- The paper presents CovAgent, a two-tier, domain-specialized framework that minimizes token use while maintaining high verification coverage.
- It systematically analyzes how tokens are allocated across different verification stages, revealing that comprehension tokens dominate in complex designs.
- Empirical results show 4–13× token reduction with equivalent coverage, establishing a taxonomy of coverage holes to guide future verification research.
Understanding Inference-Time Token Allocation and Coverage Limits in Agentic Hardware Verification
Introduction
The increasing integration of LLMs into electronic design automation (EDA) workflows has made agentic approaches to hardware verification a growing area of interest. The paper "Understanding Inference-Time Token Allocation and Coverage Limits in Agentic Hardware Verification" (2604.15657) addresses critical limitations in previous works: specifically, the lack of systematic analysis concerning the persistent coverage holes in LLM-generated stimulus, and the opaque distribution of inference-time computation (token allocation) throughout the agentic verification process. The authors propose CovAgent, a two-tier framework built on OpenAI Codex and a domain-specialized LangGraph system, to empirically examine these questions on industry-relevant hardware designs.
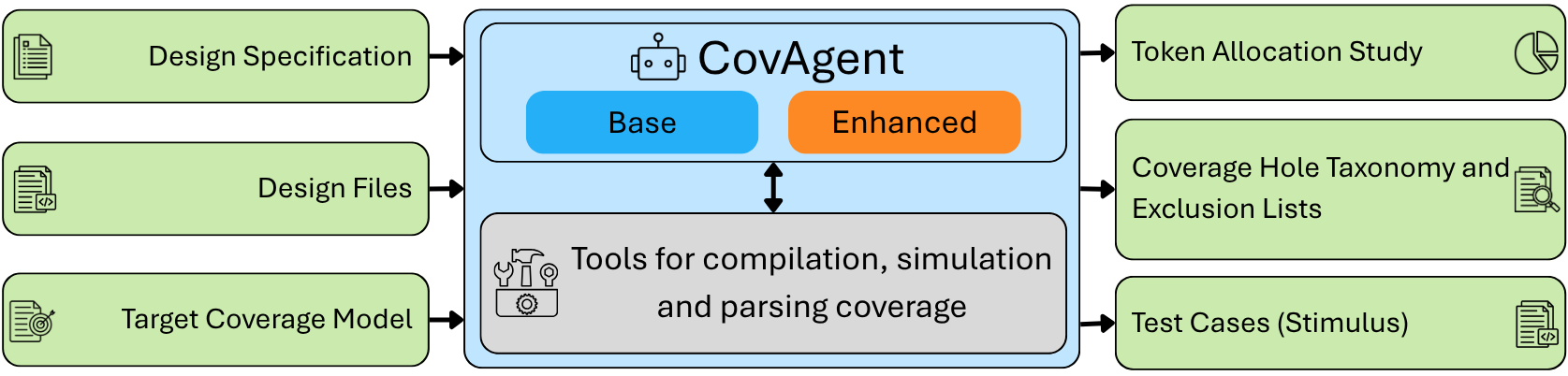
Figure 1: The proposed framework’s architecture, showcasing both base and enhanced agentic tiers for hardware coverage closure analysis.
CovAgent Framework: Architecture and Workflow
CovAgent operationalizes hardware coverage closure as an iterative agentic process, providing two contrasting approaches: a general-purpose base agent using Codex CLI, and an enhanced tier employing a tightly constrained LangGraph workflow. Both consume natural language specifications, RTL sources, and coverage models, with an end goal of maximizing verification coverage while characterizing residual holes comprehensively.
The workflow is formalized as a ReAct (Reasoning + Acting) loop, cycling through design comprehension, testbench synthesis, compilation/instrumentation, simulation with coverage aggregation, point-by-point coverage analysis, and targeted stimulus refinement. The enhanced agent benefits from structured tool APIs and coverage feedback, which streamlines both comprehension and synthesis tasks while minimizing unproductive exploratory inference.
