- The paper introduces a novel multi-agent LLM pipeline that automates Verilog code and testbench generation with minimal training data.
- The approach achieves significant gains in functional pass rates and efficiency by pre-generating and refining testbenches through data-efficient fine-tuning.
- The methodology reduces dependency on large annotated datasets while enhancing reproducibility and verification coverage in hardware design automation.
LLM-Based Verilog Code Generation with Data-Efficient Fine-Tuning and Automated Testbench Creation
Introduction
The paper "Exploring LLM-based Verilog Code Generation with Data-Efficient Fine-Tuning and Testbench Automation" (2604.15388) systematically investigates methodologies for improving the efficiency and accuracy of hardware design automation via LLMs. Recognizing the bottlenecks in training data scarcity and rigorous testbench construction, the work proposes an integrated, multi-agent LLM workflow for generating high-quality Verilog modules and associated testbenches, enabling robust fine-tuning with minimal domain-specific supervision. The focus is on supervised fine-tuning (SFT) and multi-agent frameworks for automated testbench generation, evaluated on a refined VerilogEval v2 benchmark.
Methodological Framework
The primary methodological advancement is a multi-phase pipeline for LLM-centric Verilog design and verification. The workflow constitutes:
- Reasoning trace generation from filtered high-quality datasets: The authors employ DeepSeek-R1 deployed via vLLM with 16×H100 GPUs on the curated Pyra-tb subset (6.7K examples, filtered from 692K) to synthesize detailed reasoning traces suitable for SFT. The multi-agent workflow parses domain-specific data, extracts/verifies problem statements, and programmatically generates correct-by-construction Verilog solutions.
- Automated testbench generation via LLM multi-agent collaboration: Specialized agents within the pipeline individually handle roles such as quality checking, testbench instantiation, and iterative refinement, with downstream verification employing existing simulation tools.
- Optimization via pre-generation and revision of testbenches: Pregenerating testbenches prior to description refinement enables enhanced coverage and higher functional pass rates with reduced resource overhead.
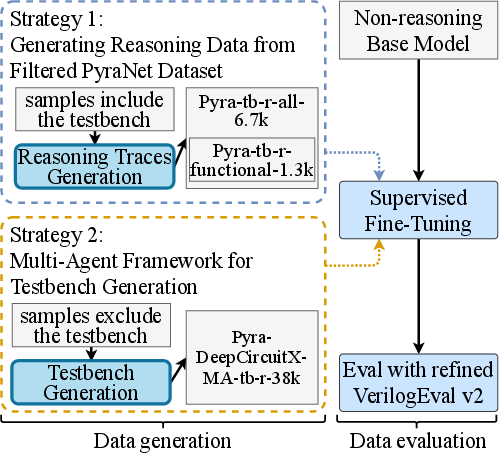
Figure 1: The workflow for synthesizing training data for LLM-driven Verilog code generation, encompassing data filtering, reasoning trace generation, and multi-stage agent collaboration.
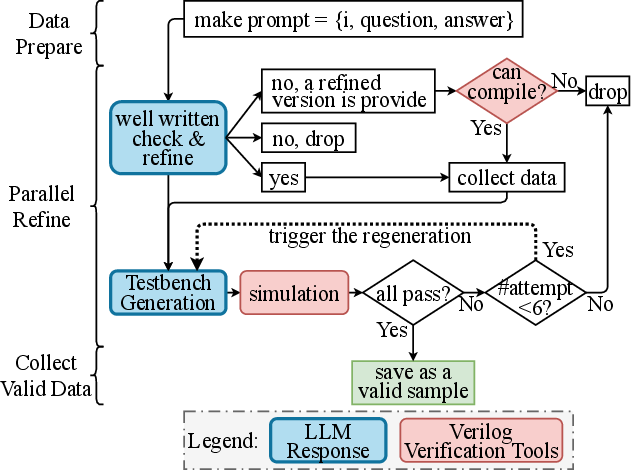
Figure 2: Architecture of the multi-agent framework orchestrating verification and testbench code creation for functional validation.
