- The paper presents an adaptive multi-agent pipeline that dynamically co-evolves planning and coding to improve automated code generation.
- The paper utilizes collaborative decision-making and persistent reasoning trajectories to aggregate diagnostic history for targeted refinements.
- The paper demonstrates superior accuracy and efficiency on program synthesis benchmarks, reducing inference costs by up to 57% compared to baselines.
CollabCoder: Plan-Code Co-Evolution via Collaborative Multi-Agent Decision-Making for Code Generation
Motivation and Context
Automated program synthesis tasks have rapidly evolved with the proliferation of LLMs, yet correctness and efficiency for complex requirements remain significant bottlenecks. Existing multi-agent frameworks frequently adopt static planning and isolated debugging strategies, yielding marginal effectiveness and excessive inference cost. CollabCoder (2604.13946) introduces a fundamentally adaptive pipeline, characterized by dynamic plan-code co-evolution, collaborative decision-making, and persistent reasoning trajectory accumulation.
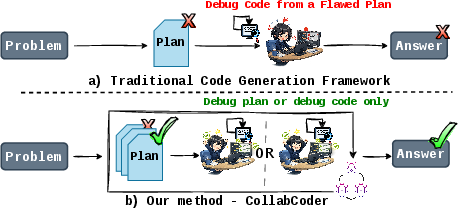
Figure 1: Overview contrasting static plan-driven generation with CollabCoder’s collaborative, continuously revised planning and code refinement.
Framework Architecture
CollabCoder consists of three core interacting agents: Dynamic Planning Agent ($\mathcal{A}_{\text{plan}$), Adaptive Coding Agent ($\mathcal{A}_{\text{code}$), and Collaborative Debug Agent ($\mathcal{A}_{\text{debug}$), tightly integrated through shared execution state. The debug agent is further decomposed into Collaborative Decision-Making (CDM), which determines whether plan or code should be updated, and a Reasoning Trajectory (RT) module, which aggregates diagnostic history for self-improving iterative refinement.
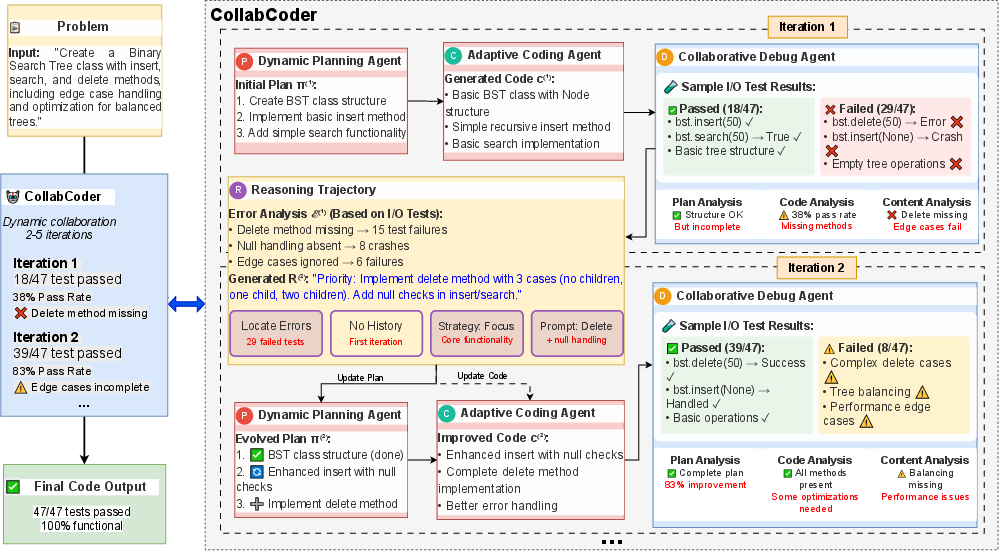
Figure 2: CollabCoder’s multi-agent architecture, detailing co-evolutionary feedback loops, CDM, RT accumulation, and adaptive debugging.
The collaborative process is orchestrated as follows:
- At each iteration, the execution oracle evaluates generated code on hidden test cases, producing a failure log.
- CDM aggregates plan-level, code-level, and plan-code alignment analyses to compute consensus for refinement direction, weighted by inter-module trust coefficients.
- RT maintains a persistent reasoning state R(t), guiding subsequent refinements by synthesizing historical failures and corrective actions.
The iterative loop is sustained until all test cases pass or a fixed iteration budget is exhausted, with plan and code mutually evolving according to adaptive debugging signals.
