- The paper demonstrates that the AI review system, using a multi-stage pipeline, significantly outperforms human reviews in technical accuracy and thoroughness, with notable error detection gains.
- The paper details a scalable architecture integrating LLMs, OCR, and tool-augmented reasoning to efficiently process nearly 23,000 submissions in under 24 hours at minimal cost.
- The paper validates the AI reviews through large-scale surveys and SPECS benchmark evaluations, highlighting complementary strengths and limitations that support a hybrid human-AI review model.
Comprehensive Analysis of AI-Assisted Peer Review: The AAAI-26 AI Review Pilot
Motivation for AI Integration in Peer Review
The exponential growth in scientific submissions places increasing burdens on traditional peer review workflows and threatens the sustainability of high-quality, timely evaluations. The AAAI-26 AI Review Pilot addresses this challenge by deploying AI-generated reviews systematically at a real conference scale, leveraging developments in LLMs and multimodal agents capable of rigorous critique and technical assessment. The pilot's fundamental question concerns whether frontier AI systems can offer actionable, accurate, and cost-effective reviews, and how their performance compares quantitatively and qualitatively to human reviewers under operational constraints.
Architecture and Operation of the AI Review System
The review system employed at AAAI-26 comprises a multi-stage pipeline integrating LLMs, OCR-based PDF conversion, tool-augmented reasoning, and iterative self-critique. The pipeline explicitly targets five scientific review criteria: story formulation, presentation clarity, evaluation sufficiency, correctness, and significance. Staged decomposition of review tasks enables specialized assessment per criterion and facilitates intermediate reasoning. The inclusion of Python code interpretation and web search enhances the system's ability to verify mathematical details and contextualize contributions within the literature.
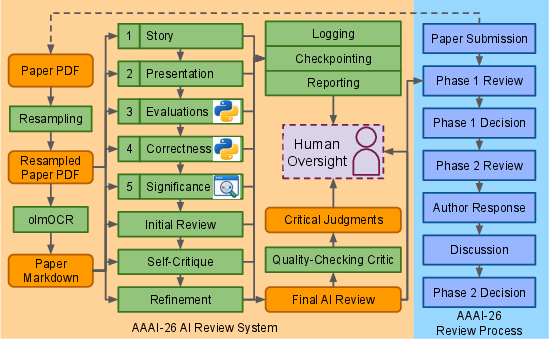
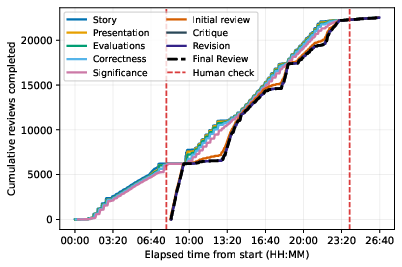
Figure 1: The AAAI-26 AI review system processes each submission through five specialized core stages, integrating multimodal inputs and tool-use, culminating in a structured, self-critiqued final review.
Operationally, the system processed 22,977 main-track submissions in under 24 hours at less than \$1 per paper. All reviews were generated double-blind and included clear labeling to distinguish AI involvement. No human reviewers were replaced; AI reviews served as an additional, supplemental input to the decision-making workflow.
Quantitative and Qualitative Evaluation
A large-scale survey (5,834 responses across authors, PC, SPC, and ACs) robustly evaluated the AI reviews. Respondents rated AI reviews statistically higher than human reviews in six out of nine quality dimensions (all differences p<0.01): technical error identification (+0.67), novel point detection (+0.61), presentation and research suggestions (+0.54, +0.49), and overall thoroughness (+0.48). Respondents did note that AI reviews overemphasized minor issues (−0.38) and contained modestly elevated rates of their own technical errors (−0.22).
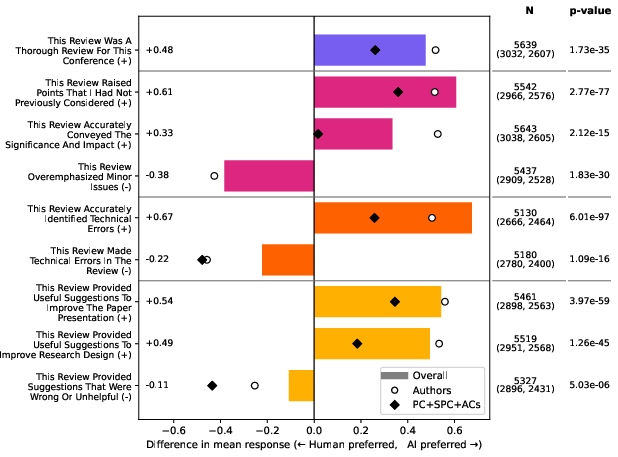
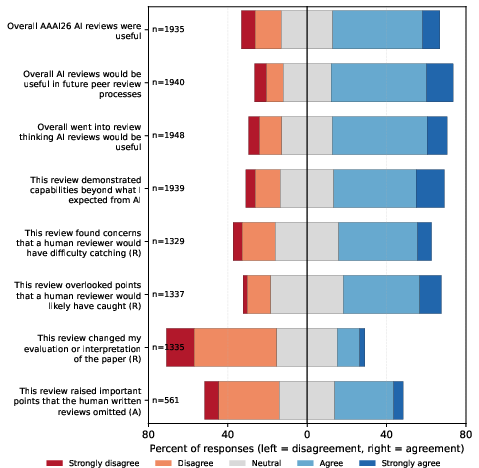
Figure 2: Survey results indicate AI reviews outperform human reviews in technical accuracy, thoroughness, and suggestion quality; respondents express strong support for AI review utility and future applicability.
