- The paper introduces Spec2Cov, which leverages agentic LLM workflows to automatically close code coverage gaps in digital hardware verification.
- It employs an iterative process that generates, simulates, and refines test cases, achieving a geometric mean coverage of 91.47% and robust pass rates.
- The framework seamlessly integrates with industry-standard simulators and adapts to complex designs, reducing the manual burden in hardware verification.
Spec2Cov: An Agentic Framework for Coverage Closure in Digital Hardware Verification
Introduction
The manual burden of pre-silicon hardware verification, particularly code coverage closure, continues to be a significant productivity bottleneck in hardware design cycles. Despite the integration of constrained-random and directed testing, achieving closure remains labor-intensive due to the iterative and error-prone nature of the process. "Spec2Cov: An Agentic Framework for Code Coverage Closure of Digital Hardware Designs" (2604.15606) addresses this challenge by introducing Spec2Cov, a framework that leverages the code-generation and iterative reasoning capabilities of LLMs, orchestrated within an agentic architecture. This framework automates the generation and refinement of test stimuli, closing coverage gaps with minimal human intervention and integrating seamlessly with industry-standard simulation tools.
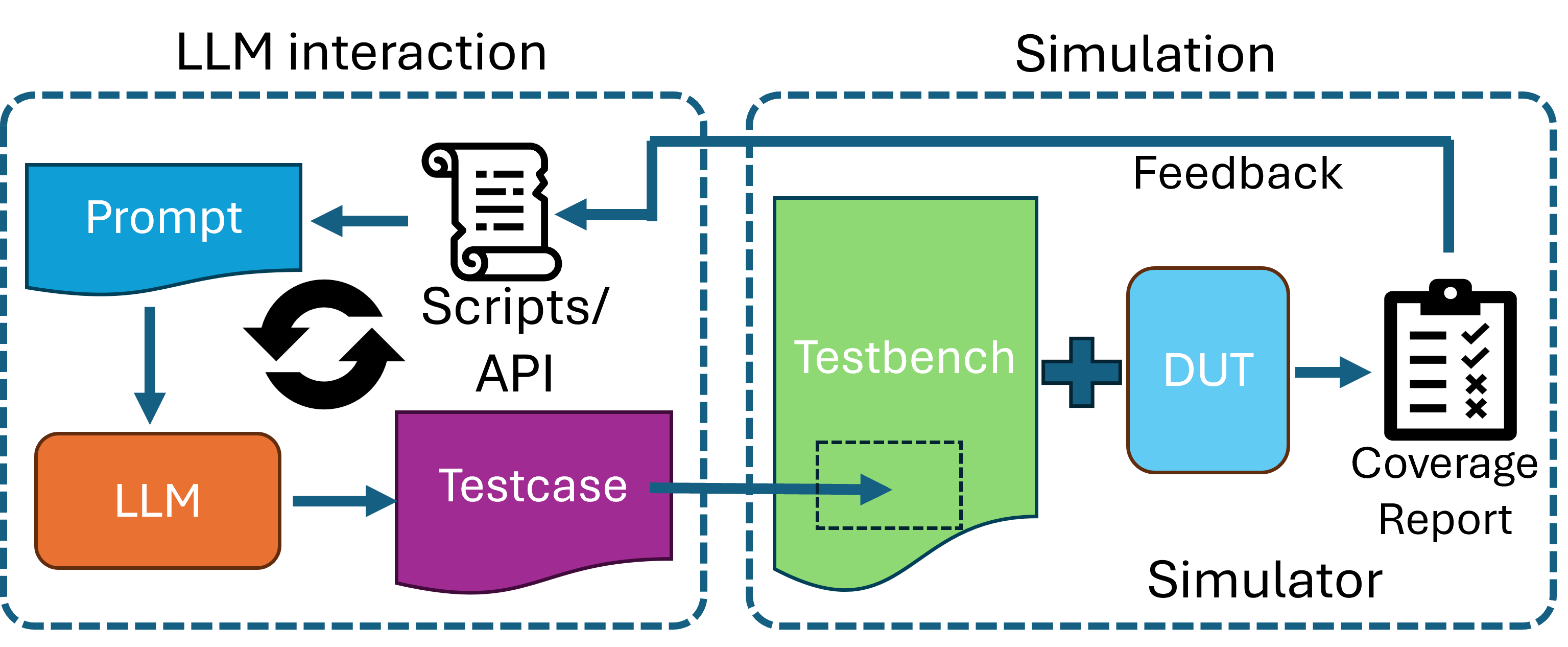
Figure 1: High-level overview of the Spec2Cov agentic framework implementing automatic coverage closure from specifications to simulator feedback.