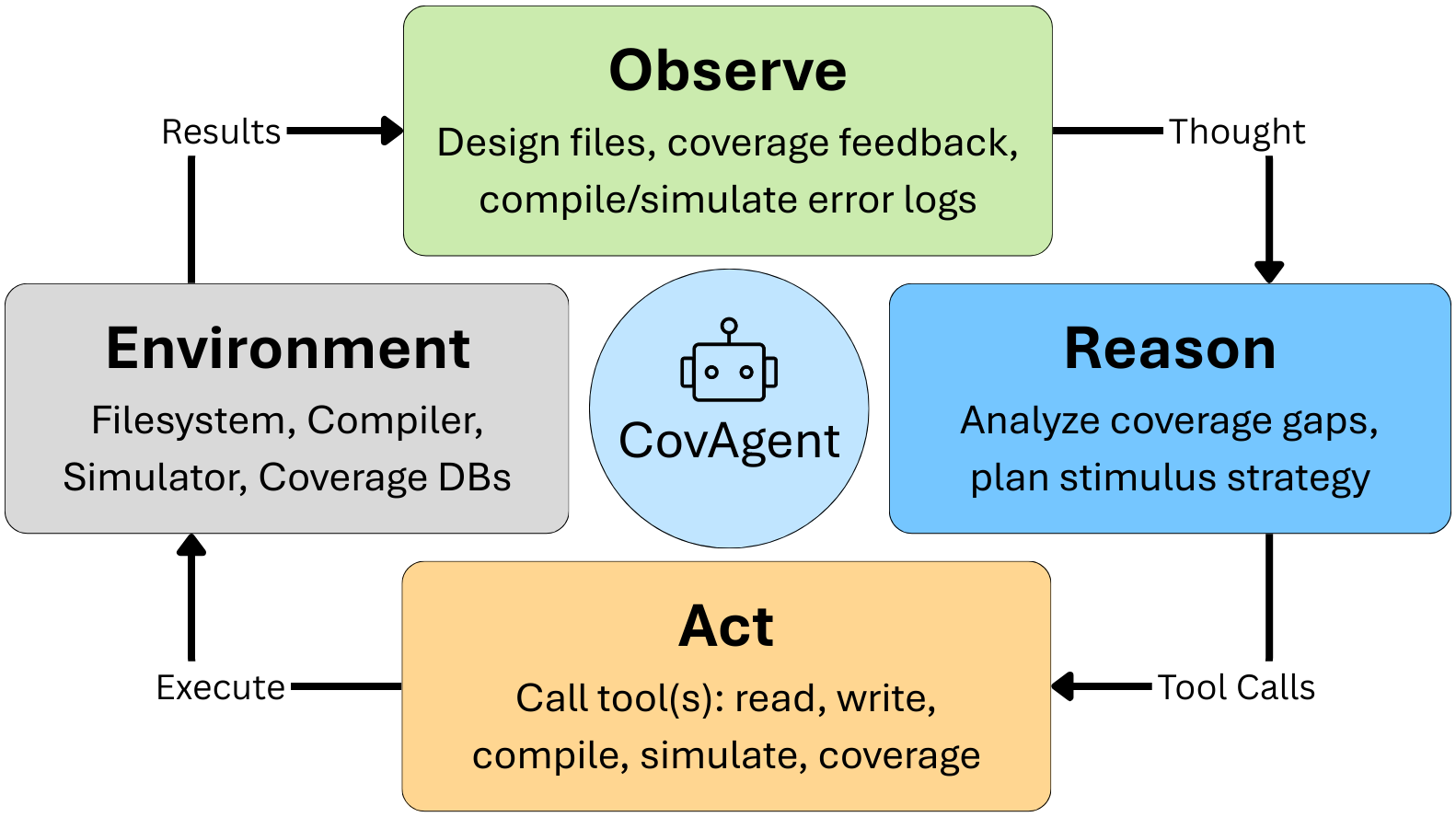
Figure 2: Detailed CovAgent workflow illustrating iterative coverage-directed stimulus generation and classification.
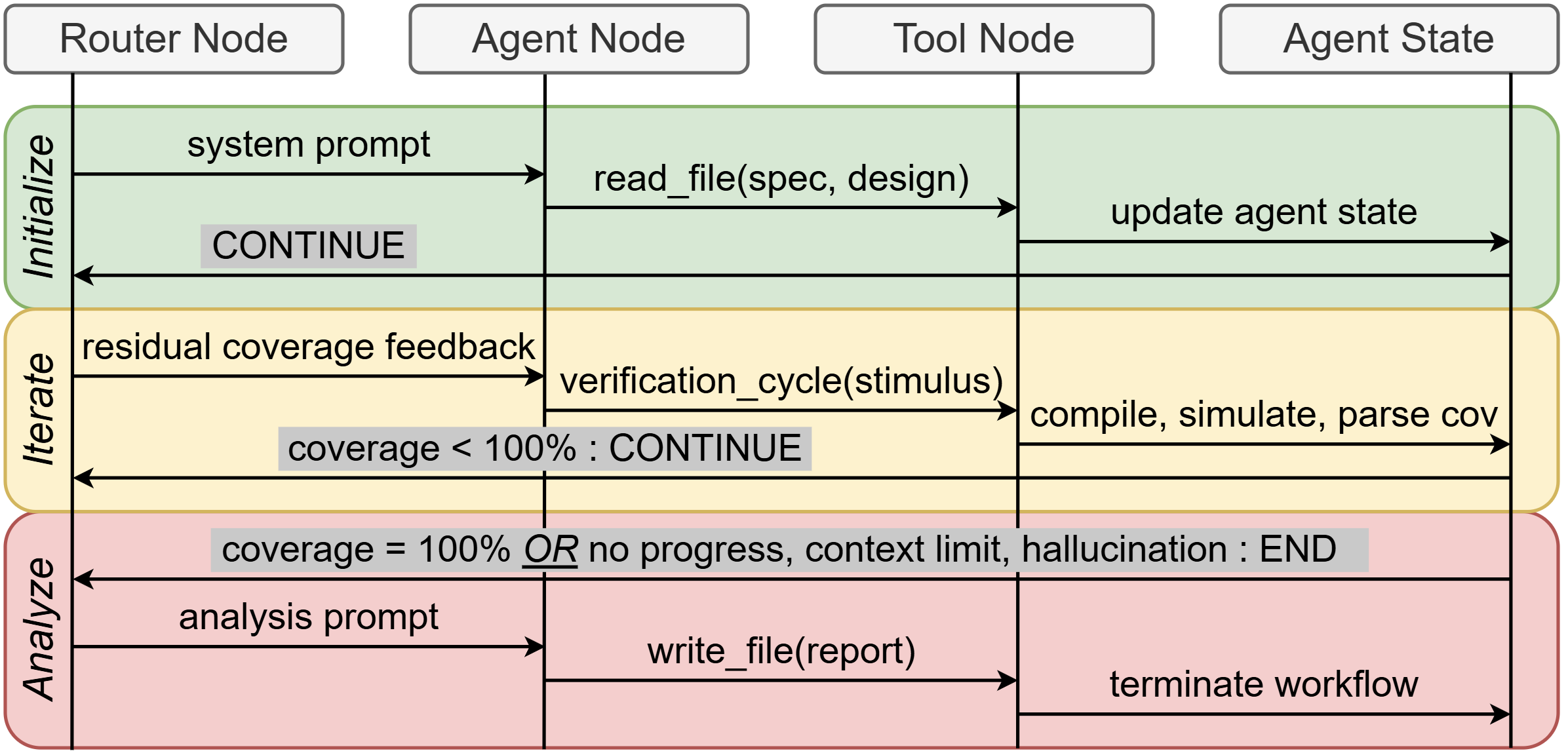
Figure 3: Enhanced agent architecture leveraging LangGraph’s state graph and structured tools for efficient coverage closure.
Instrumentation tracks tokens across six categories—system prompt, design comprehension, stimulus generation, coverage feedback, error recovery, and agentic overhead—enabling detailed analysis of compute-resource expenditure and inefficiency sources. Importantly, the