- The paper introduces CAPO, a novel algorithm that aligns policy gradients with calibration objectives for reasoning LLMs.
- It employs a logistic, AUC-consistent surrogate loss and noise masking to mitigate overconfidence and misranking in outputs.
- Empirical results show CAPO achieving up to 25% AUC improvement and enhanced accuracy on diverse mathematical reasoning benchmarks.
Motivation and Problem Statement
Model calibration, defined as the alignment between output confidence and ground-truth correctness, is critical for reliable decision-making in high-stakes scenarios and downstream algorithmic systems. Despite advances in Reinforcement Learning from Verifiable Rewards (RLVR) for reasoning LLMs, such as Group Relative Policy Optimization (GRPO) and Group Sequence Policy Optimization (GSPO), these methods induce substantial overconfidence, leading to degraded relative calibration. Specifically, incorrect generations can exhibit lower perplexity (higher confidence) than correct ones, with negative impact quantified by a lower Area Under the Curve (AUC) in ranking confidence scores.
Prior mitigation attempts have been largely heuristic and lack theoretical guarantees. They tend to trade modest calibration improvements for accuracy loss or vice versa. The paper "Calibration-Aware Policy Optimization for Reasoning LLMs" (2604.12632) systematically analyzes the root causes of calibration collapse in GRPO-style RL and proposes a principled algorithm—Calibration-Aware Policy Optimization (CAPO)—that aligns the policy gradient with calibration objectives.
Theoretical Analysis of Calibration Degradation
The authors present both empirical and theoretical evidence that GRPO-style policy optimization, with group-based reward-only advantage estimation, degrades relative calibration as measured by AUC, even as accuracy improves. The gradient analysis reveals that GRPO effectively applies an AUC-inconsistent surrogate loss: a linear difference in perplexity scores. This surrogate is unbounded and scale-sensitive, rendering optimization directions misaligned with true calibration (see Figure 1).
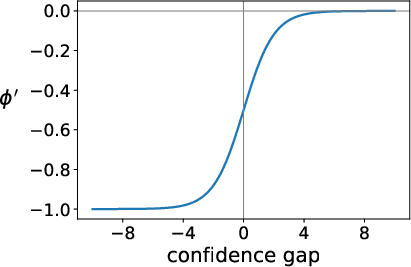
Figure 1: The relationship between advantage and the confidence gap of a correct–wrong response pair highlights the AUC misalignment in GRPO.
A formal derivation establishes that, since the reward-only surrogate does not respect the ordering property fundamental to AUC, GRPO overfits on samples with high reward regardless of confidence, sharpening the output distribution and causing incorrect responses to be ranked above correct ones. This pattern generalizes to all algorithms relying solely on reward-based advantage estimation.
CAPO: Algorithm and Surrogate Loss Design
CAPO addresses these deficiencies by employing a logistic AUC-consistent surrogate loss as the basis for advantage computation. This surrogate loss is convex, differentiable, and non-increasing, satisfying the necessary conditions for AUC consistency—ensuring that optimally minimizing the surrogate aligns with maximizing the true relative calibration.
In practice, CAPO computes uncertainty-aware advantages via pairwise gradients between correct and incorrect samples, weighted by the derivative of the logistic loss with respect to confidence differences. This mechanism prioritizes samples near the misranking boundary, which are most informative for calibration correction, and naturally suppresses influence from already well-separated pairs.
To further stabilize training, the authors introduce a reference-model-driven noise masking mechanism. Correct responses with unusually high reference-model perplexity and incorrect responses with unusually low perplexity are masked out from contributing to the gradient. This approach leverages the inherent calibration of the base model to denoise the RL signal without additional computation, filtering spurious or penalized reasoning paths.
Empirical Evaluation
Extensive experiments were conducted on Qwen2.5-Math-1.5B and 7B base models, over six mathematical reasoning benchmarks. Calibration (AUC-mean) and accuracy (mean@16) metrics were reported, along with precision-coverage curves for hallucination mitigation.
