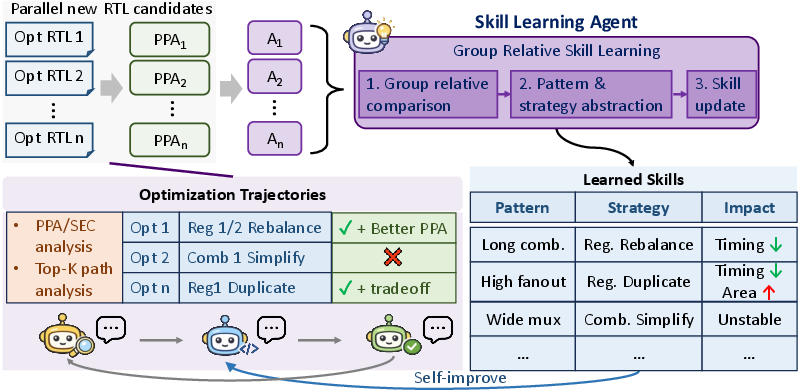
- The paper presents a closed-loop, multi-agent framework that integrates industrial EDA tools to optimize RTL designs.
- It uses group-relative skill learning to extract and reuse optimization patterns, yielding 21% timing and 6% area improvements.
- Empirical results on complex, human-authored RTL designs confirm robust SEC compliance and outperform traditional heuristics.
Motivation and Problem Context
Performance, power, and area (PPA) optimization at the register-transfer level (RTL) is a critical challenge in digital integrated circuit (IC) design. Human-engineered RTL codes represent the interface between architectural specification and hardware implementation, with the quality of such RTL dictating the ultimate PPA bounds achievable by downstream logic synthesis and physical design tools. While synthesis tools perform significant logic optimizations under strict architectural constraints, they inherently lack the semantic flexibility to restructure higher-level RTL constructs, limiting post-synthesis improvements. Manual RTL optimization, still the industry standard for non-trivial PPA gains, is labor-intensive, expertise-dependent, and explores a negligible fraction of the large, highly non-convex RTL design space.
Despite advances in utilizing LLMs for hardware generation and optimization, prior works targeting RTL improvement have suffered from unrealistic benchmarks (manually degraded designs), weak open-source toolchains (e.g., Yosys), simplistic optimization heuristics (pre-defined rules, design-level feedback), and a lack of scalable, interpretable knowledge extraction. These approaches fail to reflect the requirements and complexity of industrial-scale RTL timing closure.
Dr. RTL Framework and Design
Dr. RTL provides a closed-loop, agentic framework for realistic RTL optimization, integrating industrial EDA tools, multi-agent cooperation, and self-improving, interpretable skill learning.
The methodology unfolds as follows:
- Industrial-Standard Evaluation Loop: Unlike previous works, Dr. RTL evaluates on large, human-written RTL from real open-source projects, synthesizes using commercial tools (Synopsys Design Compiler), and enforces correctness via sequential equivalence checking (Cadence Jasper SEC). This architecture supports both combinational and sequential optimizations and is agnostic to the synthesis backend.
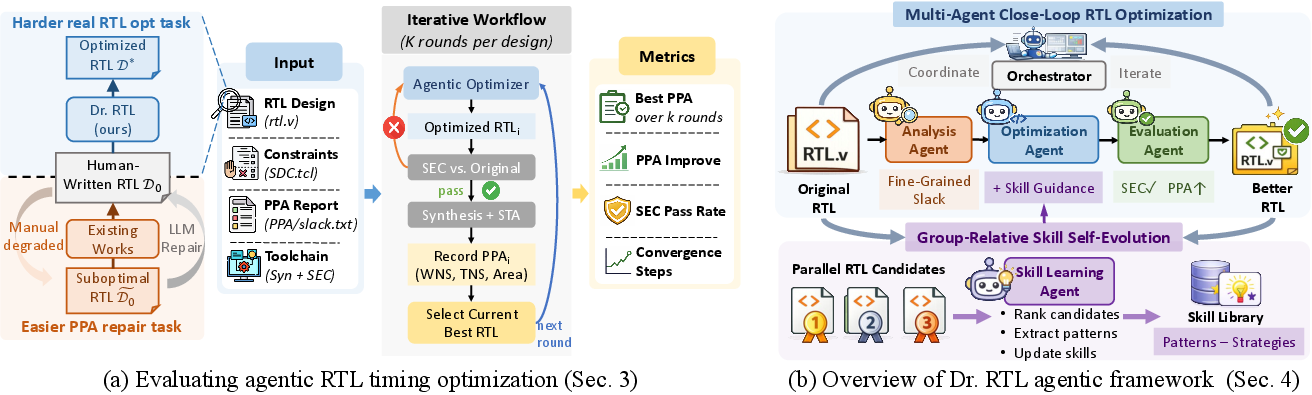
Figure 1: Dr. RTL consists of an industrial-standard evaluation workflow tightly coupled with an agentic optimization process.