enhanced agent constrains environment interaction through composite verification cycles and feedback injection, pruning away large classes of redundant or low-impact reasoning.
Coverage Outcomes and Token Allocation Analysis
CovAgent is evaluated on 19 module-to-complexity-scale RTL designs, ranging from 100 to 8,500 lines of code and up to five levels of hierarchy. The primary metrics are cumulative coverage, total token consumption, per-category token allocation, and cost.
Notable empirical results include:
- Coverage Parity with Token Reduction: The domain-specialized enhanced agent achieves at least equivalent, and often higher, coverage (95–99%) versus the base agent while using 4–13× fewer tokens and converging 2–4× faster, particularly impactful as design complexity increases.
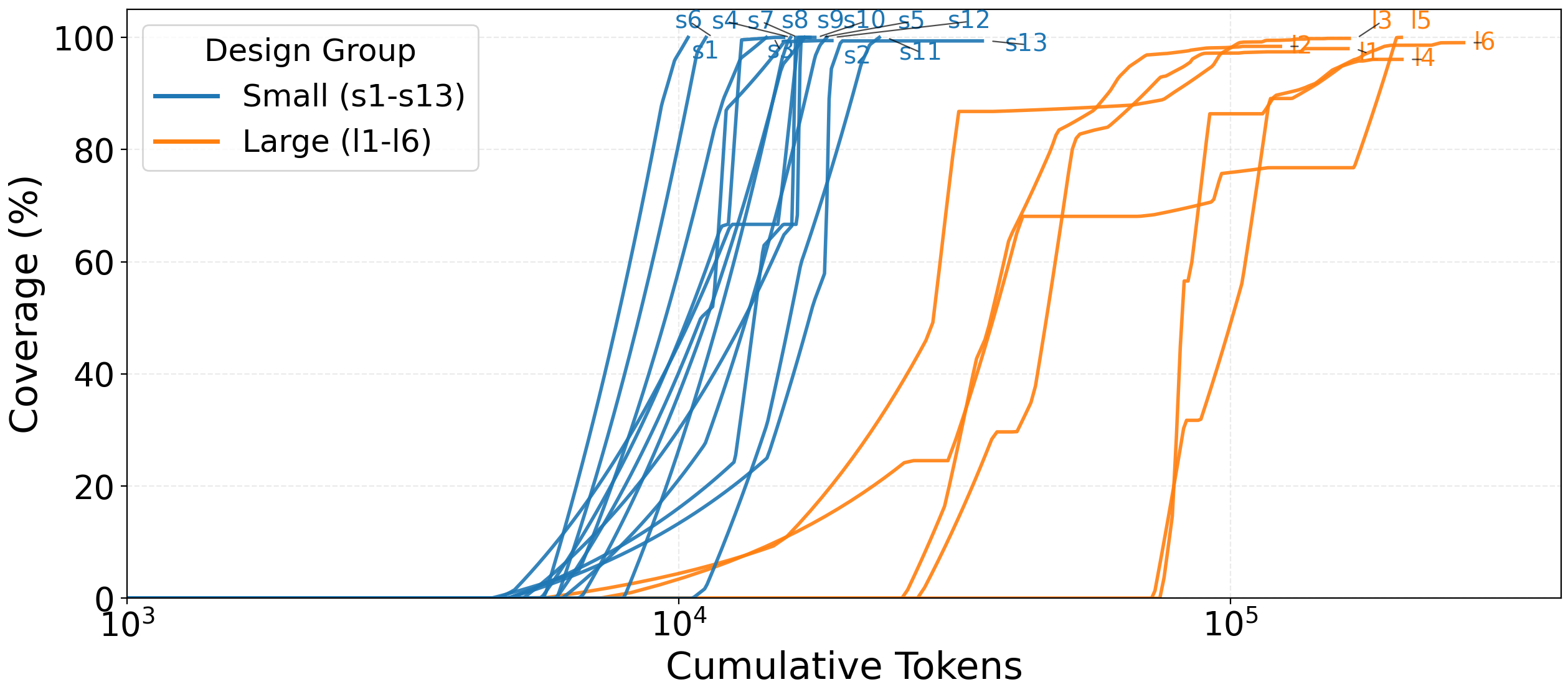
Figure 4: Coverage achieved versus cumulative tokens, across all evaluated designs, highlighting diminishing returns and last-mile difficulty.
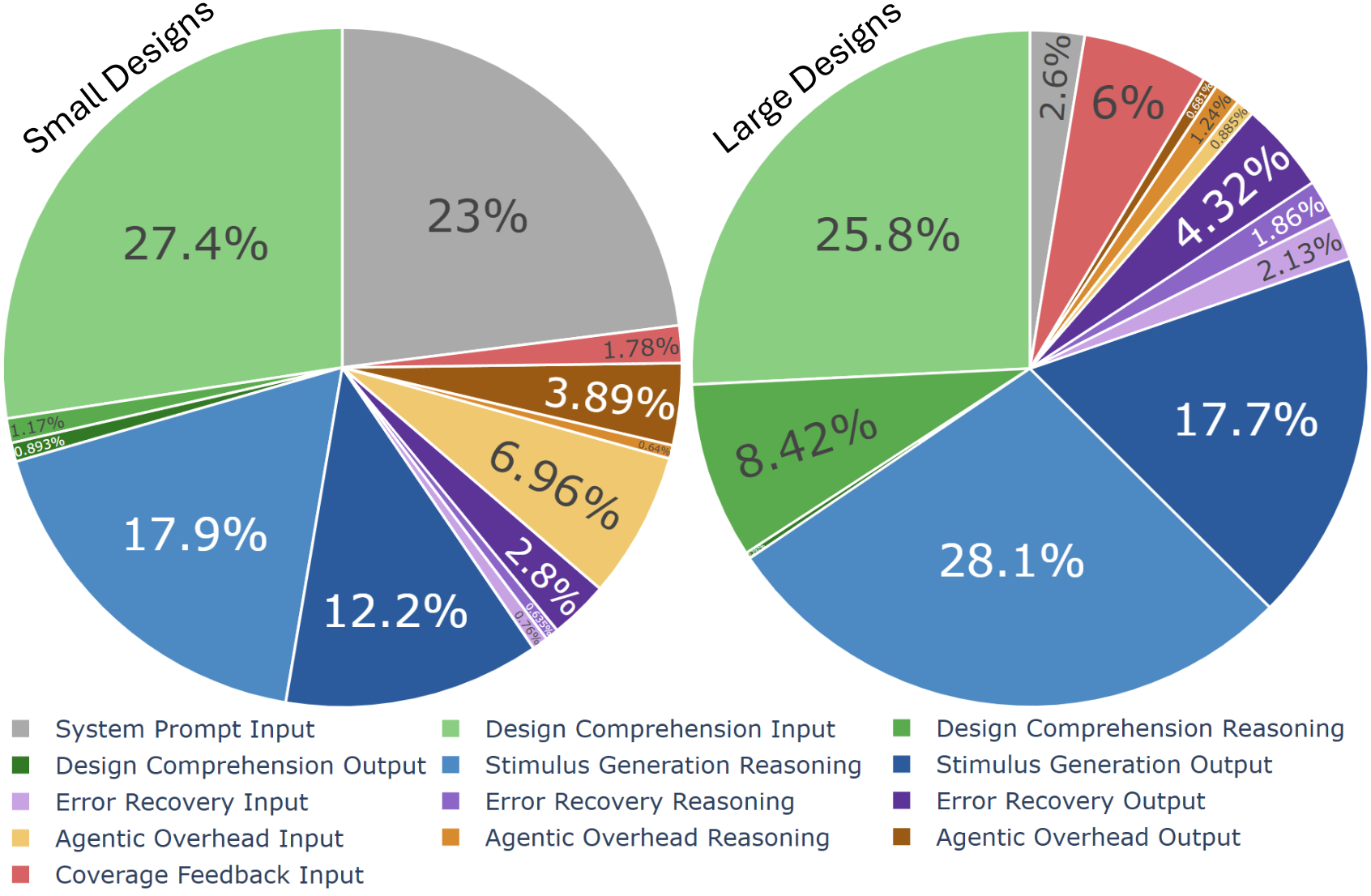
Figure 5: Token allocation breakdown averaged across design scales, showing that design comprehension and system prompting dominate large-design runs.