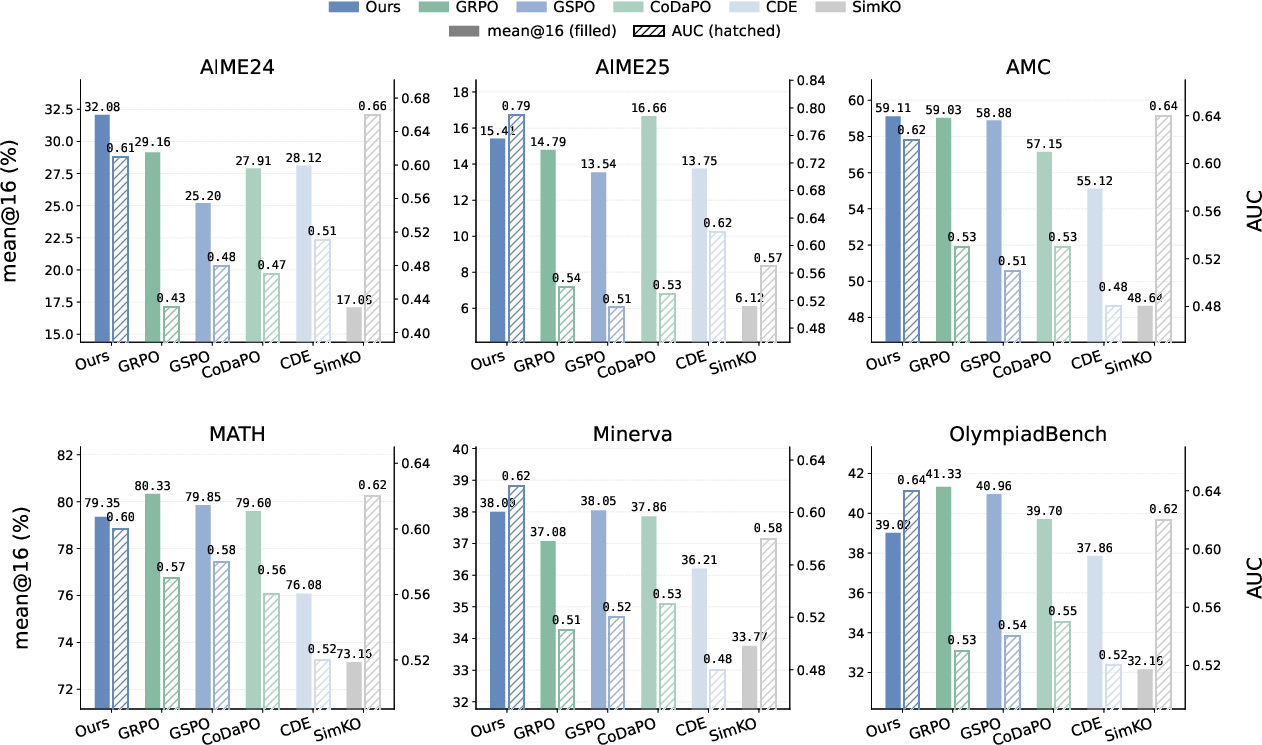
Figure 2: Results of calibration (AUC-mean) and accuracy (mean@16) for CAPO and baselines on Qwen2.5-Math-7B across six test benchmarks.
CAPO achieves up to 15% AUC improvement over GRPO in 1.5B-scale models and up to 25% improvement in 7B-scale models, with accuracy comparable to or exceeding GRPO, particularly on AIME 2024/2025 and Minerva datasets. Notably, methods like SimKO, while improving ranking, suffer sharp accuracy drops, underscoring the necessity of joint optimization.