Spec2Cov Framework Architecture
Spec2Cov operationalizes coverage closure via a structured agentic workflow, comprising LLM-driven test generation, interaction with a hardware simulator, and iterative refinement based on dynamic coverage feedback.
System Phases:
- Initialization: The LLM is provided with the design specification and the top module's port definitions. Constrained-random testcases are generated leveraging constructs such as
$urandom and .randomize(), emulating standard verification methodology.
- Iterative Coverage Closure: After simulation, coverage reports are parsed to identify residual coverage holes. For subsequent iterations, the LLM is shown relevant annotated design code—targeting uncovered modules or statements—enabling informed modification or regeneration of testcases. This loop continues until full coverage or a specified iteration limit is met.
- Logging and Analysis: Each conversation is logged in detail, preserving all iterations, coverage data, token metrics, and errors, facilitating reproducibility and meta-analysis.
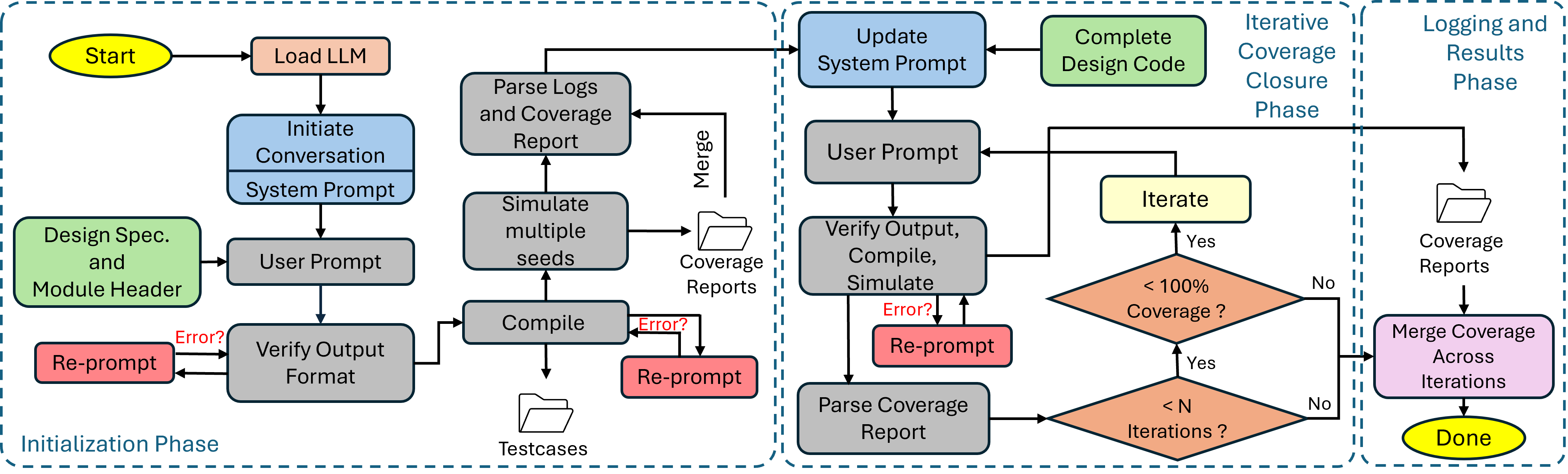
Figure 2: Detailed data and control flow in the Spec2Cov framework, illustrating prompt generation, simulation integration, report parsing, and feedback cycling.
