclic perception–planning–action–memory update loops, with compounding opportunities for failure at every cycle, leading to irrecoverable state divergence and accumulating trajectory degradation. The authors present a graphical depiction of general agentic cycles and error propagation loci.
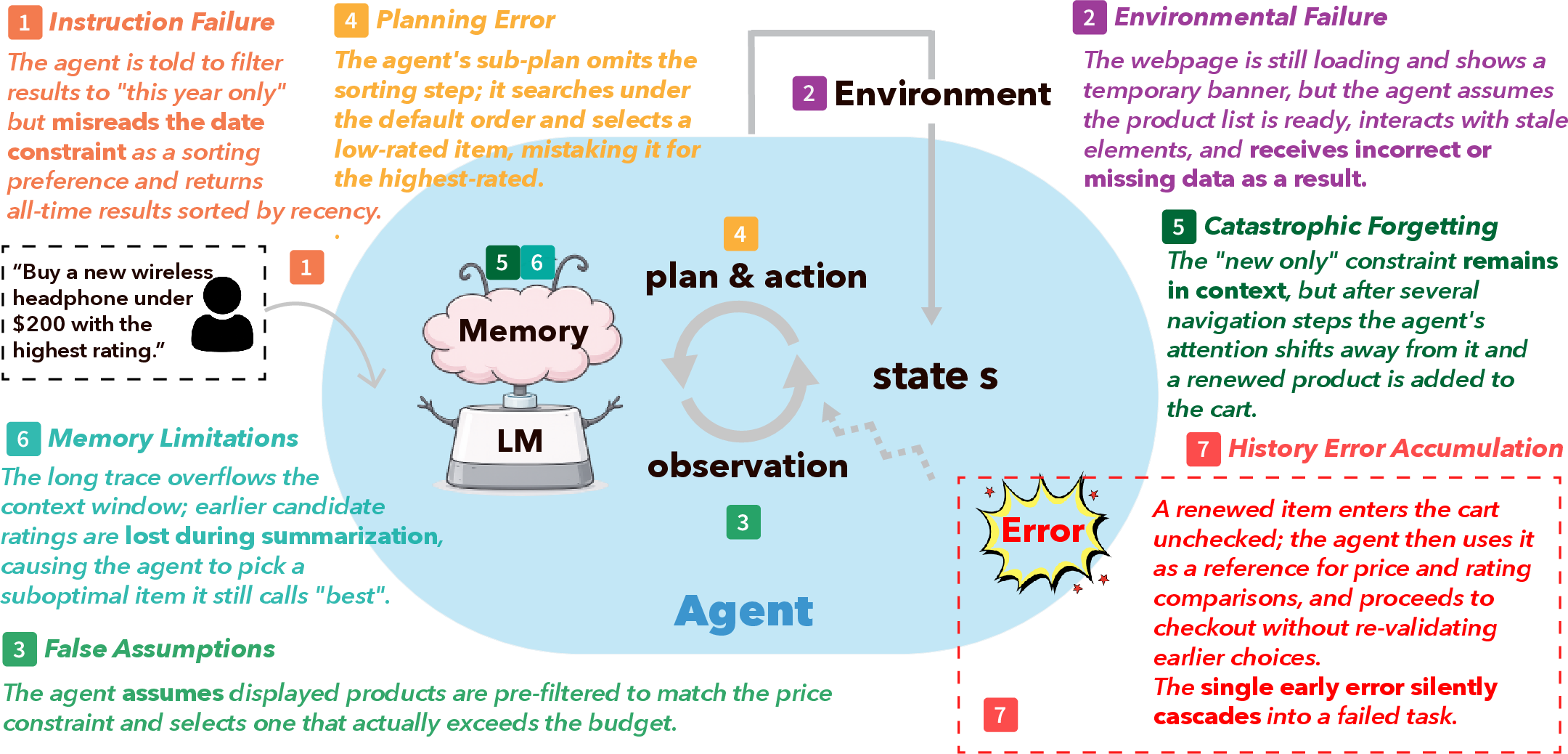
Figure 1: Illustration of agent execution and failure propagation, clarifying how failures compound across sequential execution stages in long-horizon rollouts.
Horizon Definition and Task Construction
A core contribution is a principled definition of “intrinsic horizon” (H∗), distinct from superficial metrics like episode length or interaction count. The benchmark enforces controlled task extension along two axes—compositional depth (nested goals/branching) and breadth (aggregation of independent subtasks)—with H∗ monotonically increasing and strictly agent-independent. The HORIZON protocol constructs domain-agnostic but structurally consistent horizon sweeps across Web, OS, Database, and Embodied manipulation tasks.
