- The paper introduces a novel generalizable motion model that enhances monocular SLAM by integrating dynamic masks to refine pose estimation in real-time.
- It employs temporal attention and adaptive Otsu thresholding in dynamic tracking to suppress errors from motion distractors during mapping.
- Experimental results demonstrate improved localization accuracy and photorealistic 3D Gaussian map reconstruction in challenging dynamic scenarios.
GGD-SLAM: Monocular 3DGS SLAM Powered by a Generalizable Motion Model for Dynamic Environments
Introduction
Visual SLAM systems leveraging 3D Gaussian Splatting (3DGS) representations have demonstrated high-fidelity dense mapping capabilities for mobile robotics, AR/VR, and related domains. Nevertheless, legacy 3DGS-based SLAM architectures presuppose static environments, leading to significant performance collapse in dynamic contexts due to erroneous data associations and reconstruction artifacts. The "GGD-SLAM: Monocular 3DGS SLAM Powered by Generalizable Motion Model for Dynamic Environments" (2604.12837) introduces a generative framework that addresses these limitations with a temporally-aware, semantic-agnostic motion model—enhancing both localization and photorealistic dense reconstruction in real-world dynamic scenes, without requiring semantic labels or depth sensors.
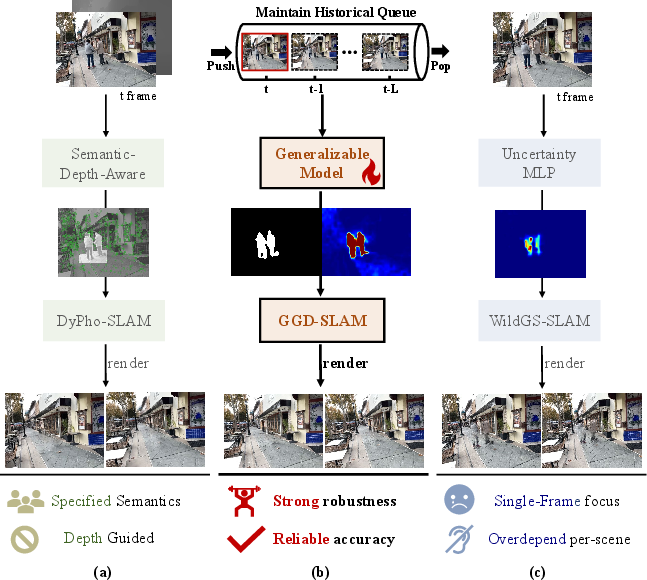
Figure 1: The motivation for GGD-SLAM—eliminating the dependency on per-scene 3DGS rendering loss supervision and semantic initialization, in contrast to prior methods.
System Architecture
The GGD-SLAM pipeline integrates a robust generalizable motion model (GMM), an online tracking module, and a photorealistic mapping module, forming an interconnected system for progressive SLAM operation.
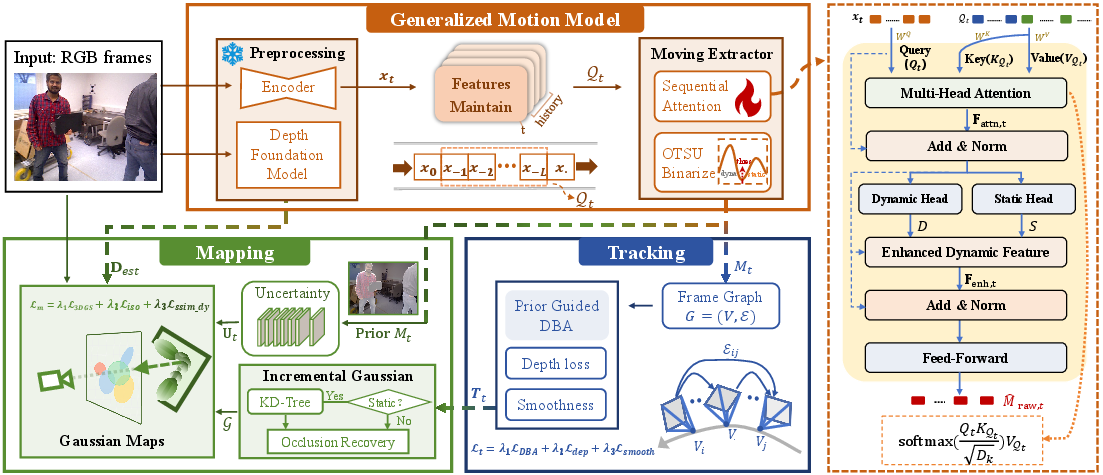
Figure 2: The GGD-SLAM pipeline incorporating the Generalized Motion Model (GMM), sequential attention dynamics prior, tracking, and dense mapping.