Spec2Cov is model-agnostic, supporting state-of-the-art LLMs (notably GPT-4o in the reported experiments), and interfaces with common simulators (QuestaSim, VCS, Verilator). No fine-tuning is required; only prompt and workflow engineering enhance the agentic behavior.
LLM Enhancement Methods
Spec2Cov introduces multiple features to enhance the LLM’s efficacy:
- Testplan Creation: The LLM synthesizes a detailed verification plan from the specification, delineating required stimuli and corner cases, thus emulating a verification engineer’s reasoning.
- Batched Generation: For robust exploration, the agent generates k parallel testcases (typically k=5), simulates all, and selects the one that maximizes immediate coverage improvement.
- Context Pruning: To counteract context-window saturation and degradation, the conversation history is pruned to retain a focused, 15,000-token window prioritizing salient exchanges, discarding error-correction noise.
Together, these techniques mitigate prompt bias, maximize syntactic and functional correctness, and improve convergence rates.
Evaluation and Results
Coverage Metrics
Across 26 hardware designs—including CVDP [pinckney2025comprehensiveverilogdesignproblems] and challenging GitHub benchmarks—Spec2Cov delivers high code coverage (statement/line) with a geometric mean of 91.47%. Simpler designs consistently achieve near- or full coverage, while large, hierarchical designs (>$450$ lines, multi-level hierarchy) achieve up to 49%. This is a substantial improvement given the lack of prior baseline for specification-to-coverage closure on CVDP.
Agentic Iteration versus Single-Shot
Comparisons between the agentic iterative approach and single-shot (one-iteration) test generation demonstrate that agentic cycles yield significantly higher average coverage. For many designs, single-shot runs either fail to yield any meaningful coverage or plateau early, whereas the closed-loop iteration incrementally eliminates coverage holes.
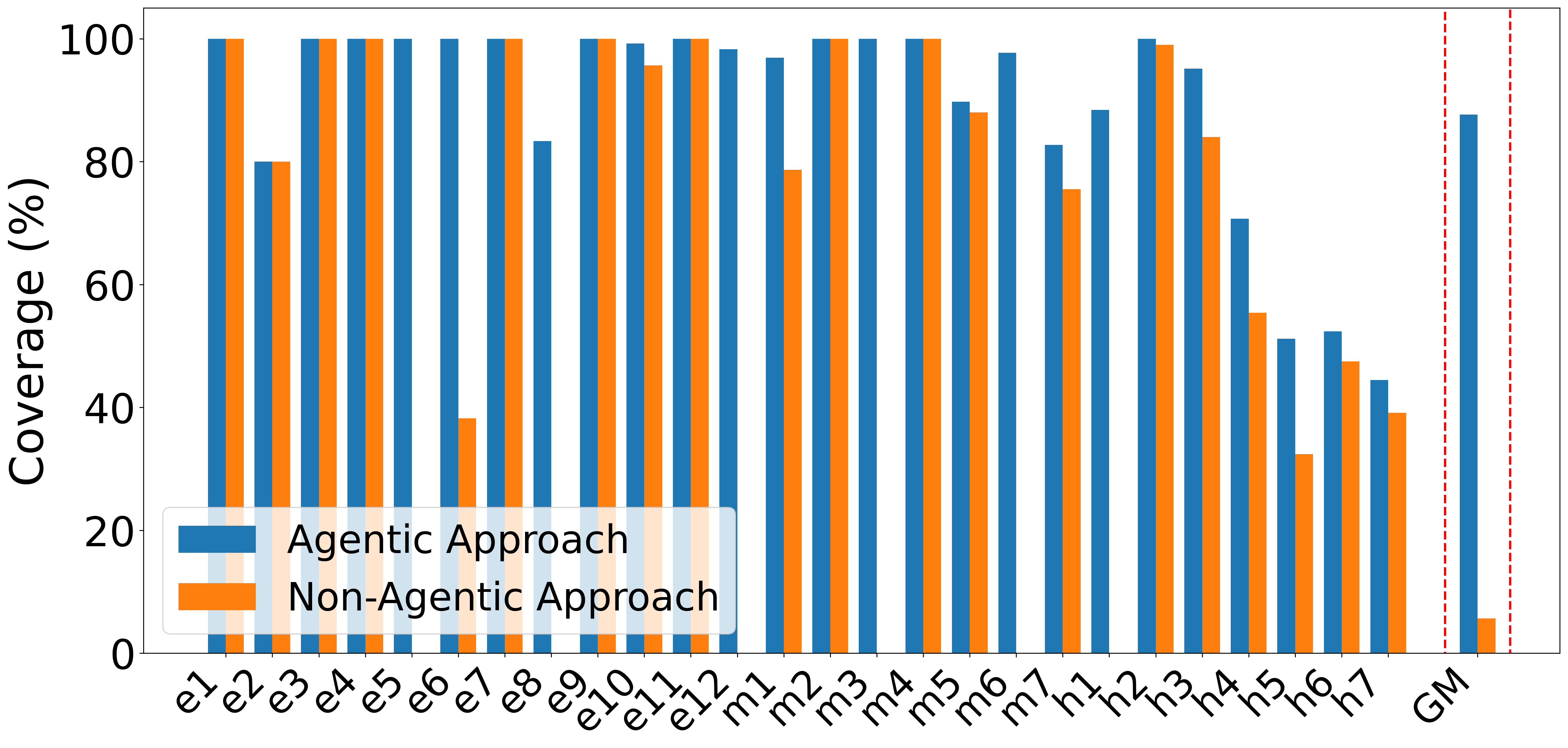
