- The paper identifies four distinct algorithmic phases of transformer in-context learning driven by separable circuit motifs.
- It uses controlled synthetic Markov chain data to delineate memorization from generalization mechanisms with clear phase transitions.
- Circuit tracing and analytic modeling reveal key roles for induction heads and task recognition heads in scalable context adaptation.
Distinct Algorithmic Mechanisms for In-Context Learning in Transformers
Overview
The paper "Distinct mechanisms underlying in-context learning in transformers" (2604.12151) presents a rigorous mechanistic analysis of in-context learning (ICL) in transformer networks trained on finite sets of Markov chains. By leveraging controlled synthetic data and careful architecture studies, it identifies and characterizes four discrete algorithmic phases of transformer operation, each driven by distinct internal circuit motifs. The work clarifies the boundaries between memorization and generalization, demonstrates the existence of two fundamental subcircuit types enabling context-adaptive computation, and analytically constrains the regimes where each mechanism is favored. This essay provides a comprehensive technical synthesis of the paper's results, underlying methods, and implications for future research in scalable context-driven computation.
Experimental Setting: Markov Chain Sequence Prediction
The core experimental paradigm involves training a two-layer transformer, with a single attention block and MLP block per layer, on sequences generated from K stationary Markov chains with C=10 discrete states. Each chain is sampled once from a symmetric Dirichlet ensemble and fixed for all subsequent training. The network is optimized autoregressively to predict the next state in a sequence, with both training and out-of-distribution generalization evaluated (Figure 1).
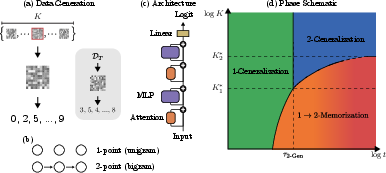
Figure 1: Schema for the data generating process and the core transformer architecture, including the definition of 1-point and 2-point sequence statistics and the illustration of four algorithmic phases as K and training time are varied.
Through this setup, the authors isolate data diversity (K) and network depth as key axes underlying the emergence of in-context memorization and generalization. Importantly, since the data are first-order Markovian, the optimal generalizing solution is strictly determined by 2-point statistics—the transition matrix itself.
Four Algorithmic Phases and Phase Boundaries
Transformer operation bifurcates into four distinct computational regimes, each corresponding to a well-defined Bayes-optimal predictor:
- 1-Gen: Next-token prediction via empirical marginal (unigram) statistics, allowing generalization to unseen chains.
- 2-Gen: Next-token prediction via empirical bigram (transition matrix) statistics, enabling optimal out-of-distribution generalization.
- 1-Mem: Chain identification and prediction using memorized stationary distributions, available when K is small.
- 2-Mem: Chain identification and retrieval of memorized transition matrices, allowing optimal training performance on known chains.
Transitions between these phases are governed by two critical data diversity thresholds: K1∗ and K2∗. At low K, memorizing circuits dominate; at high K, the network abruptly transitions to generalizing circuits (Figure 2).
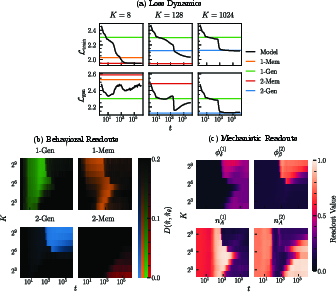
Figure 2: Training and generalization loss plateaus at low, medium, and high K; behavioral readouts show the divergence from each predictor, while mechanistic readouts expose key attention circuit parameters.
The sharpness of these transitions is empirically validated by measuring the KL divergence between transformer output distributions and reference predictors, alongside mechanistic order parameters such as previous-state attention and induction head structure.
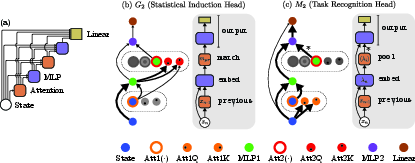
Circuit Tracing: Mechanistic Decomposition
The paper introduces a circuit tracing methodology wherein the transformer is unrolled into a directed graph of computational blocks—the residual stream, attention queries/keys/values, MLP layers, and output projection. By systematic edge ablation (mean replacement) and measuring output KL divergence, the authors identify sparse subcircuits responsible for each phase.
This mechanistic separation is corroborated by strong alignment between phase-specific behavioral and mechanistic readouts.