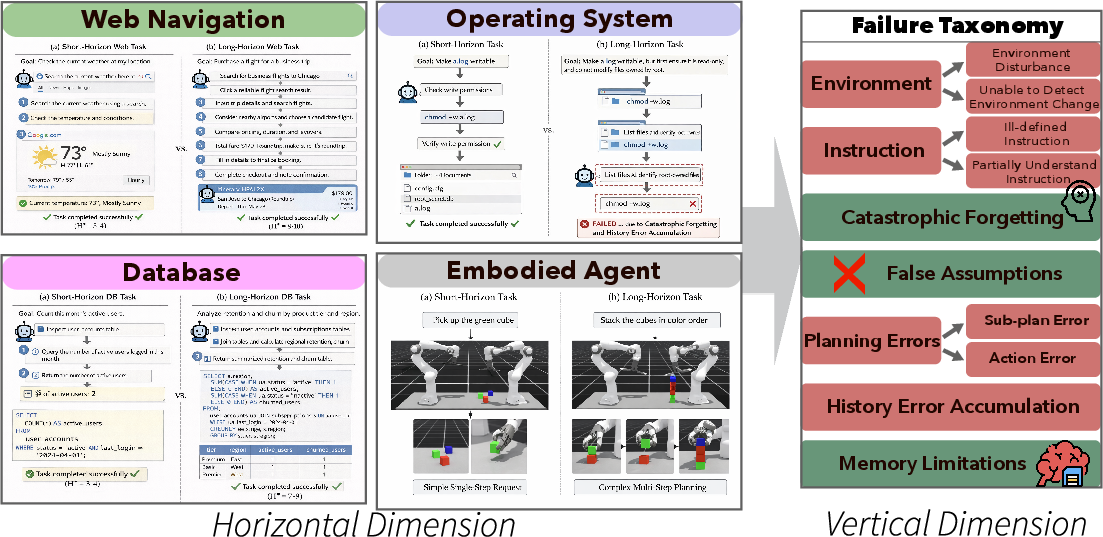
Figure 3: HORIZON overview, contrasting task-structure horizon growth (left) and structured seven-category failure taxonomy (right), mapped by locus-of-origin within the agent architecture and roll-out process.
Taxonomic Failure Attribution
The authors introduce a rigorously defined seven-category taxonomy for failure attribution, grounded in the FMEA hierarchy (Process- vs. Design-level). Categories include Environment, Instruction, Planning, False Assumption, Catastrophic Forgetting, History Error Accumulation, and Memory Limitation. Orthogonality is emphasized—failures are not mutually exclusive but reflect multiple compounding breakdowns per trajectory. Taxonomy creation involved both literature synthesis across domains and iterative human annotation procedures, validated by substantial inter-annotator agreement (Cohen κ=0.61; human–LLM-judge κ=0.84).

Figure 4: HORIZON diagnostic pipeline: unified horizon task construction, failure taxonomy design, LLM-based annotator calibration, and scalable trajectory-level failure labeling.
Empirical Findings: Where Do Agents Break?
Using >3100 agent rollouts across four domains (WebArena, AgentBench, MAC-SQL, IsaacSim), the authors show that both GPT-5-mini and Claude-4-Sonnet variants exhibit nonlinear and domain-dependent performance degradation as horizon (s) increases—maintaining near-optimal success rates across short and mid-range s before collapsing abruptly at domain-specific higher s values. Critically, post-collapse regions yield no further performance differential between models, strongly suggesting a qualitative rather than quantitative regime shift in agent failure.
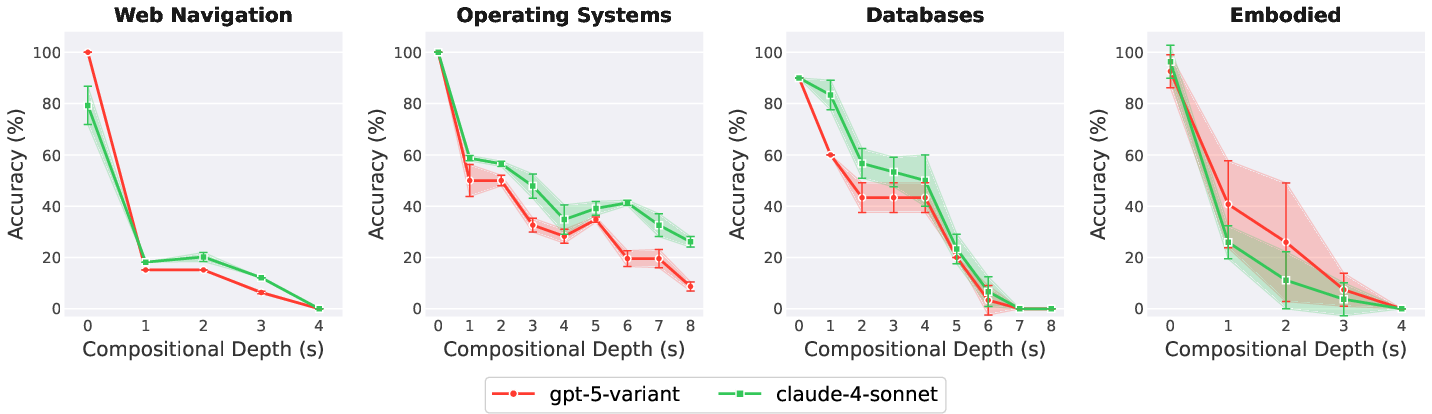
Figure 5: Model success rates as a function of compositional depth s, empirically showing abrupt, horizon-induced breakdowns and validating the HORIZON construction.