Complementarity was evident: reviewers acknowledged that AI reviews flagged concerns difficult for humans while occasionally missing context-dependent subtleties. Free-form feedback revealed positive themes such as actionable revision guidance, breadth and thorough analysis, and objective presentation polishing. Negative themes highlighted weak judgment of significance/impact, nitpicking, verbosity, factual errors, and domain-context gaps.
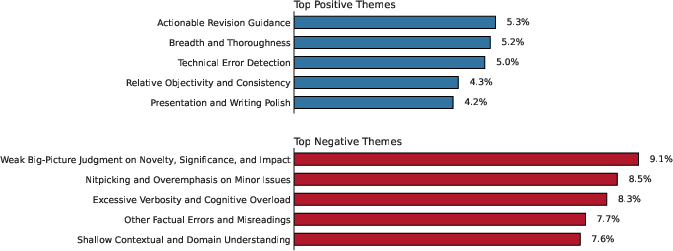
Figure 3: The most frequently cited positive and negative feedback themes reflect the systematic strengths and contextual limitations of the AAAI-26 AI Review Pilot.
Benchmarking Scientific Error Detection: The SPECS Review Benchmark
To rigorously assess scientific review detection capabilities, the SPECS benchmark was constructed. This benchmark synthesizes errors—across story, presentation, evaluation, correctness, and significance—within accepted papers, and evaluates review-stage recall using both baseline prompting and the AAAI-26 system.
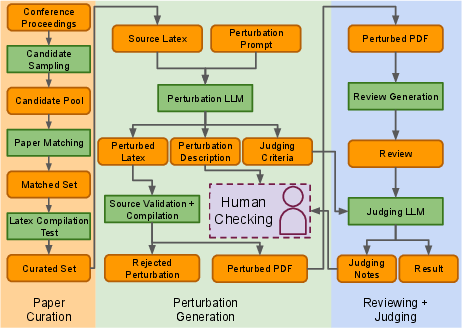
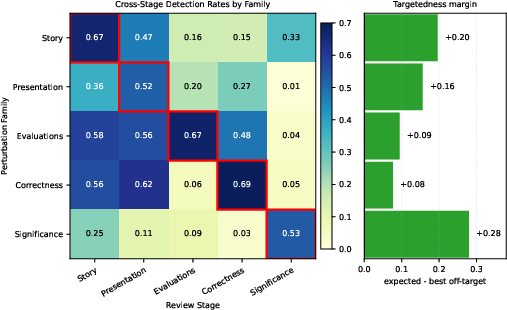
Figure 4: The SPECS benchmark curation process systematically samples and perturbs proceedings papers to synthesize domain-relevant errors for criterion-specific evaluation.
Results demonstrate that the AAAI-26 system significantly outperforms base LLMs in error recall for all review criteria (p<0.01 for all but correctness; aggregate gain +0.21). The final system achieves recall rates of 0.67 (story), 0.57 (presentation), 0.75 (evaluation), 0.76 (correctness), and 0.45 (significance), with notable improvements over single-pass baseline prompting.
Practical and Theoretical Implications
The operational feasibility, cost-effectiveness, and statistical superiority of AI-generated reviews substantiate their viability in conference-scale peer review. The capacity for rapid, impartial, technically rigorous reviews offers immediate relief for strained reviewer pools and may support broader participation from underrepresented domains. However, limitations in contextual judgment, prioritization of significance, and domain adaptation underscore the ongoing indispensability of human expert reviewers.
Theoretically, the pilot suggests a synergistic model—leveraging AI for exhaustive, objective technical scrutiny while reserving nuanced, contextual evaluations for humans. Benchmarking frameworks and staged review pipelines advance methodological rigor in AI review research and lay the foundation for future dual-agent reviewer architectures integrating adaptive models and domain-specialized expert systems.
AI reviews are poised for further improvement, driven by advances in context window extension, domain fine-tuning, and hybrid reasoning frameworks. Prospective developments include meta-reviewer agents, context-aware significance assessment, and customizable review-length control.
Conclusion
The AAAI-26 AI Review Pilot establishes that AI-generated reviews are not only feasible but statistically preferred in key metrics at conference scale. The multi-stage LLM pipeline achieves significant gains in scientific error detection and actionable revision feedback. Survey responses and benchmark analyses highlight both complementary strengths and current limitations. Future peer review is likely to incorporate synergistic human-AI teams, leveraging algorithmic thoroughness and impartiality while preserving expert contextual judgment and innovation assessment.