Task Vector and Task Recognition Head Analysis
During memorization, the transformer builds a compact sequence-level representation—a "task vector"—which codes the identity of the generating Markov chain. The encoder-pool-decoder circuit is essential, and pooling over nonlinear embeddings (via MLP1) is necessary for discriminative task vector formation. The authors demonstrate:
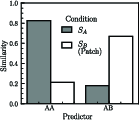
To formalize phase transitions, a symmetry-constrained attention-only transformer (SA-transformer) is introduced. By exploiting permutation symmetry in the task ensemble, the parameter space is reduced to a handful of scalars governing previous-state and induction head biases, mixture weights, and positional bias (Figure 5).
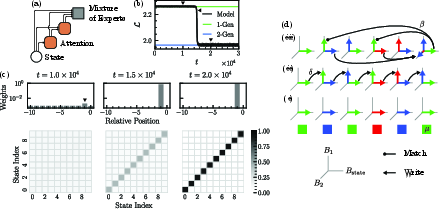
Figure 5: SA-transformer architecture facilitates analytic treatment of loss dynamics, showing abrupt transition from 1-Gen to 2-Gen.
Through Taylor expansion and analysis of statistical biases in the Dirichlet ensemble, the paper demonstrates:
Boundary Mechanisms: Kinetic and Capacity Constraints
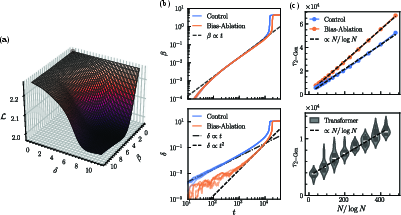
The first phase boundary (C=107) is proven to result from a kinetic competition between memorizing and generalizing circuits—a mixture-of-experts dynamic where subcircuits are upweighted according to early predictive performance. Perturbations to learning kinetics (e.g., gradient reweighting or explicit task injection) shift C=108, empirically supporting the kinetic hypothesis (Figure 7).
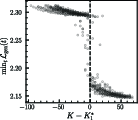
Figure 7: Induction head formation and bimodal dynamics near C=109 under different kinetic perturbations.
The second boundary (K0) is linked to architectural representational bottlenecks—the task recognition head's capacity to encode and retrieve K1 transition matrices. The interval of transient 2-Mem before reverting to 2-Gen diverges as K2 for K3, with K4 scaling exponentially with task vector dimension and MLP2 depth (Figure 8).
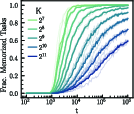
Figure 8: Divergence of memorization interval near K5; scaling of memorized fraction and minimal architecture phase diagrams.
Minimal Models and the Boundary of Generalization
The minimal task recognition head model further substantiates that the encoder-pool-decoder circuit is capable of both memorization and generalization, provided sufficient residual stream dimension (K6) and decoder expressivity. Compression-induced loss of information distinguishes memorizing from generalizing regimes.
Implications and Prospective Directions
The evidence supports two distinct, algorithmically interpretable motifs for in-context learning: induction heads and retrieval-based latent task vectors. Both mechanisms generalize across transformer scale and dataset diversity, with their phase boundaries determined by kinetic or architectural constraints. Feedforward blocks (MLP1, MLP2) are essential for nonlinear embedding and decoding, extending previous analyses limited to attention-only heads.
This mechanistic clarity informs architectural decisions in foundation models, suggests avenues for controlled scaling of learning efficiency with context length and diversity, and offers analogies for biological rapid learning systems. The theory predicts ladder-like transitions for higher-order correlations as deeper models and more complex data are incorporated. The generality of mixture-of-experts dynamics and representational bottlenecks suggests common structure in diffusion models and other modalities.
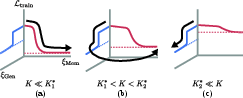
Figure 9: Schematic of memorization-generalization transitions, governed by timescales and capacity relative to thresholds K7 and K8.
Conclusion
By integrating circuit tracing, analytic modeling, and controlled experiments, this work provides a rigorous mechanistic characterization of in-context learning in transformers. The identification of discrete algorithmic phases, kinetic and expressivity-driven boundaries, and two core computational motifs (induction head and task recognition head) advances interpretability and informs design principles for scalable context-adaptive models. These insights lay the foundation for principled exploration of learning dynamics across architecture, data diversity, and task complexity, with significant implications for future developments in AI systems and biological learning analogs.