- The paper demonstrates that state-of-the-art agents struggle with long-horizon workflows despite accurate atomic tool-use.
- It introduces a dual pipeline with GTA-Atomic for short tasks and GTA-Workflow for complex scenarios, validated by rigorous real-world evaluations.
- Empirical analysis reveals a significant capability cliff and highlights the need for advanced execution harnesses to improve overall performance.
Benchmark Motivation and Hierarchical Design
GTA-2 addresses the misalignment between existing tool-use agent benchmarks and the requirements of authentic, real-world productivity tasks. Conventional benchmarks commonly rely on AI-generated queries and simulate tool execution as text-only environments, thereby failing to rigorously assess system-level coordination or multimodal reasoning in practical scenarios. GTA-2 establishes a hierarchical evaluation protocol that encompasses both atomic tool-use (GTA-Atomic) and complex, long-horizon workflows (GTA-Workflow), unified under stringent standards: real user queries, real deployed tools, and real multimodal inputs.
The construction pipeline exhibits a dual design philosophy. GTA-Atomic employs an expert-driven, exemplar-based expansion strategy to ensure data quality for short-horizon, well-defined tasks. GTA-Workflow leverages a semi-automated, human-in-the-loop pipeline where tasks are sourced from both agent platforms (e.g., Manus, Minimax Agent, CrewAI) and high-engagement real-world requests (e.g., Reddit, Stack Exchange). The workflow tasks are refined, augmented, and quality-checked by LLMs and humans to maximize fidelity and executability.
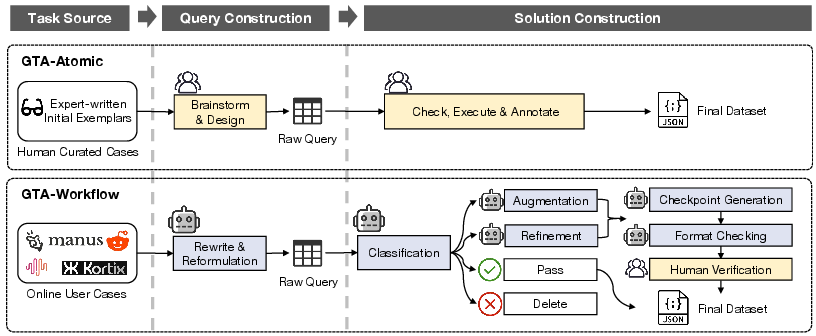
Figure 1: The dataset construction pipeline for GTA-2, with GTA-Atomic and GTA-Workflow following distinct yet authenticity-focused protocols.
Dataset Structure and Task Taxonomy
GTA-2's composition is quantitatively distinctive. GTA-Atomic includes 229 tasks, each requiring reasoning across the perception, operation, logic, and creativity axes using 14 executable tools. GTA-Workflow comprises 132 open-ended, deliverable-centric scenarios, each decomposed into a hierarchical tree of 3–19 sub-goal checkpoints and supported by a diverse set of 37 tools. Workflow tasks emphasize heterogeneous multimodal inputs and a broader array of output modalities (text, code, multimedia, structured data).
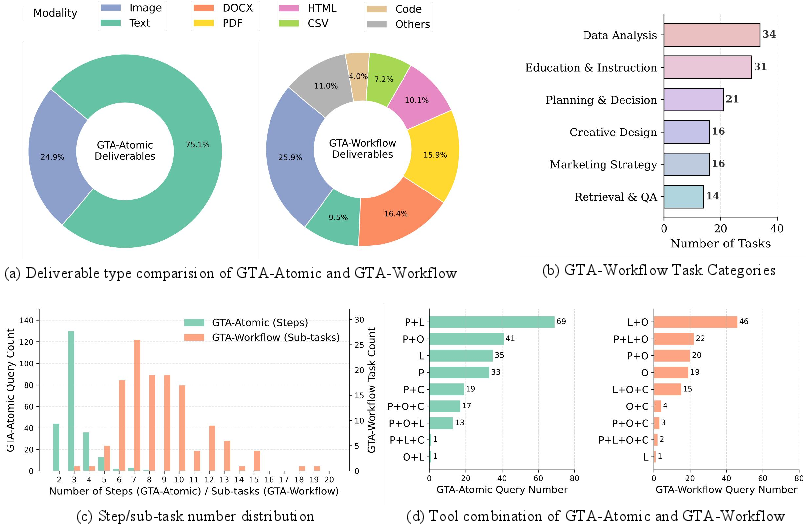
Figure 2: Overall statistics of GTA-Atomic and GTA-Workflow, highlighting the expansion in complexity, tool set, and deliverable types.