Figure 3: Coverage improvement from agentic, iterative prompting relative to single-shot generation, especially pronounced on medium and hard designs.
Feature Ablation
A systematic ablation was conducted to assess each feature’s marginal impact—batched generation (BG), testplan creation (TC), and context pruning (CP):
- BG modestly boosts medium/hard designs.
- TC alone sometimes reduces average performance, potentially due to increased prompt complexity, but, when enhanced with explicit feature-based test planning, leads to notable improvements.
- CP is essential to avoid context pollution; with CP, even degraded runs (due to TC) recover strongly, with some hard designs achieving 100% after pruning.
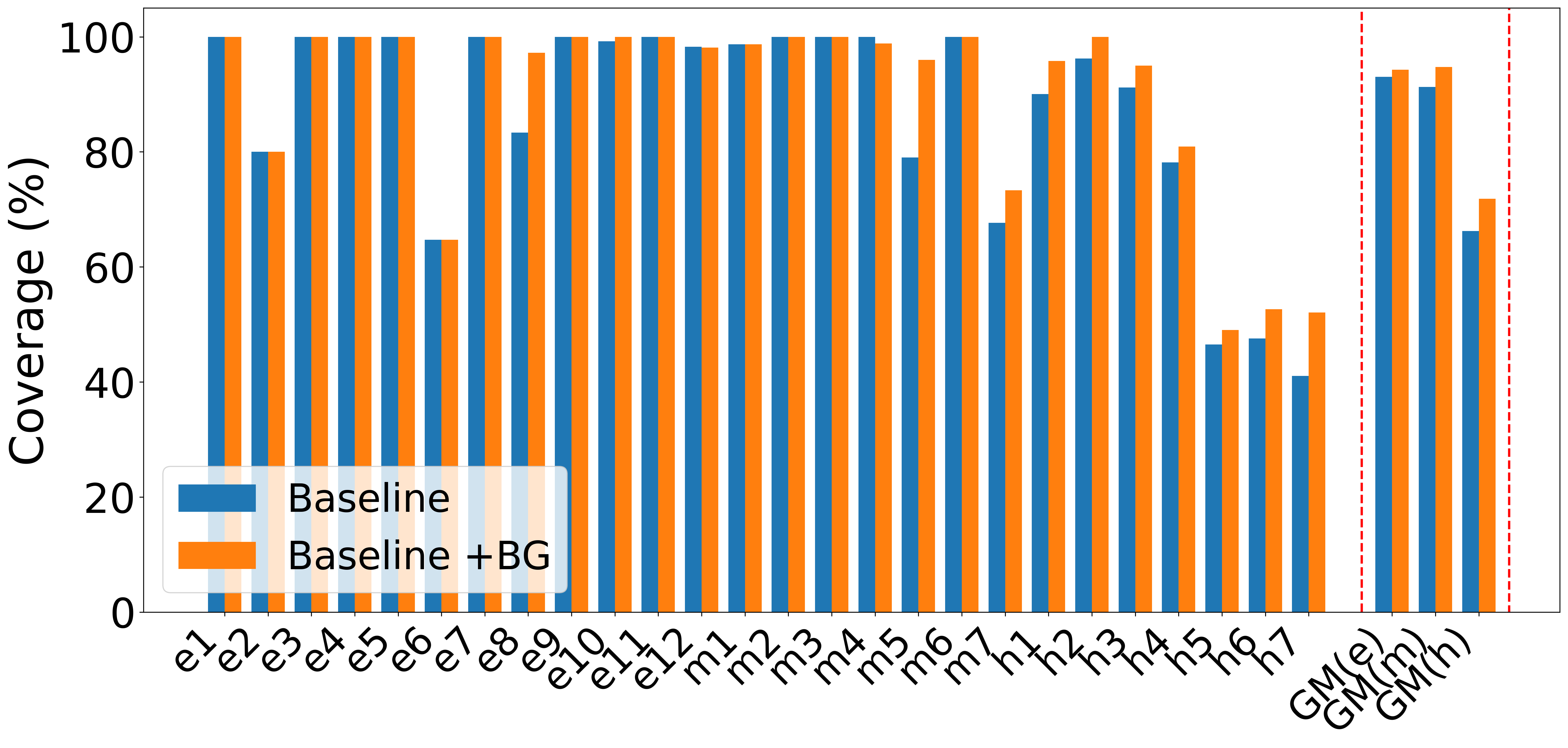
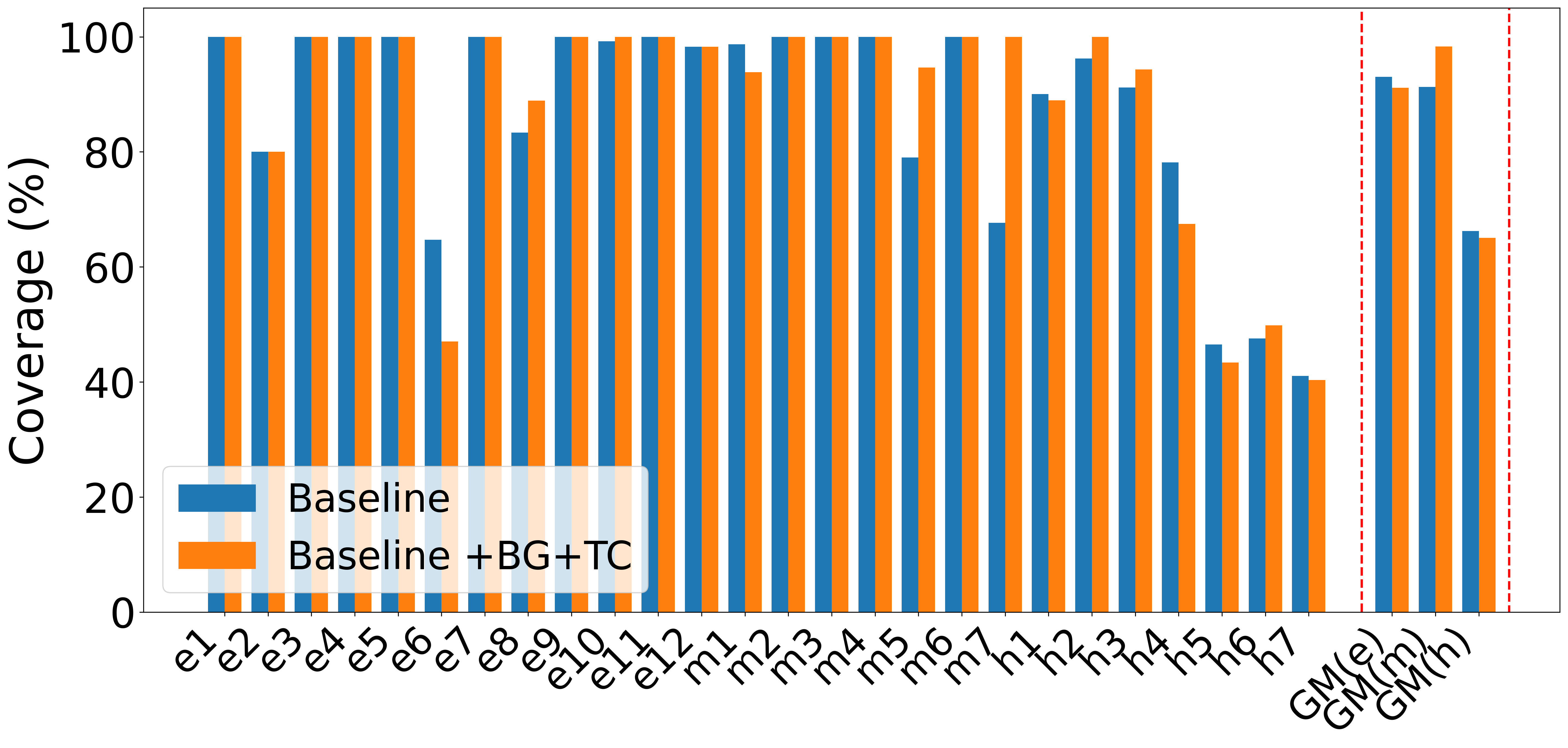
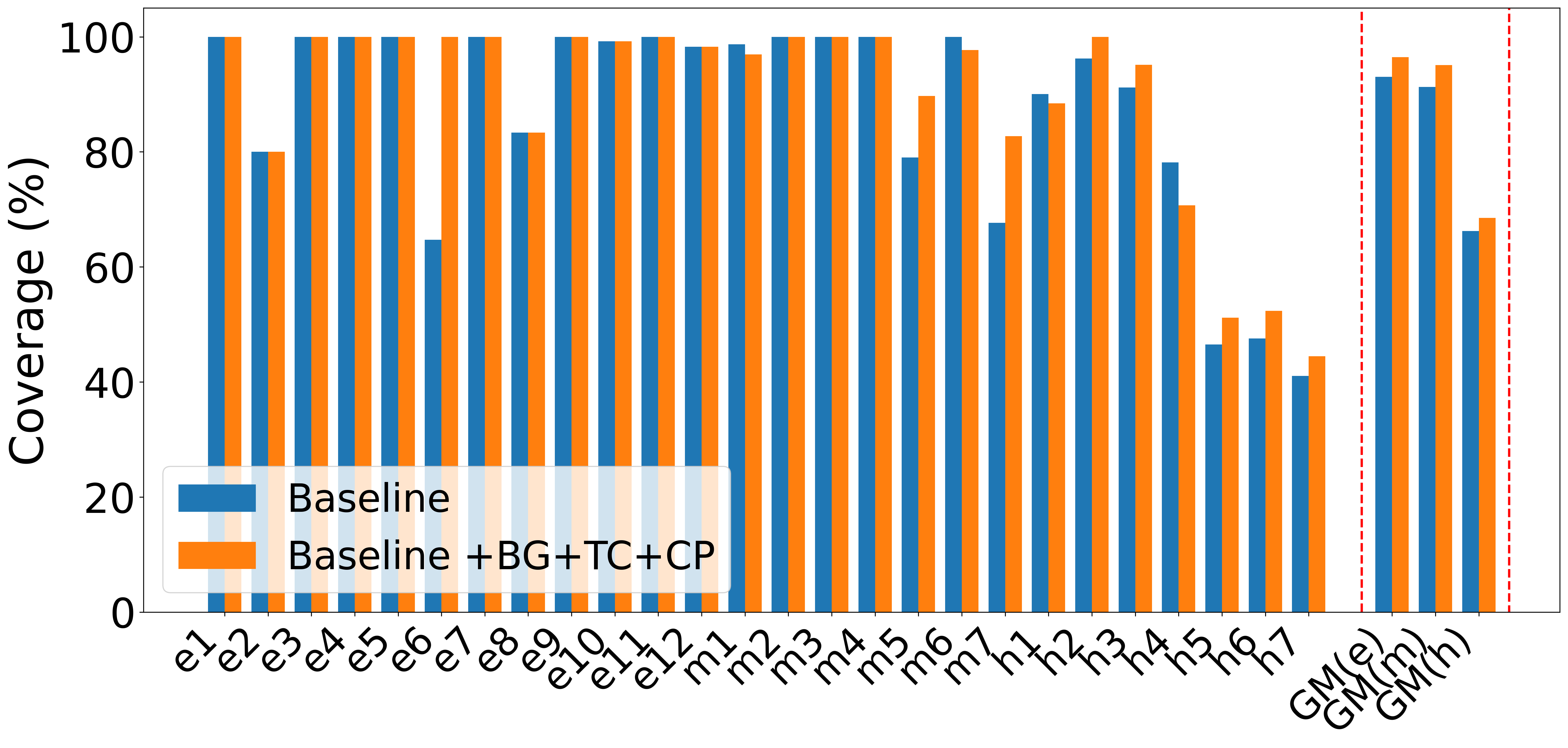
Figure 4: Progression of geometric mean coverage as BG, TC, and CP are enabled, highlighting the necessity of context pruning for maximal average coverage.
Robustness and Cost Analysis
- Pass@k Rates: Spec2Cov maintains a pass@1 of 0.5 and pass@5 of 0.61 across diverse designs, outperforming baselines and showing stability under noisy LLM outputs.