- Multi-Agent Coordination and Feedback Grounding: The agentic framework decomposes the optimization process into three specialized agents—timing analysis, RTL optimization, and EDA evaluation—under a top-level orchestrator. Each agent exposes modularity, parallelism, and explicit alignment with the actual VLSI design flow.
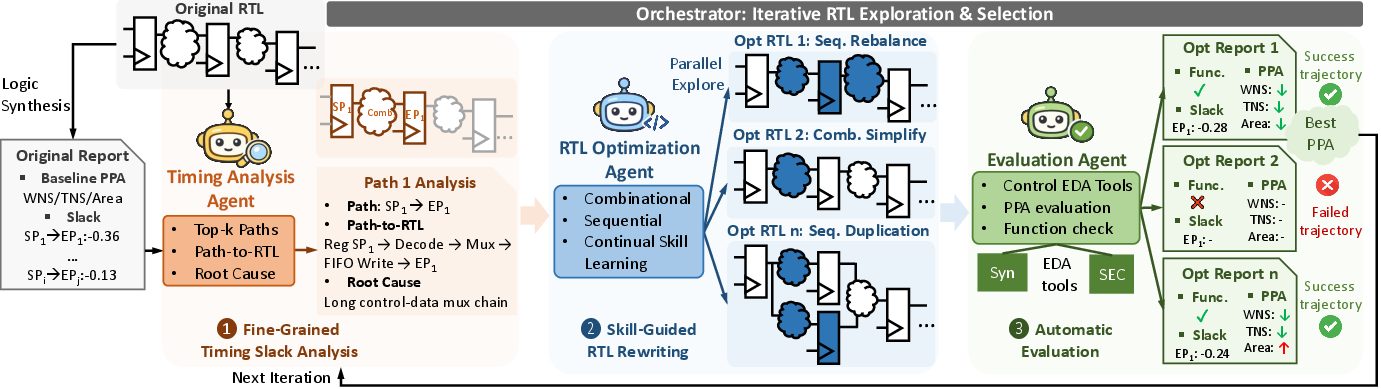
Figure 2: The multi-agent structure localizes critical paths, generates parallel candidates, and selects the optimal SEC-passing design with PPA improvement.
The orchestrator iteratively interacts with the agents using structured state logs, guiding exploration via fine-grained timing slack and path reports, monitoring transformations for SEC compliance, and tracking improvement via a normalized, weighted timing/area score.
Empirical Evaluation
The framework is validated on 20 complex, human-authored RTL designs, averaging an order-of-magnitude increase in size and hierarchy compared to previous benchmarks. Dr. RTL achieves average WNS/TNS improvements of 21%/17% and a 6% area reduction compared to commercial synthesis. These improvements are robust—86% average SEC pass rate—and achieved with modest LLM inference cost and efficient parallel EDA runs.
Notable results include consistent timing improvement across a broad design corpus—even when starting from strong, industry-grade RTL rather than artificially degraded baselines. Several designs exhibit Pareto PPA improvements, demonstrating structural RTL optimizations, not mere area-for-timing exchange.
Optimization trajectory visualization confirms that the skill-enhanced variant converges faster and achieves better final PPA than the variant without skill learning.