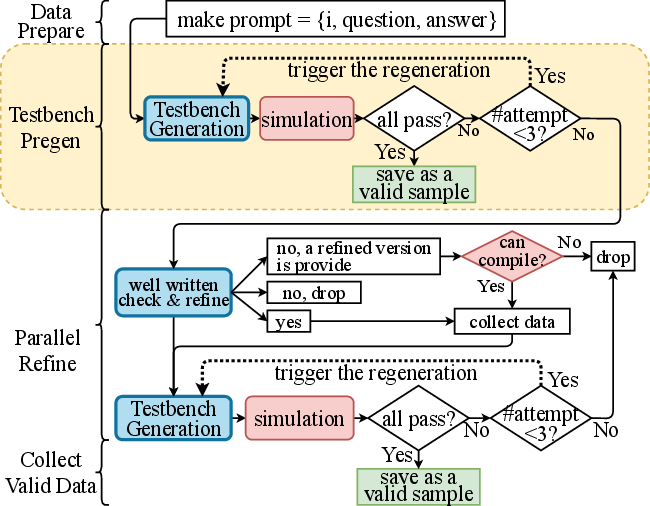
Figure 3: An enhanced variant of the multi-agent framework incorporating pregeneration and iterative revision of testbenches for improved functional coverage and efficiency.
Experimental Setup and Benchmarking
Experiments are conducted leveraging the Qwen-Coder-7B-Instruct model as a baseline, extensively fine-tuned and evaluated utilizing high-performance computational resources. The test suite is based on a rigorously refined variant of the VerilogEval v2 benchmark, with extensive updates to specifications and test cases for improved coverage and reduction of ambiguities (2604.15388).
Key findings include:
- Dataset composition and throughput: 6,704 samples produced 1,386 functionally correct outputs, 4,421 syntax-correct examples, and 897 compilation errors, with 6M+ input and 54M+ output tokens processed at >300 tokens/s.
- Testbench quality and effectiveness: Using the proposed multi-agent pipeline, average pass rates improved (PyraNet: 31.33→38/50, DeepCircuitX: 21.33→34/50) with fewer API calls when integrating pregeneration. The framework demonstrably enhances error detection and verification coverage.
- Model performance: The MA-tb-7B model, fine-tuned on 38K LLM-generated, testbench-augmented samples, achieves 68% pass@1, competitive with state-of-the-art 7B models such as CodeV-R1-7B-Distill (70%, 87K samples) and CodeV-R1-7B with DAPO (74%, 90K+ samples). Notably, this is accomplished with a significantly lower data regime. Smaller datasets (1.3K functional samples) do not yield accuracy improvement, but moderate-scale collections encompassing syntactic variance facilitate substantial gains.
Implications and Theoretical Impact
The implications of this work are multifold:
- Data efficiency and accessibility: By automating reasoning trace and testbench synthesis, the burden of large, annotated HDL datasets is mitigated. The demonstrated workflow enables effective training in data-constrained, proprietary, or confidential environments.
- Functional verification automation: Decoupling module generation from testbench construction in a collaborative multi-agent setting systematically improves verification coverage and reduces human effort and latency.
- Benchmarking and reproducibility: The adoption of a refined VerilogEval v2 benchmark and release of detailed workflow parameters contribute to the standardization and reproducibility in LLM-based hardware synthesis research.
Future Research Directions
Emergent questions for further investigation include:
- Scaling to larger/more diverse models and datasets: Extending the workflow to larger foundation models assessed in the study (Gemini2.5-Pro, DeepSeek-V3.1/R1, etc.), as well as integration with multi-level reasoning distillation strategies.
- Hybrid RL-SFT frameworks: Given the success of RL feedback in other works (e.g., VeriReason (Wang et al., 17 May 2025), VeriPrefer (Wang et al., 22 Apr 2025)), hybridizing automated testbench feedback with RL or DAPO systems warrants deeper exploration.
- Semantic and design-quality metrics: Beyond functional correctness, incorporating design-quality objectives (e.g., PPA analysis) as part of end-to-end LLM pipelines.
Conclusion
This work validates a scalable, data-efficient paradigm for LLM-based Verilog generation using automated, multi-agent testbench pipelines, reaching near-parity with state-of-the-art systems at lower data budget cost. The approach introduces principled methodologies for integrating SFT and verification tools and serves as a robust baseline and toolkit for future automated hardware design and EDA research.