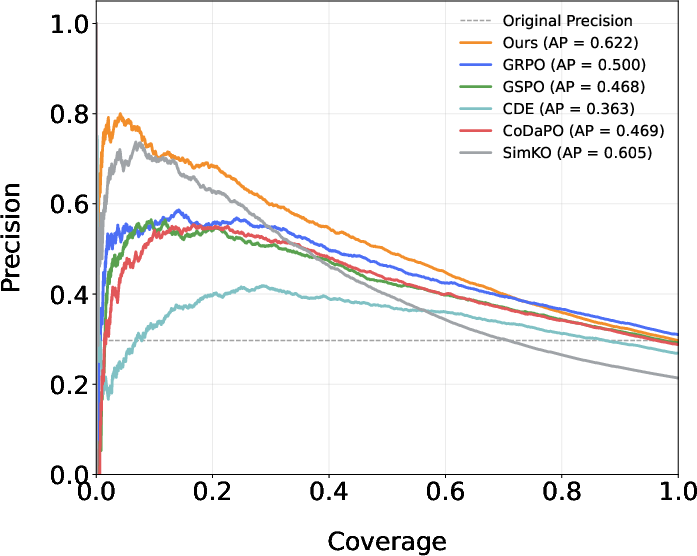
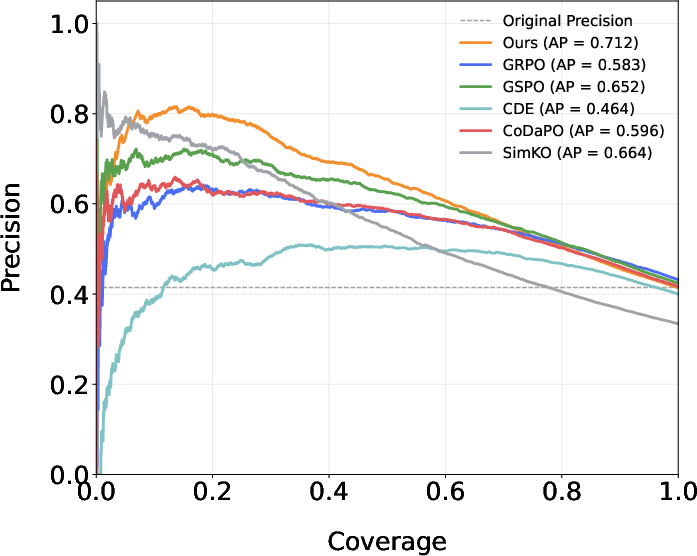
Figure 3: Precision-Coverage curves for CAPO and baselines on Qwen2.5-Math-1.5B (left) and 7B (right), demonstrating Pareto-optimal trade-offs for hallucination mitigation.
CAPO establishes a Pareto-optimal precision–coverage curve, outperforming GRPO and GSPO in reliable abstention scenarios, which is crucial for high-risk deployments. Moreover, when used in downstream inference-time scaling tasks, CAPO achieves up to 5% accuracy increment over GRPO, demonstrating improved utility of calibrated confidence scores for response aggregation.