Workflow complexity scales with the number of leaf checkpoints. As the checkpoint tree’s size increases, models demonstrate a consistent performance decline, confirming that deep compositionality and extended planning horizon are primary sources of agent brittleness.
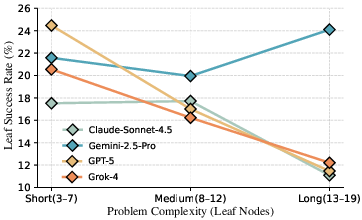
Figure 3: GTA-Workflow’s task difficulty increases with the number of leaf nodes, causing a steep drop in agent performance on long-horizon tasks.
Task performance is also modulated by deliverable type. Models achieve higher results for text-based outputs while multimedia and structured data deliverables obtain notably lower scores, reflecting the continuing difficulty in agents' robust, cross-modal synthesis and file-structured output generation.
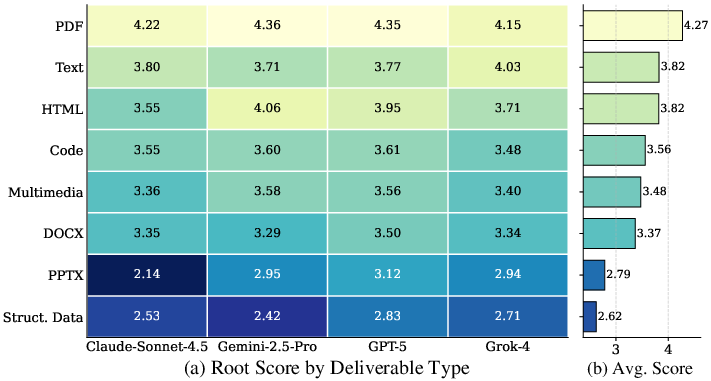
Figure 4: Agent performance in GTA-Workflow is sensitive to deliverable types, with structured and multimedia data presenting persistent challenges.
Evaluation Paradigm and Scoring Protocols
A core methodological contribution is the checkpoint-based deliverable-centric evaluation, particularly for open-ended workflows. Unlike trajectory-matching schemes, GTA-Workflow decomposes each task into a tree of verifiable, outcome-oriented checkpoints. A strong LLM (GPT-5.2) acts as the primary judge, recursively aggregating sub-goal scores into a root score for the final deliverable, thus enabling consistent and granular quantitative assessment.
The evaluation demonstrates robust agreement between LLM judges and humans. Root- and leaf-level scores exhibit high correlation (Pearson > 0.96 and ICC > 0.92), and the ranking of models is stable across LLM judge substitutions, indicating negligible judge-induced bias.
Success rate thresholds were analyzed for discriminability; k=7 on the [0,10] scale is shown to optimally stratify model performance.
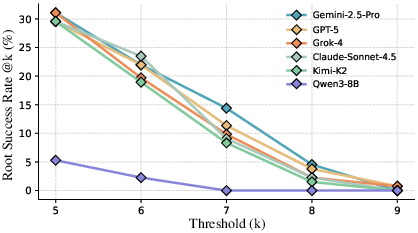
Figure 5: Root SR (success rate) sensitivity to different scoring thresholds, demonstrating the choice of k=7 maximizes discriminability.
Empirical Findings: Model and Harness Analysis
GTA-2 exposes a pronounced capability cliff across both atomic and workflow tasks. On GTA-Atomic, leading models (GPT-4, GPT-4o) do not exceed 50% accuracy, with open-source models trailing significantly. For GTA-Workflow, all models—including top-tier proprietary and open-source architectures—exhibit drastic performance collapse. Gemini-2.5-Pro achieves the highest root success rate yet only 14.39%, despite over 91% tool invocation correctness. This decoupling of tool-use accuracy from systemic workflow success underscores the unique difficulty of maintaining coherence, context, and error tolerance in long-horizon tasks.
Advanced execution frameworks are shown to substantially mitigate task failure. OpenClaw and Manus, for instance, reach workflow root scores of ~6.8–6.9 (out of 10) and operational success rates above 50%, in stark contrast to the default Lagent setup. These harnesses markedly reduce compositional and integration failures, especially at the mid-level (sub-goal assembly), but final deliverable errors—particularly in formatting, packaging, and compliance—remain predominant even with advanced harnesses.
Granular Error Analysis
Error decomposition reveals that failures for LLM-based agents on workflows are primarily system-level rather than purely local. The majority of agent breakdowns are traced to execution instability (e.g., brittle multi-step tool interaction), deliverable assembly, and output formatting. Reasoning and local step errors (i.e., failures not achieving sub-goal correctness) constitute a minority. Composition failures (mid-level) are largely alleviated by structured harnesses, while deliverable failures persist, indicating the bottleneck has shifted from local inference to global task realization and artifact compliance.