Generalizable Motion Model
Central to GGD-SLAM is the Generalizable Motion Model, trained to perform temporally-consistent dynamic semantics extraction over progressive monocular sequences. The GMM input comprises spatial features from DINOv2, which are aggregated into a FIFO queue to encapsulate temporal dynamics. A multi-head attention mechanism processes the spatiotemporal context across L frames, producing temporally-refined feature representations. Disentanglement into static and dynamic heads followed by gated fusion yields a per-pixel dynamic probability map. During inference, adaptive Otsu thresholding and morphological dilation refine these into binary dynamic masks, acting as domain-agnostic priors.
Dynamic Tracking
Tracking is executed via a DROID-SLAM-based dense bundle adjustment system, leveraging neural monocular depth estimates (e.g., Metric3D-v2) for scale-consistency. Importantly, the dynamic masks from the GMM are integrated as hard priors into the pose estimation and depth alignment objective. By modulating residual weights with the static mask complement, the approach eliminates bias from non-static regions, suppressing erroneous data associations caused by dynamic distractors.
Photorealistic Mapping
GGD-SLAM enhances 3DGS mapping through two principal innovations: (1) uncertainty-aware loss supervised by the GMM prior and (2) distractor-adaptive SSIM loss. The mapping objective incorporates Gaussian parameter optimization with explicit outlier suppression in dynamic regions, enforced by spatially-modulated uncertainty maps. To further prevent dynamic-distractor leakage, a distractor-adaptive SSIM kernel normalizes over valid static pixels per local region, yielding structurally coherent reconstructions in the presence of occluders and moving objects.
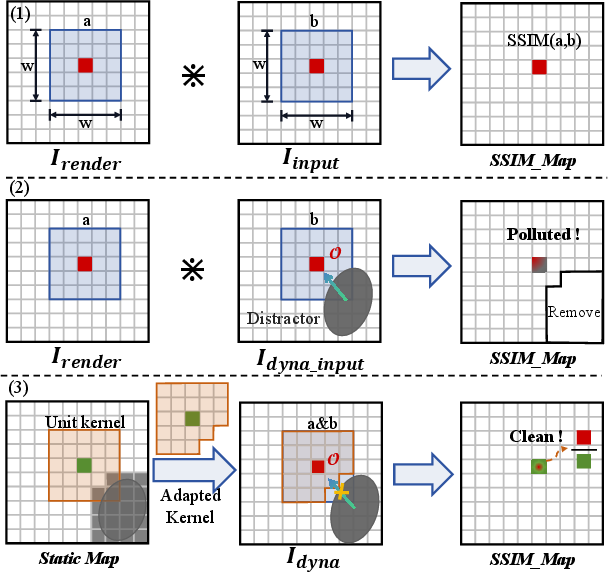
Figure 3: Distractor-adaptive SSIM: (1) Original SSIM; (2) Traditional dynamic scene contamination; (3) GGD-SLAM's adapted kernel excludes distractor artifacts, ensuring clean SSIM evaluation.
For occluded static background recovery, a KD-tree constructed from static 3D Gaussian parameters facilitates stochastic sampling to replace occluded regions, preserving geometric continuity and global map quality.
Experimental Evaluation
GGD-SLAM is extensively benchmarked on TUM RGB-D, Bonn RGB-D Dynamic, and Wild-SLAM datasets—comprising challenging real-world dynamic scenarios.
Dynamic Extraction and Ablation
Qualitative assessments illustrate that, unlike prior uncertainty-aware or scene-specific segmentation methods, the GMM reliably identifies long-lived and temporally-varying dynamic objects, including transiently static distractors.