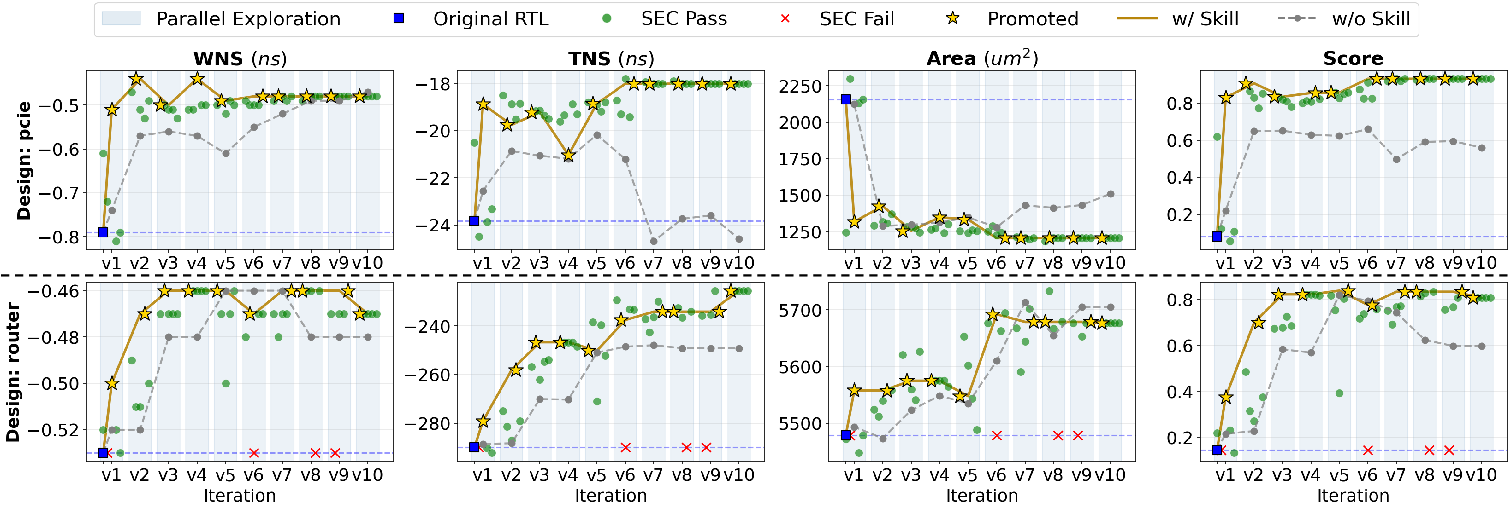
Figure 4: Skill-enhanced Dr. RTL demonstrates improved PPA convergence and solution quality.
Ablation experiments establish the significance of each component: register-level timing feedback is critical (reductions to summary timing feedback halve the timing improvement); the multi-agent decomposition and learned skill library each provide substantial advantages in search quality and validity.
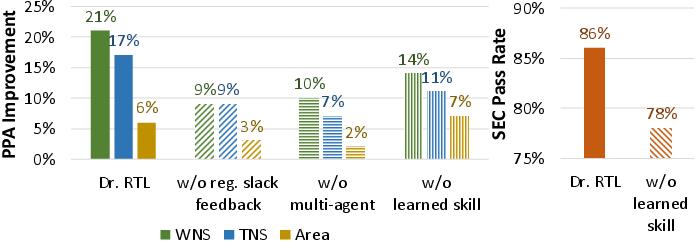
Figure 5: Removal of fine-grained feedback or reusable skills substantially reduces observed improvement and reliability.
Further, the hierarchical logging and skill hierarchy (pattern–strategy–template) enable interpretable, confidence-ranked reuse, with 47 skills extracted—spanning high-confidence structural optimization strategies to known invalid approaches suppressed in search.
