- The paper demonstrates that attention modules in GPT-NeoX-20B explicitly propagate numeric and operator information, which is essential for constructing arithmetic solutions.
- It reveals that early layer activations indicate numeric awareness while correct results emerge in late MLP stages, supporting a modular, stepwise computation process.
- Comparative analysis shows that models like GPT-2 XL lack systematic operand routing, resulting in noisy predictions and limited arithmetic proficiency.
Dissecting Mathematical Reasoning in LLMs
Introduction
"Disentangling Mathematical Reasoning in LLMs: A Methodological Investigation of Internal Mechanisms" (2604.15842) presents a systematic interpretability-driven study of how decoder-only LLMs perform elementary arithmetic. Using early decoding ("logit lens"), the authors probe intermediate layer activations in GPT-NeoX-20B (arithmetic-proficient) and GPT-2 XL (arithmetic-poor) to identify when and how these models recognize arithmetic tasks, propagate numerical content, and generate correct results. The work advances mechanistic understanding of reasoning-intensive tasks in transformers, contrasting models with distinct arithmetic capabilities and explicitly characterizing sub-network division of labor.
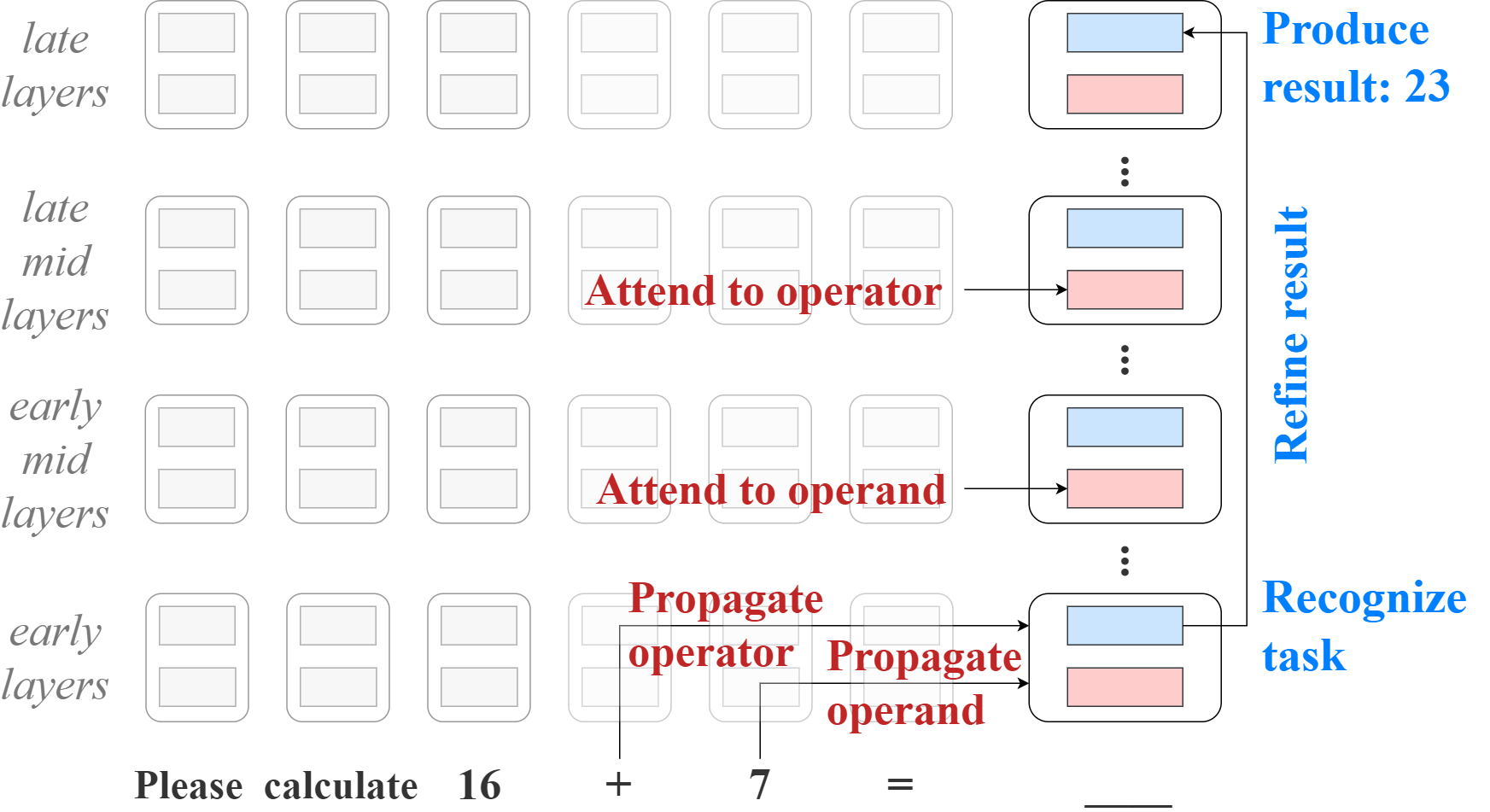
Figure 1: Visualization of the model-internal mechanisms during mathematical reasoning in a transformer; attention blocks are red, MLP blocks blue.