- Efficiency: Iteration count and token usage scale with design complexity. However, wall-clock time is minimized through parallel process orchestration, achieving closure in minutes rather than hours or days of manual test development.
Discussion and Implications
Spec2Cov advances specification-driven verification automation by:
- Minimizing Prompt Bias: Testcases are generated from textual specifications, not design code, preventing common-mode errors and preserving the value of verification as a check distinct from implementation.
- Agentic Workflows: The iterative loop mirrors human-in-the-loop coverage closure, adapting based on feedback much like a verification engineer would, but with far greater throughput and reproducibility.
- Extensibility: The methodology, while currently targeting statement coverage, is open to extension to functional and assertion-based coverage with minimal adaptation.
- Integration: The system’s simulator abstraction and logging facilitate deployment in legacy flows and integration with RAG, hierarchical planning, or richer design document ingestion.
Future research could examine comprehensive RAG strategies, hierarchical closure approaches at SoC scale, and comparative fine-tuning with larger hardware-specific training sets. Additionally, the observed stochasticity in LLM outputs underlines the importance of robust plan-and-iterate loops and will drive further developments in agentic prompt engineering.
Conclusion
Spec2Cov establishes a practical, open-source agentic paradigm for automating the code coverage closure process directly from hardware design specifications (2604.15606). Its combination of LLM-based code synthesis, simulator-channel feedback, and structured prompt engineering not only reduces manual effort but also achieves high pass rates and substantial coverage on industry-relevant benchmarks. This operationalizes LLMs as core actors in the EDA verification loop and underpins future agentic, specification-driven flows in digital hardware verification.