Methodology: Collaborative Decision-Making and Reasoning Trajectory
CDM employs three complementary analyses:
- Plan-level analysis: Diagnoses algorithmic misalignment.
- Code-level analysis: Localizes implementation errors.
- Plan-code alignment: Assesses semantic consistency.
Each analysis yields confidence scores; consensus is formed via weighted aggregation, balancing plan vs. code update rates according to observed error prevalence and backbone LLM capability.
RT differentiates CollabCoder from stateless iterative frameworks by encoding debugging history. This enables avoidance of previously ineffective fixes, enhances convergence, and generates structured reasoning paths. Updates leverage signals from both historical context and current diagnostic evidence, resulting in more targeted plan/code revisions.
Empirical Results
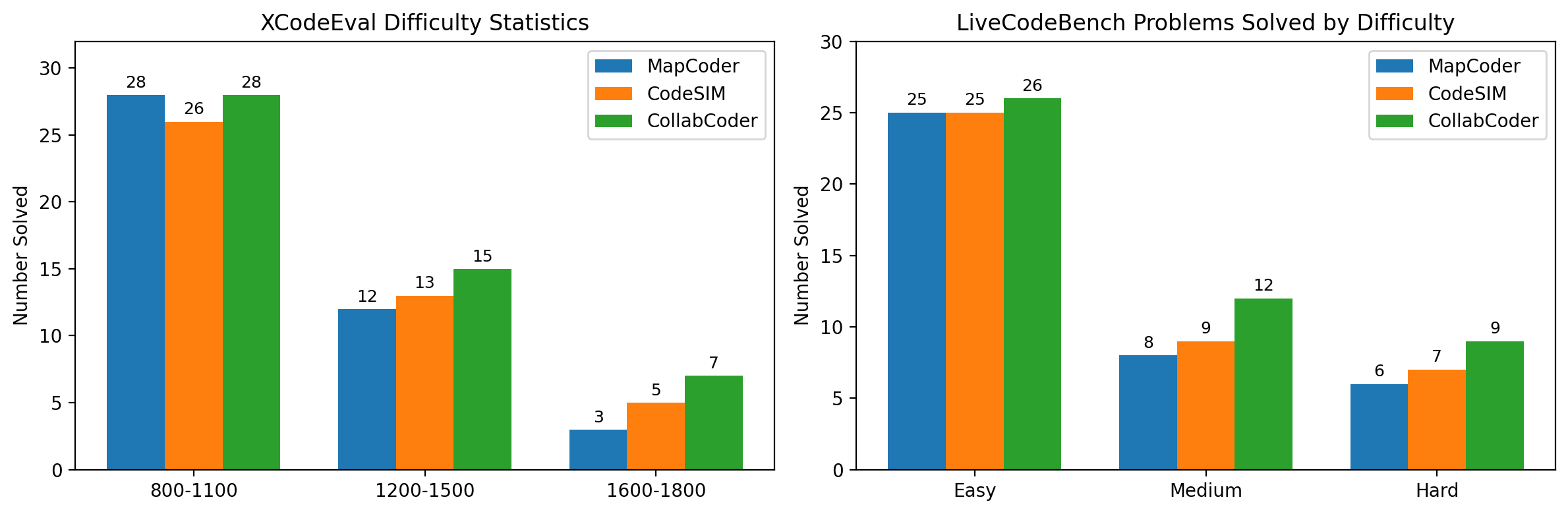
CollabCoder is extensively evaluated on standard program synthesis benchmarks (HumanEval, MBPP), their extended variants, and complex contest-level benchmarks (LiveCodeBench, xCodeEval). Experiments utilize a spectrum of backbone LLMs: Seed-Coder-8B, Qwen2.5-Coder-32B, GPT-4o mini, GPT-5.2, and Qwen3-Coder-Next.
Performance metrics include Pass@1 accuracy, token input/output efficiency, and average number of API calls.
CollabCoder’s superiority in complex tasks is maintained even on frontier backbones (GPT-5.2, Qwen3-Coder-Next). The accuracy gap is reduced as backbone capability increases, indicating a ceiling effect, but CollabCoder retains efficiency advantages and the highest Pass@1 scores.