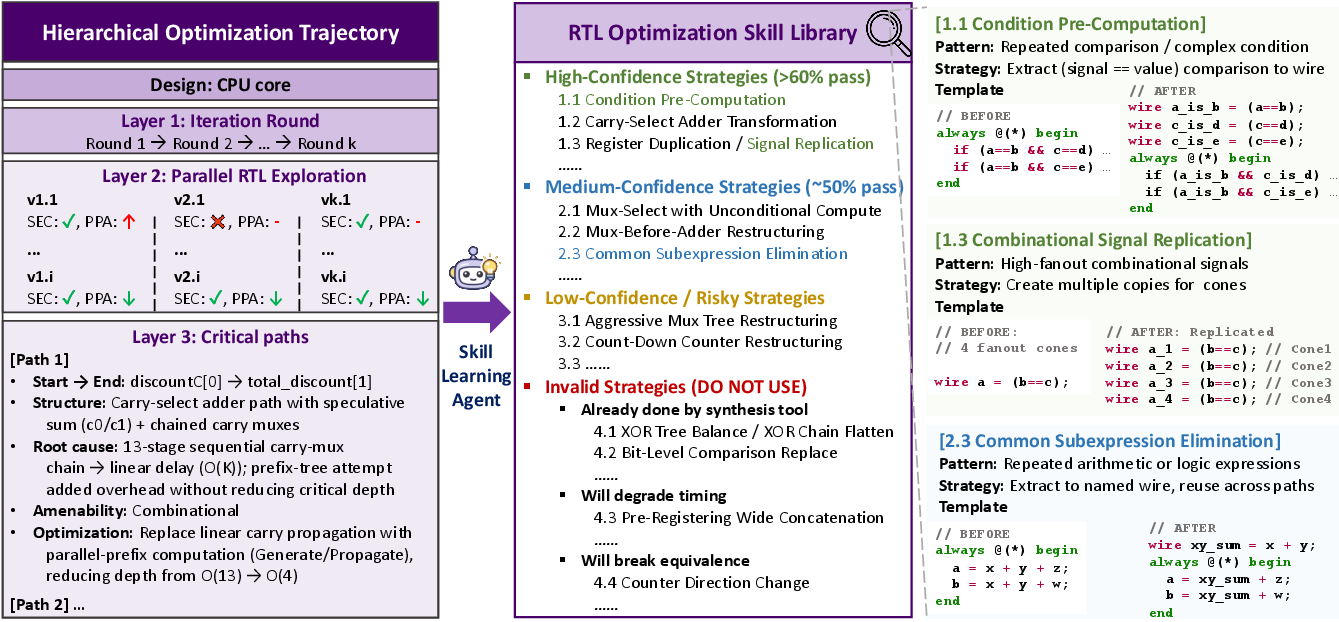
Figure 6: Hierarchical trajectory distillation yields an organized library of cross-design skill abstractions for online reuse.
Generality and Scaling Analyses
Dr. RTL is LLM-model-agnostic. Experiments show timing/SEC improvement scales monotonically with underlying LLM capability (from Qwen Coder 8B to Claude Opus). The framework is also EDA-backend-agnostic: it achieves timing improvement across open-source Yosys, commercial synthesis, and post-route flows, confirming that discovered optimizations reflect RTL-level opportunity, not tool-specific artifacts.
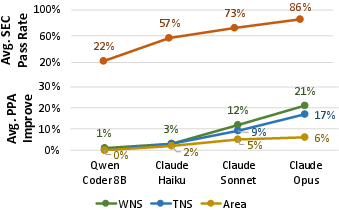
Figure 7: PPA gains scale with the underlying LLM's reasoning capability.
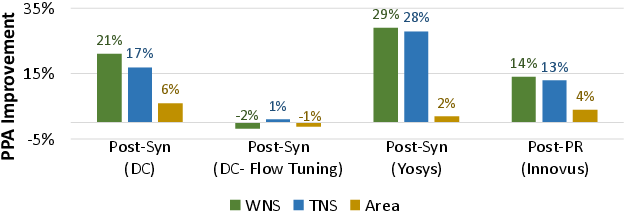
Figure 8: Timing improvement generalizes across synthesis and P&R flows, indicating true RTL transformation benefit.
Implications and Future Directions
Dr. RTL establishes the practicality of an agentic, tool-grounded paradigm in RTL optimization, demonstrating that systematic search paired with interpretable, evolving knowledge can meaningfully supersede advanced EDA tools. Unlike reinforcement learning schemes with opaque rewards or purely black-box search, the group-relative skill learning yields explicit, reusable knowledge for designers and future agent instantiations. The modular agentic approach also enables extensibility to power/performance-driven objectives, deeper integration at the design space exploration or floorplanning stage, or hybrid human–agent co-optimization.
This approach also signals that further embedding of domain-grounded, agentic RL (or skill RL) techniques in hardware design flows could systematically unlock cross-design synergies and reduce dependency on manual, high-expertise refinement. With expected advances in domain-specialized LLMs, increased parallel EDA tool efficiency, and richer online skill transfer, agentic RTL optimization is poised to significantly impact practical hardware design workflows.
Conclusion
Dr. RTL delivers a robust, agentic methodology for closed-loop RTL optimization anchored in industrial toolchains, critical-path-level feedback, and interpretable, evolving optimization knowledge. The framework demonstrates significant, consistent PPA improvements unattainable by prior LLM or heuristic-based approaches. The explicit skill learning and group-relative evaluation formalism establish a reproducible path for self-improving design automation agents, opening the door for more intelligent, autonomous, and ultimately trusted synthesis of high-performance digital circuits.