Methodology: Early Decoding as a Mechanistic Probe
The analysis leverages early decoding, projecting the residual stream after each attention or MLP sublayer into vocabulary space via the language modeling head. This de-embedding exposes the evolution of next-token probabilities through the forward pass, permitting direct attribution of incremental predictions to specific modules. The workflow is visualized in Figure 2.
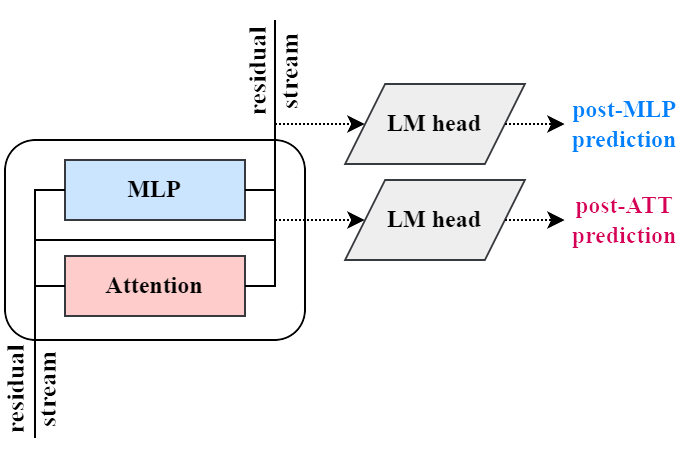
Figure 2: The early decoding process, showing intermediate decoding immediately after the attention and MLP updates to the residual stream.
The experimental protocol uses synthetically generated prompts of the form "Please calculate op1 ∘ op2 =", with controlled operand/results size for addition and subtraction. Crucially, the number vocabulary is constrained to guarantee single-token representations, minimizing confounds from tokenization.
Task Recognition and Result Generation Dynamics
Early Numeric Awareness
Early in the network, GPT-NeoX-20B recognizes the need for a numerical result. The probability mass assigned to numerical tokens in post-MLP predictions rises abruptly within the first one-third of layers, signifying swift task-type recognition.