- Scaling and Diminishing Returns: Small designs converge quickly, often within 10K–30K tokens, while complex modules plateau in the 96–99% range after 55K–175K tokens, requiring substantially more comprehension tokens per line of code as complexity increases.
- Production Tokens: Only 12–18% of tokens generate actual testbench code; the remainder support comprehension, feedback, or workflow orchestration.
- Reasoning Bottleneck: For large designs, comprehension (not code synthesis) dominates reasoning effort, consuming a superlinear share of tokens with scale.
Coverage Hole Taxonomy: Ceilings vs. Reasoning Frontiers
A key contribution is an empirical coverage hole taxonomy distinguishing methodology-bound ceilings from reasoning frontiers:
- Ceilings: Integration-tied-off hardware, infeasible boundaries due to simulation limits, and dead code (together < 7% of holes in complex designs) are inherently unreachable without environmental modification or exclusion.
- Frontiers: Protocol sequencing complexity and multi-module pipeline warm-up are persistent reasoning challenges, together constituting 90% of residual holes in large designs. These require advanced protocol modeling, sequential handshaking, or precise timing—tasks LLMs diagnose but rarely solve in synthesizable code.
These findings inform both coverage model exclusion generation and human escalation strategy, supporting practical adoption in verification teams.
Comparative Impact of Domain Specialization
A direct comparison between base and enhanced agents demonstrates unambiguous efficiency and effectiveness gains via domain specialization. On small designs, the enhanced agent's advantage is overwhelming (13.4× token reduction, <2 iterations on average). For large-scale RTL, structured tooling and feedback drive both higher final coverage and consistent reductions in token expenditure.
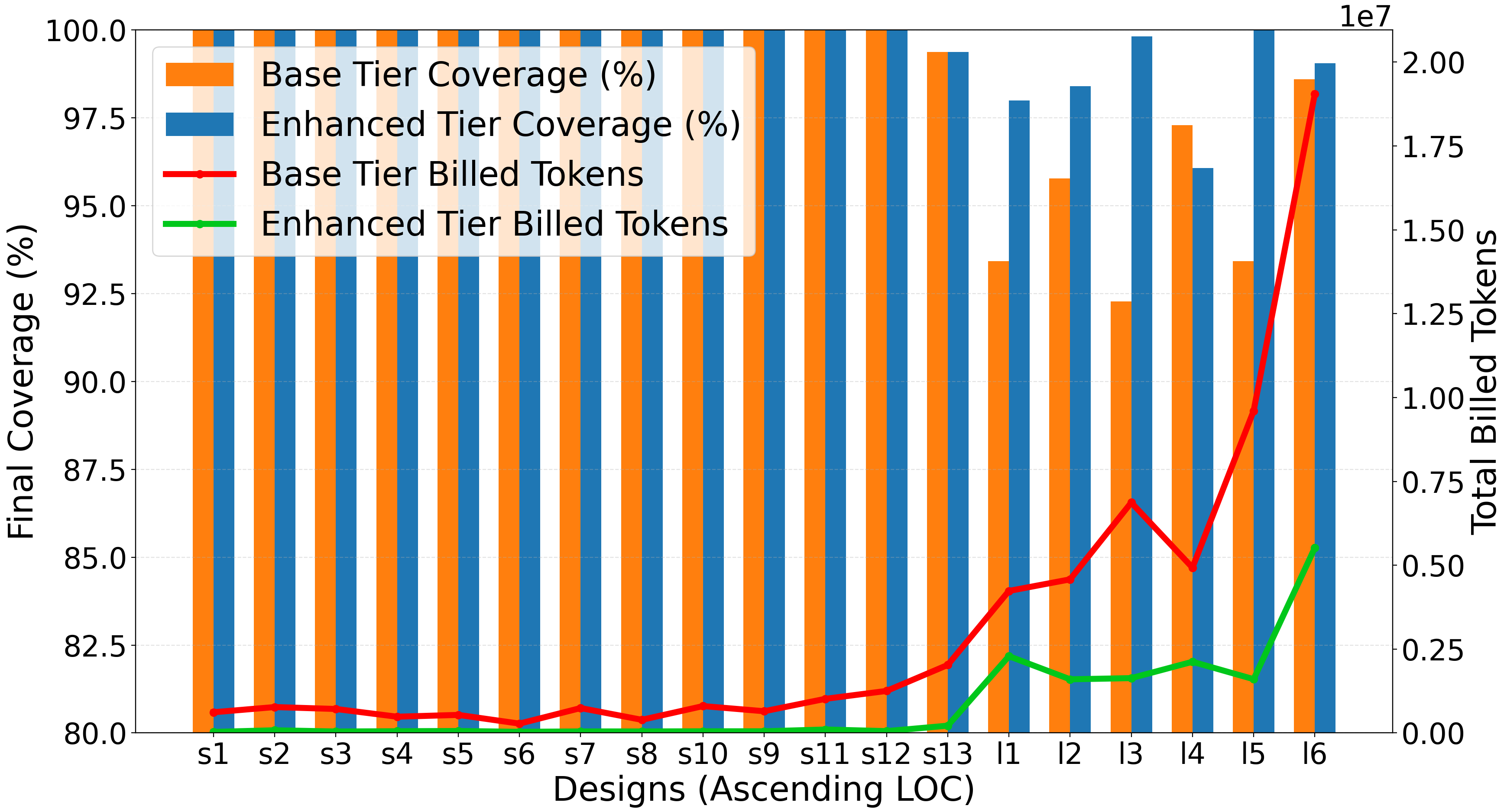
Figure 6: Coverage and token utilization comparison between the Codex-based base agent and enhanced domain-specialized agent.
Model Scale Sensitivity and Cost Implications
Analysis with GPT-5-mini versus GPT-5.2 illustrates the compensatory effect of domain specialization for low/mid-complexity designs: despite smaller model capacity, coverage remains high (99.6% on small designs), albeit at increased token cost. However, for large designs, coverage drops by up to 30 points (CAN controller), and the token advantage evaporates due to accelerated plateauing on reasoning-bound holes.
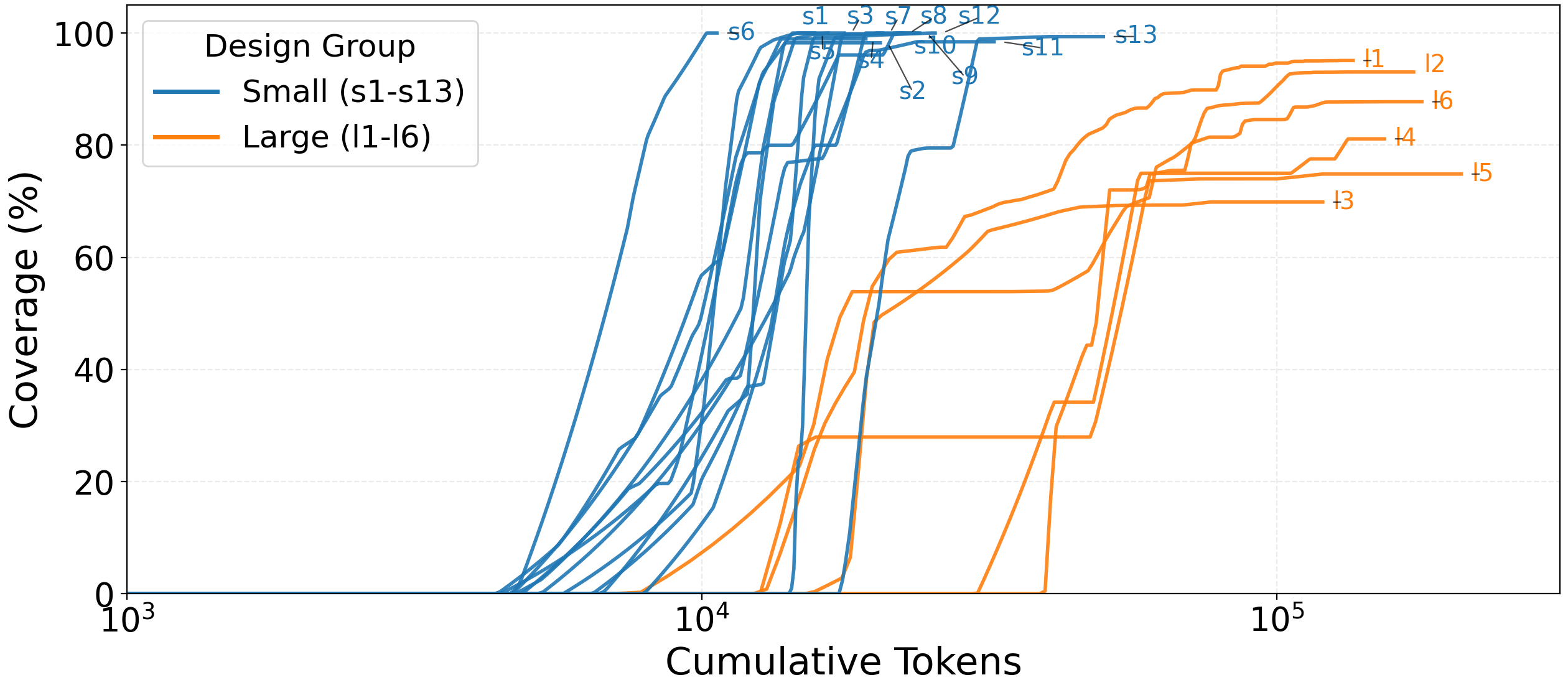
Figure 7: Comparison of coverage curves versus token consumption for reduced-capacity LLM (GPT-5-mini).