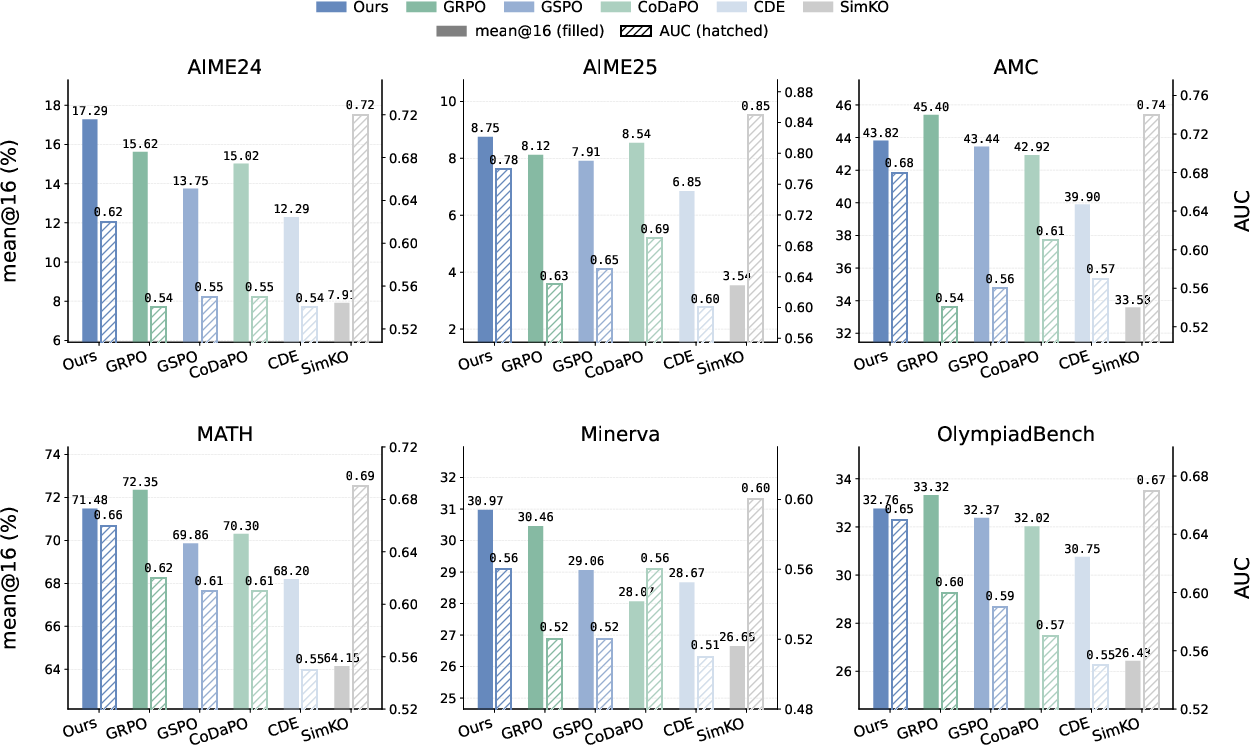
Figure 4: Results of calibration (AUC-mean) and accuracy (mean@16) for CAPO and baselines on Qwen2.5-Math-1.5B across six test benchmarks.
Algorithmic Stability and Ablation Studies
CAPO exhibits stable learning dynamics; calibration improves monotonically during training, unlike GRPO/GSPO, which undergo persistent calibration collapse. Hyperparameter ablation (e.g., surrogate temperature τ, masking thresholds) confirms robust performance, with the masking mechanism critical for preventing early entropy stagnation and maximizing accuracy gains.
Practical and Theoretical Implications
CAPO makes a strong case for theoretically grounded RL policy optimization in reasoning LLMs. The blend of consistent AUC surrogate and noise masking yields models that are both accurate and trustworthy, a duality difficult to achieve with prior methods. This paradigm will likely inform training objectives for broader reasoning tasks beyond mathematical QA, including logical inference, commonsense reasoning, and automated evaluation pipelines.
From a theoretical perspective, the work advances understanding of calibration failures in reward-based RL, clarifies surrogate loss design requirements, and demonstrates regret bounds on calibration-aware optimization. The practical implication is calibrated LLMs with reliable abstention and precision, significantly reducing hallucination risk.
Future Outlook
The proposed framework is extensible to more complex tasks—logical puzzles, commonsense, and open-domain QA—where calibration is equally essential. Integration of calibration-aware policy optimization with multi-agent reasoning, dynamic task routing, and self-consistency ensembles promises further gains in both performance and interpretability of LLMs. CAPO's design also provides a template for optimization objectives in RLHF settings where trustworthiness matters.
Conclusion
"Calibration-Aware Policy Optimization for Reasoning LLMs" delineates the theoretical limitations of reward-only RL objectives with respect to calibration and demonstrates a provably consistent alternative with strong empirical merit. CAPO jointly optimizes accuracy and calibration, resulting in enhanced precision, coverage, and downstream utility for reasoning LLMs. This approach sets an important precedent for principled objective design in RL-fine-tuned LLMs.