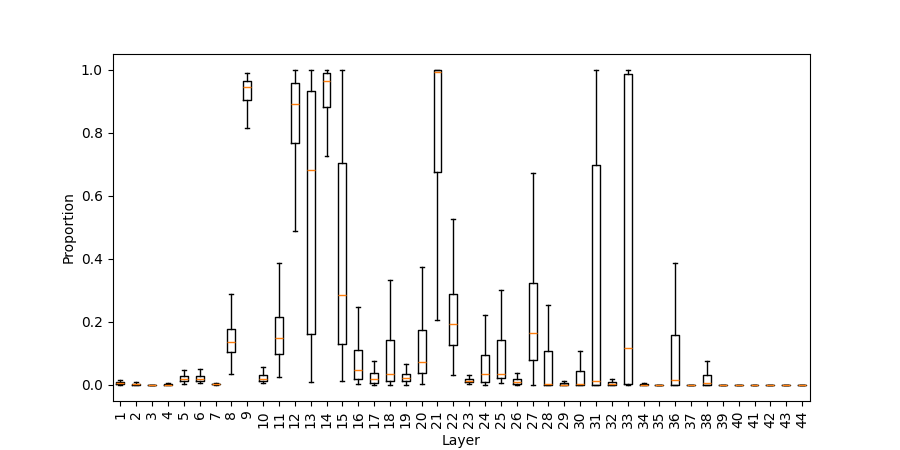
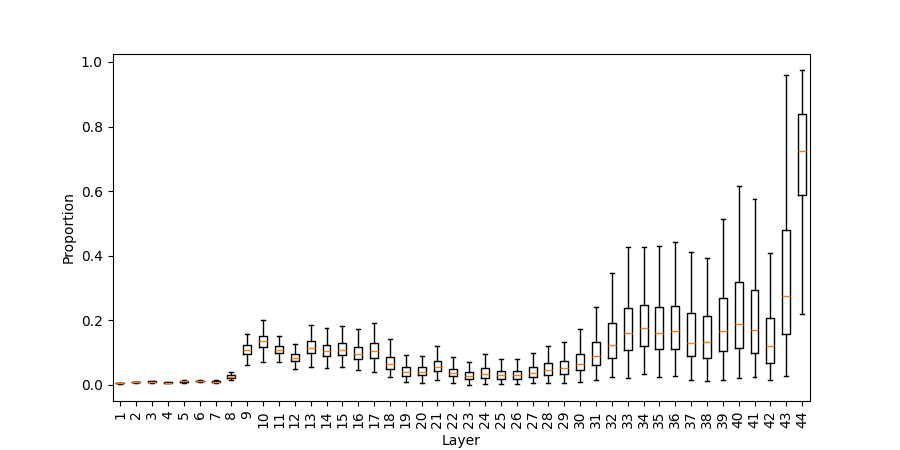
Figure 3: Probability mass on numerical tokens across layers in post-ATT and post-MLP predictions (addlarge).
Late Commitment to the Solution
Despite early numeric priming, the correct result itself is not synthesized until very late layers. Post-MLP top-1 predictions are rarely numerical before the deepest block, and the correct sum generally appears at top rank only in the final module stages. Error curves confirm that intermediate numerical predictions are largely uncorrelated with correctness until late:
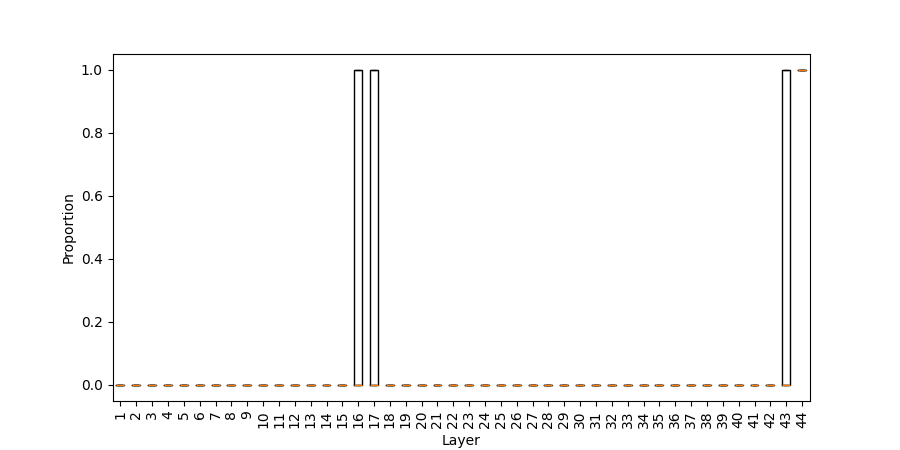
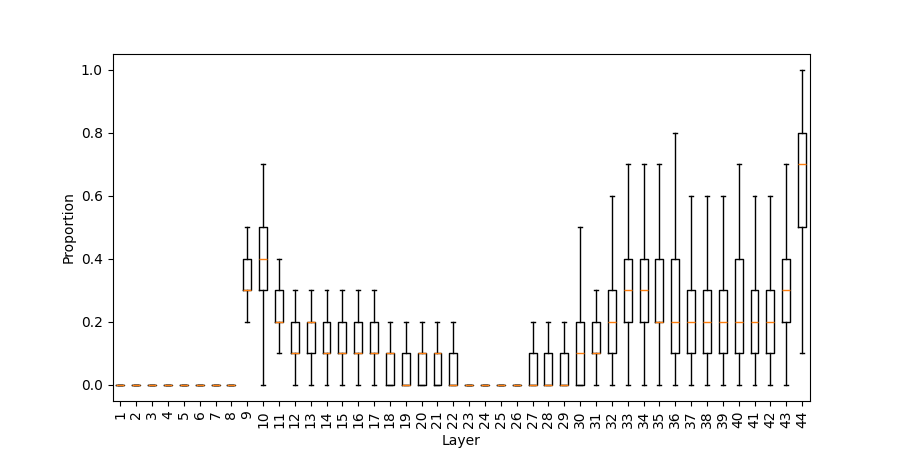
Figure 4: Proportion of numerical tokens in top 1/10 post-MLP intermediate predictions across layers (addlarge).