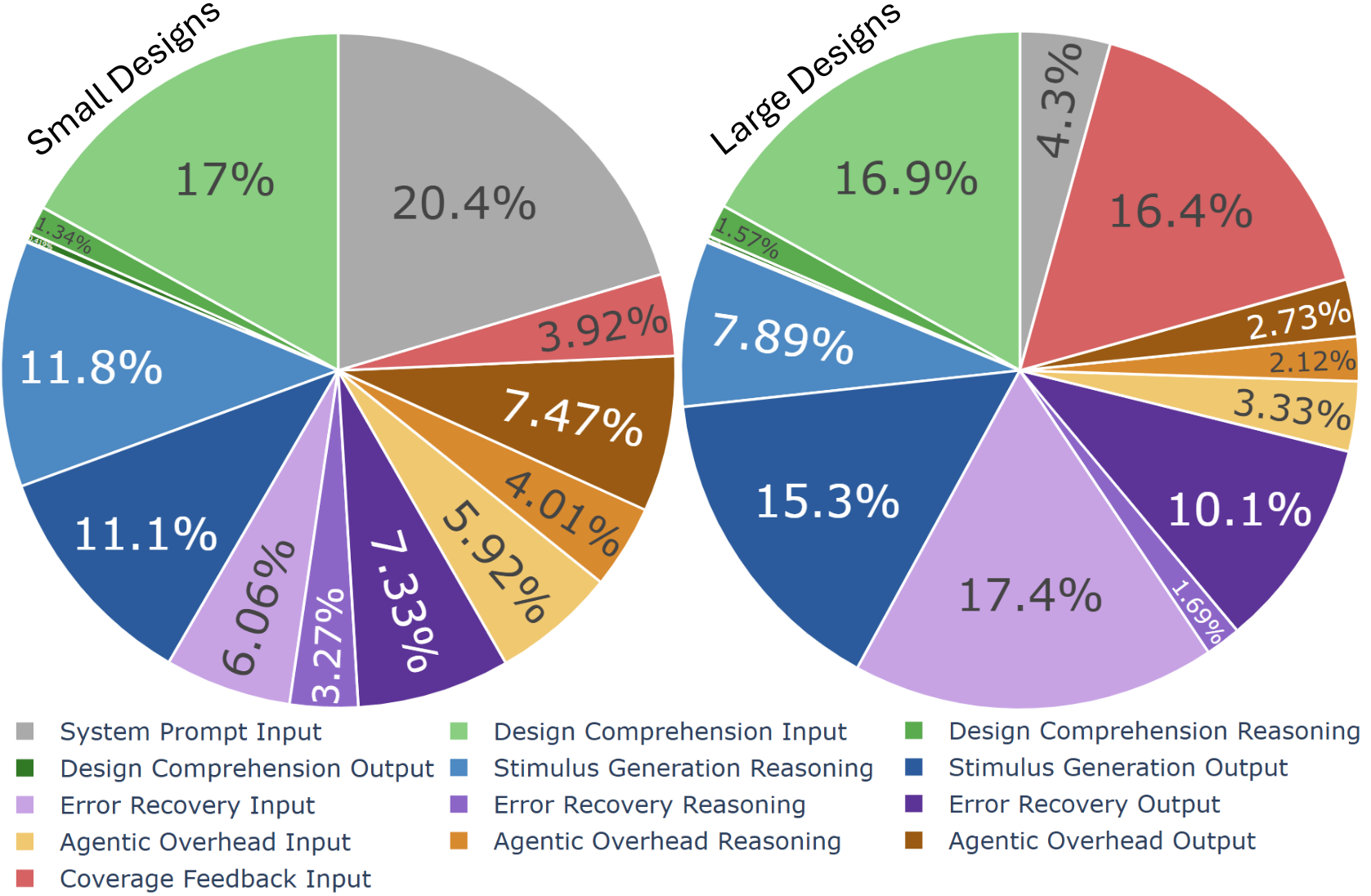
Figure 8: Token allocation profile for GPT-5-mini, showing impaired reasoning allocation relative to GPT-5.2.