Cross-Domain and Efficiency Trends
Model performance varies by workflow domain, with no single model dominating across Retrieval, QA, Creative Design, Data Analysis, Education, or Marketing scenarios. Frontier models exhibit relative strengths in structured reasoning and perception, while creativity and operation-heavy tasks remain most challenging. Category-specific analysis reveals continued gaps in cross-modal and structured data outputs.
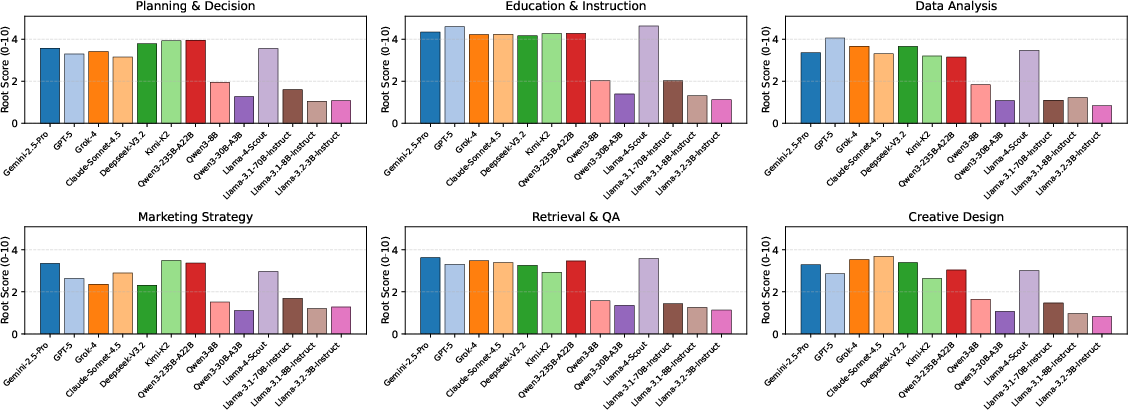
Figure 6: Domain-specific breakdowns of model performance in GTA-Workflow, with large inter-model and inter-domain variance.
A Pareto analysis of efficiency (step count vs. success rate) reveals that efficiency is not solely a function of step count—some models achieve more with fewer steps due to superior planning and reduced error loops. Gemini-2.5-Pro and Llama-4-Scout exemplify optimal trade-offs, whereas weaker agents exhibit degenerate, high-action, low-yield behaviors.
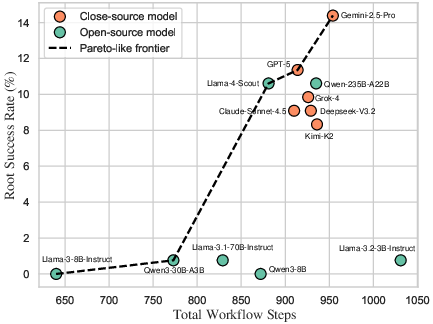
Figure 7: Relationship between model efficiency and workflow task success, illustrating the divergence between high- and low-performing agents.
Practical and Theoretical Implications
Practically, GTA-2 demonstrates that tool-use accuracy is a necessary but insufficient criterion for agent reliability in real-world autonomous settings. Success in atomic tasks does not transfer to open-ended workflows without advances in execution harnesses, persistent memory architectures, and robust compositional reasoning. The efficacy of advanced harnesses in boosting mid-level integration success predicates future agent development on systemic—rather than exclusively model-centric—innovation.
Theoretically, the pronounced performance collapse and error causality revealed by GTA-2 point toward open research questions: (1) What architectural innovations can close the gap between local instrumentation and holistic deliverable production? (2) How can agent evaluation protocols balance outcome-centric rigor with transparency and reproducibility? (3) What causal factors underlie persistent deliverable-level failures beyond composition stabilization?
GTA-2 also motivates further inquiry into multimodal and cross-modal reasoning, given persistent challenges in structured and multimedia deliverable synthesis, and calls for expanded evaluation along safety, privacy, and real-world deployment axes.
Conclusion
GTA-2 establishes a rigorous, unified benchmark for evaluating general tool agents across atomic and long-horizon open-ended workflows. It conclusively demonstrates a significant gap between state-of-the-art LLM agent capabilities and the demands of realistic, reliable automation. The findings indicate that progress in reliable AI agents will depend equally on advancements in model reasoning and in the engineering of execution frameworks that drive robust, end-to-end deliverable realization. GTA-2 provides a foundation for systematic, diagnostic, and fair assessment necessary for future development of professional autonomous agents and sets forth a compelling research agenda for the community (2604.15715).