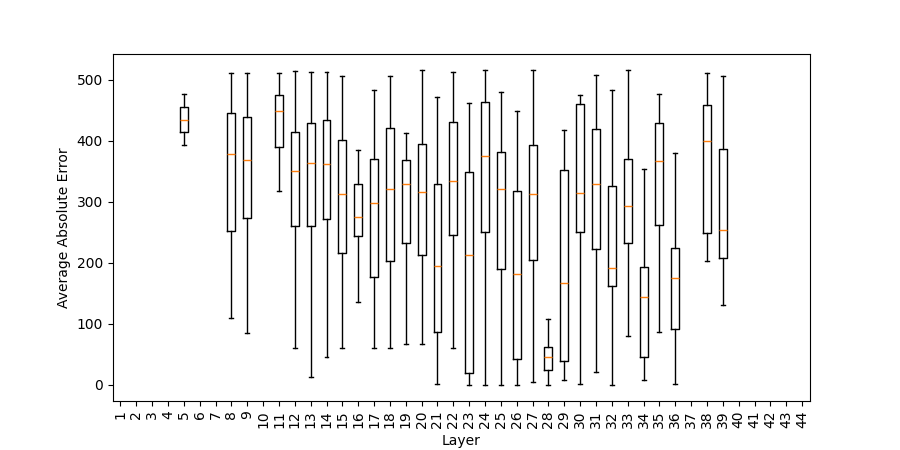
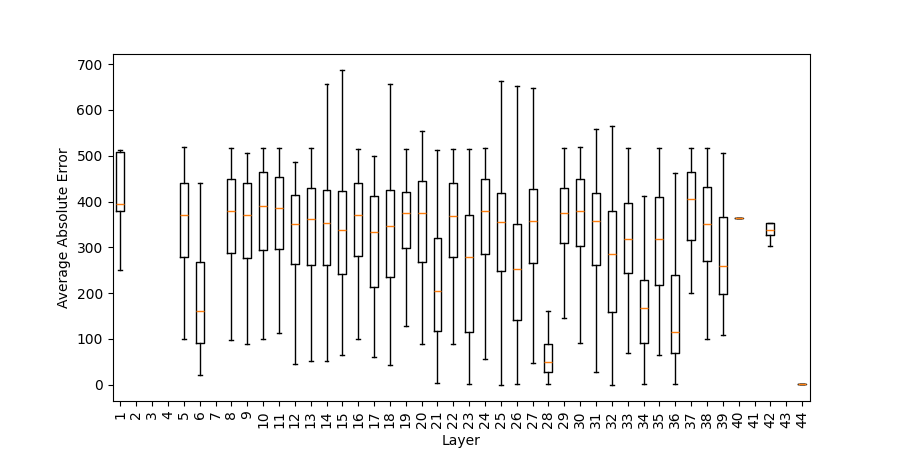
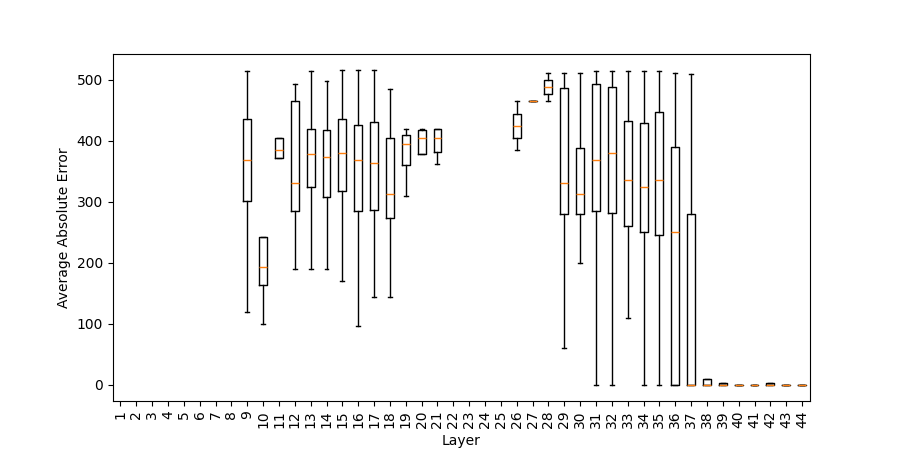
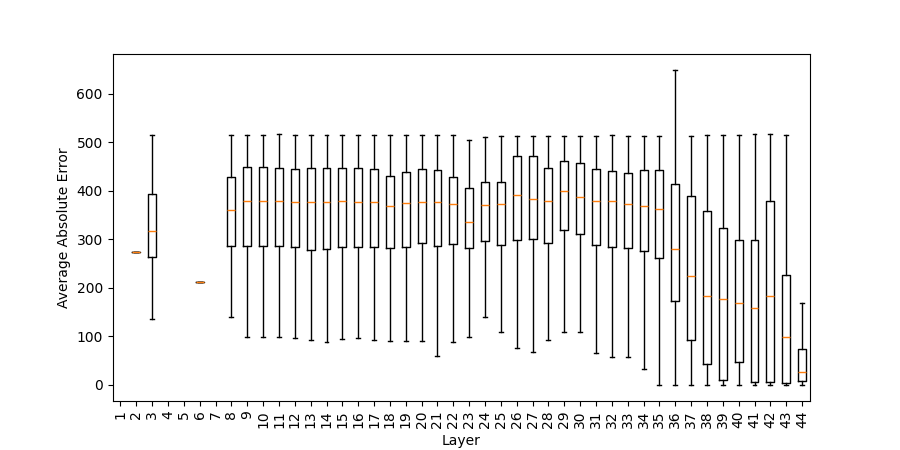