Adaptive Debugging and Budget Efficiency
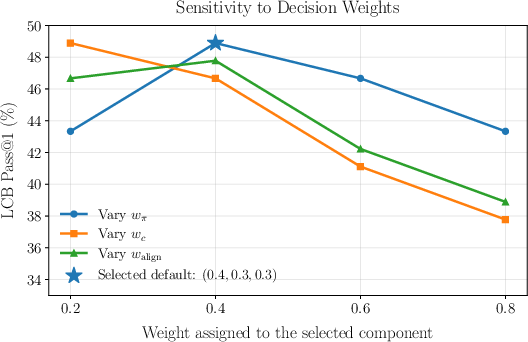
Analysis of iterative debugging strategies demonstrates CollabCoder’s efficacy in low-inference regimes.
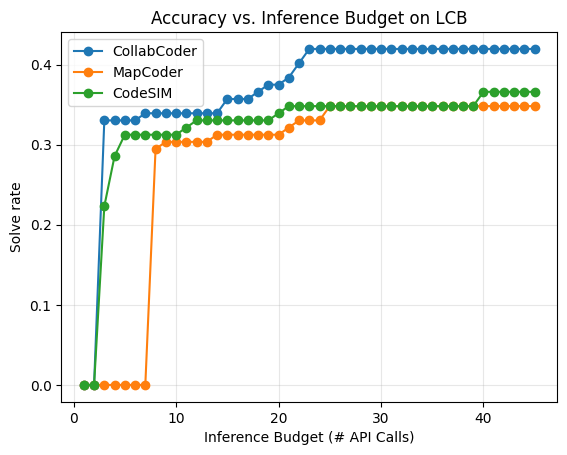
Figure 4: CollabCoder’s accuracy vs. inference budget curve on LiveCodeBench; marked efficiency in low-budget contexts.
CollabCoder outperforms MapCoder and CodeSIM by 2–3 percentage points with only 10 API calls. Unlike best-of-N sampling and Reflexion, which plateau early, CollabCoder yields continuous performance improvements across iterations, attributed to its structured plan-code co-evolution and explicit escape from strategic local minima.

Figure 5: Self-improving debugging example, showing iterative plan repair and code refinement.
Decision-Making Dynamics: Plan vs. Code Updates
CDM’s update behavior is analyzed across datasets and backbone models.
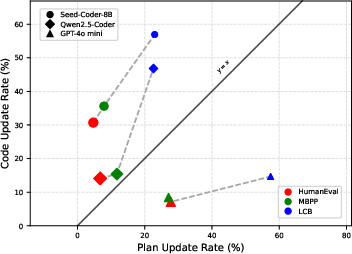
Figure 6: Visualization of plan and code update rates; plan-level updates are more frequent in general-purpose LLMs, code-heavy models favor code-level refinement.
Ablation and Component Contribution
Ablation studies reveal the significance of both CDM and RT modules. Removal of either reduces performance by 3–5 percentage points on average, with CDM having greater impact. The joint use of both modules enhances robustness and exploits backbone LLM capacity more effectively.
Practical and Theoretical Implications
CollabCoder advances the state-of-the-art in collaborative, agentic code generation. Its adaptive architecture reduces inference resource demands, curbs trial-and-error redundancy, and delivers improved correctness for both standard and competitive tasks. The framework establishes a formal paradigm for coordinated agentic reasoning, integrating diagnostic signals for principled error correction rather than solely patching code artifacts.
Theoretical implications include the empirical validation of collaborative decision-making as an optimization mechanism for escaping local minima arising from poor plan initialization. Persistent reasoning trajectory accumulation resembles reinforcement learning paradigms, enabling dynamic policy adjustment based on accumulated feedback.
Practical applications extend to autonomous software engineering platforms, competitive coding assistants, and complex real-world synthesis domains, where adaptive plan-code co-evolution confers robustness and computational efficiency.
Future Research Directions
Future development may enhance semantic plan-specification alignment, incorporate formal verification for correctness guarantees, generalize to multi-modal programming tasks, and adapt CollabCoder to low-resource backbone models. Extending collaborative agentic pipelines beyond code generation to broader task domains (e.g., mathematical theorem proving, data engineering) is a promising direction.
Conclusion
CollabCoder (2604.13946) introduces a comprehensive framework for adaptive, collaborative code generation via plan-code co-evolution. By leveraging collaborative decision-making and persistent reasoning trajectory, it achieves higher accuracy, efficiency, and robustness compared to static and iterative agent baselines, across a diverse spectrum of tasks and backbone LLMs. Its principled agentic design addresses fundamental limitations of isolated strategies and provides a scalable foundation for next-generation collaborative AI systems in software development.