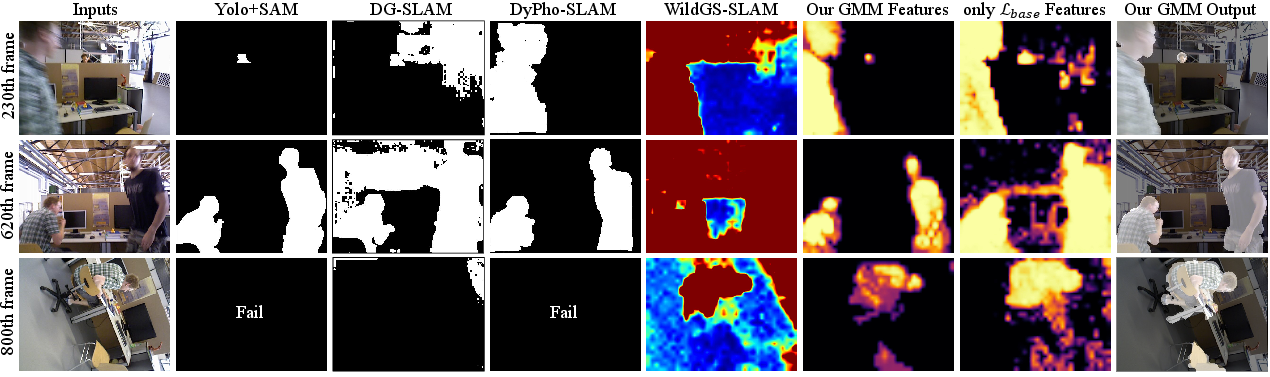
Figure 4: Comparison of progressive frame-wise dynamic extractor performance. GGD-SLAM's GMM produces consistent, low-noise dynamic masks over ambiguous, fast-motion, and edge cases.
An ablation study quantifies the importance of each SLAM module: (1) GMM prior integration, (2) adaptive binarization for clean mask edges, and (3) smoothness regularization during tracking—all shown to independently and collectively reduce ATE across dynamic benchmarks.
Camera Pose Tracking
Across TUM and Bonn—where ground-truth absolute trajectories support rigorous ATE/Std. validation—GGD-SLAM demonstrates superior or on-par tracking performance relative to state-of-the-art RGB-D and monocular systems. Notably, it achieves lower ATE on highly dynamic benchmarks (e.g., fr3/w/half, bonn/crowd2) compared to both monocular (WildGS-SLAM: 1.5cm, Ours: 1.4cm) and depth-enhanced SLAM approaches.
Dense Mapping Quality
In dense map evaluation, GGD-SLAM attains the highest PSNR and competitive SSIM/LPIPS among monocular 3DGS frameworks on all tested sequences, outperforming methods such as WildGS-SLAM (e.g., Ours: PSNR 22.68dB vs. WildGS-SLAM: 21.53dB on fr3/w/xyz), particularly in scenes corrupted by large-scale or ambiguous motion.

Figure 5: Comparison of rendered reconstructions across state-of-the-art Gaussian Splatting SLAM methods. GGD-SLAM successfully excises dynamic artifacts while preserving static structure fidelity.
Ablation results on the distractor-adaptive SSIM loss and KD-tree occlusion recovery demonstrate their additive contributions to PSNR by 0.7–0.5 dB increments, further substantiating their architectural indispensability.

Figure 6: GGD-SLAM on Wild-SLAM: Robust segmentation and high-fidelity rendering of dynamic, high-resolution, real-world scenarios.
Implications and Future Work
The GGD-SLAM paradigm marks a critical transition from per-scene, handcrafted, or semantic-label-dependent motion handling towards generalizable, temporally consistent, and fully self-supervised dynamic SLAM. By eliminating reliance on depth sensors, scene-specific tuning, and indirect learning of motion semantics from rendering artifacts, the solution enables robust, scalable deployment of monocular SLAM systems in unconstrained dynamic environments.
Practical implications extend to autonomous platforms, embodied agents, AR/VR real-time localization, and any deployment requiring persistent mapping in the presence of non-rigid foregrounds and occlusions. The incorporation of a dynamic motion prior into both optimization and reconstruction is theoretically extensible to other implicit or explicit SLAM systems. Future directions identified include real-time modeling of dynamic object trajectories, motion-inpainting for fully occluded regions, and lifelong static scene adaptation amidst persistent scene changes.
Conclusion
GGD-SLAM establishes a new state-of-the-art monocular 3DGS SLAM methodology for dynamic environments by introducing a temporally-generalizable motion prior, uncertainty-guided mapping, and distractor-adaptive losses. Quantitative and qualitative evidence demonstrates robust gains in localization and mapping under challenging real-world dynamics, bridging the gap between static-scene 3DGS paradigms and adaptive, deployment-ready SLAM in dynamic contexts.