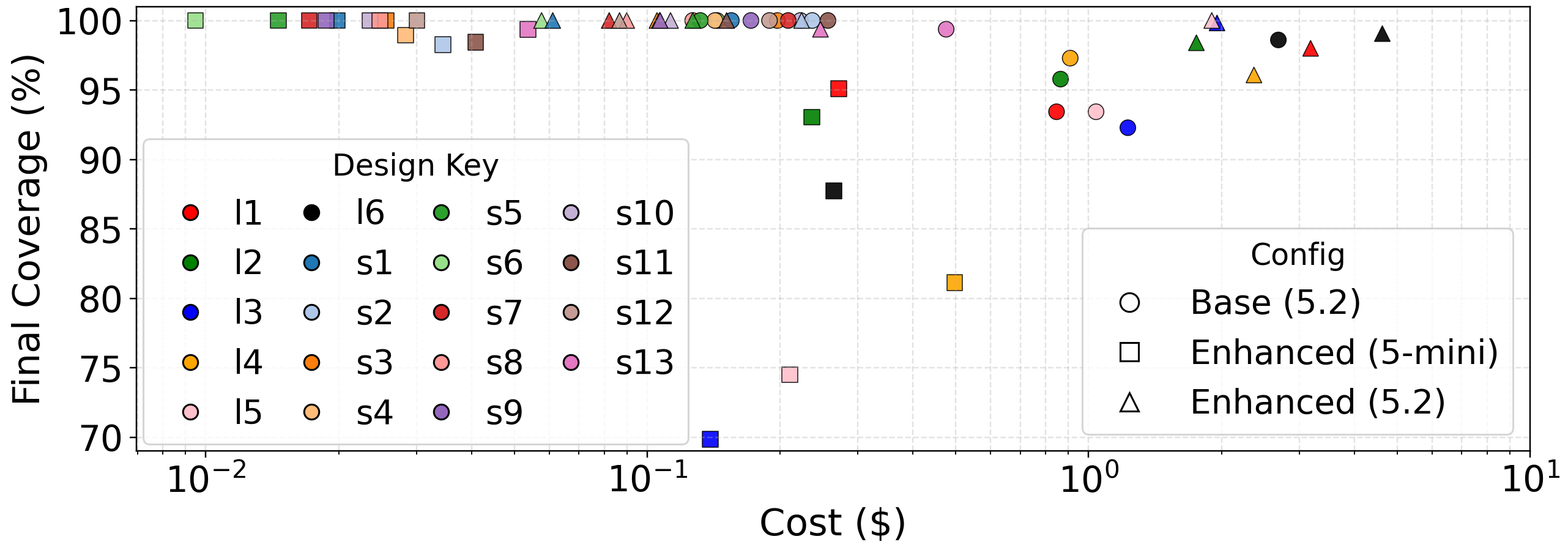
Figure 9: Coverage/cost tradeoff across agent/model configurations, demonstrating the dominant efficiency of the enhanced agent in all but the most complex scenarios.
Implications and Future Directions
The CovAgent framework is a substantial artifact for both methodology research and practical verification deployment pipelines. The hierarchical coverage hole taxonomy establishes an actionable baseline for exclusion policy and regression management, and fine-grained token profiling enables compute/cost optimization. Empirical results suggest the following implications:
- Hybrid Model Deployment: Cost-efficient, domain-specific pipelines paired with mid-size LLMs are effective for small-to-moderate RTL modules; escalation to top-tier LLMs should be reserved for coverage plateau or protocol/timing frontier holes.
- Agent Design for Hierarchical Complexity: Superlinear comprehension scaling motivates future agent designs emphasizing explicit state modeling, hierarchical summarization, or targeted protocol synthesis.
- Benchmarking and Exclusion Support: Automated structured coverage exclusion and diagnostic reporting facilitate integration into industrial regression flows.
Long-term, further work may address scaling to subsystem/top-level verification, compositional environment generation, or integration with co-verification and assertion synthesis flows.
Conclusion
"Understanding Inference-Time Token Allocation and Coverage Limits in Agentic Hardware Verification" (2604.15657) demonstrates, through the CovAgent framework, that domain-specialized agentic workflows in hardware coverage closure not only yield higher effective coverage with fewer tokens but provide actionable granularity regarding failure sources. The persistent reasoning frontiers identified—protocol sequencing and pipeline warm-up—define the next milestones for agentic verification research. Comprehensive inference-time profiling and coverage taxonomy will be instrumental as LLM-based verification systems mature and scale toward practical industrial deployment.