This pattern is domain-generic: embodied environments collapse at minimal s (reflecting precise, dependent action demands), Web tasks break at low-to-mid H∗0 (dynamic UIs, compounding context loss), and OS/Database tasks retain partial robustness until higher H∗1, reflecting greater procedural or symbolic resilience.
Failure Mode Distribution Across Domains
Detailed taxonomic analysis over failed rollouts demonstrates that process-level risks (planning error, environment, instruction, and history error) account for 72.5% of failures, while design-level risks (memory limitation, catastrophic forgetting, false assumptions) dominate the remainder (27.5%). Notably, planning errors become the overwhelming bottleneck in long-horizon Embodied and Database tasks, whereas Memory Limitation and Environment/Instruction failures are substantial in Web and OS domains.
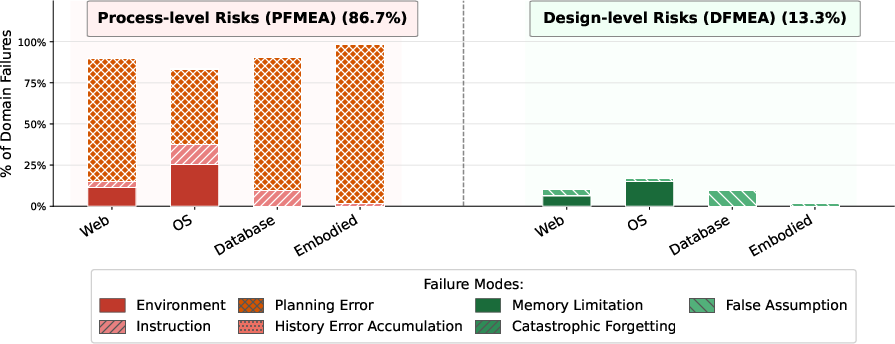
Figure 2: Distribution of failure types by domain, showing process/design dominance and substantiating the taxonomic framework’s explanatory power.
LLM-as-a-Judge for Failure Attribution
Given the scale and complexity of trajectory-level analysis, the authors validate a trajectory-grounded LLM-as-a-Judge pipeline, calibrated to the HORIZON taxonomy, and demonstrate high agreement rates against human expert annotation. This pipeline enables scalable, reproducible, and consistent failure labeling at scale, which the authors argue is indispensable for future large-benchmark agent research.
Implications for Agentic System Design and Evaluation
Structural, Not Merely Quantitative, Limits
The central claim supported by HORIZON analysis is that long-horizon failures are not extensions of short-horizon errors, but reflect qualitatively distinct bottlenecks in planning, memory, and constraint persistence. The data indicate additional scaling of model size or training length alone is insufficient for restoring reliability in high-H∗2 regimes, as models suffer catastrophic knowledge loss, subplanning defects, and context overflows. Specifically, early-stage planning deviations and missed constraint tracking lead to compounding, unrecoverable trajectory errors.
Benchmarking and Methodological Recommendations
HORIZON motivates a necessary methodological shift, advocating for benchmarks and evaluation pipelines that (1) operationalize horizon as an explicit, agent-independent axis, and (2) decouple “when” agents break (horizon) from “why” (failure type). The authors recommend that future benchmarks standardize horizon-aware metrics to allow meaningful cross-domain and cross-model diagnosis, as well as leveraging LLM-judge-based at-scale failure attribution to enable actionable progress.
Guidance for Agent Research and System Development
The actionable guidance emerging is twofold:
- Architectural innovation (robust hierarchical/planning modules, execution-time plan verification, explicit memory augmentation) is required to mitigate long-horizon breakdowns. Reliance on improved scaling/hardware/longer context windows does not address propagation and compounding of structural errors.
- Standardized, taxonomy-driven evaluation must inform intervention and ablation studies, moving beyond aggregate success rates to failure attribution and compositional horizon analysis.
Limitations, Contradictory Claims, and Real-World Mapping
While the absence of a universal, domain-agnostic horizon definition is acknowledged, the empirical evidence supports the claim that HORIZON’s construction yields valid, mechanistically grounded horizon regimes for comparative and diagnostic analysis. Further, by mapping taxonomy-defined failures to real-world agent incidents (e.g., OpenClaw), the framework demonstrates external relevance, capturing catastrophic forgetting, false assumption, and compounding history error phenomena observed in deployed AI systems.
Conclusion
This work provides a robust cross-domain framework for diagnosing and attributing long-horizon agentic failure, demonstrating HORIZON’s utility in surfacing critical design and methodology gaps in current agent evaluation practice. By foregrounding horizon-dependent breakdowns and their underlying compositional and architectural dependencies, the framework delineates a research agenda that prioritizes explicit planning, reliable memory, and systematic, standardized diagnostic instrumentation for agentic systems. This orientation will be necessary for any future advances toward sustained, reliable long-horizon autonomy in real-world AI deployment.