Figure 5: Absolute error of numerical tokens (difference to correct result) in top 1/10 post-ATT and post-MLP intermediate predictions (addlarge).
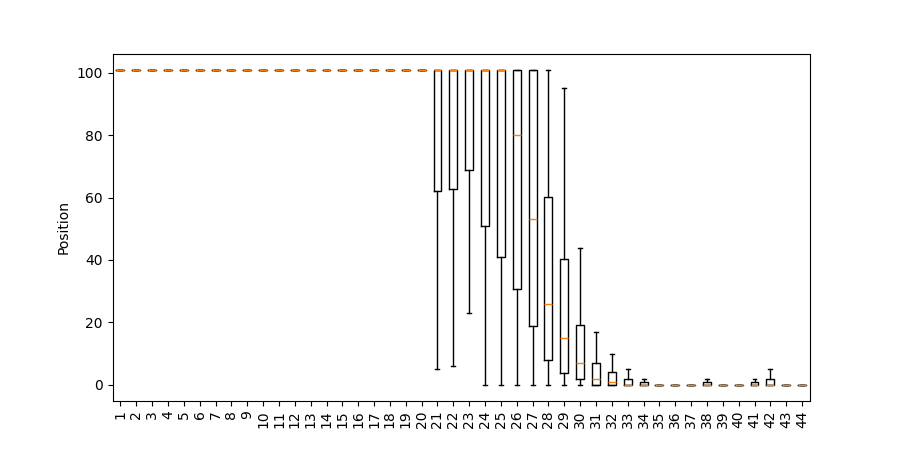
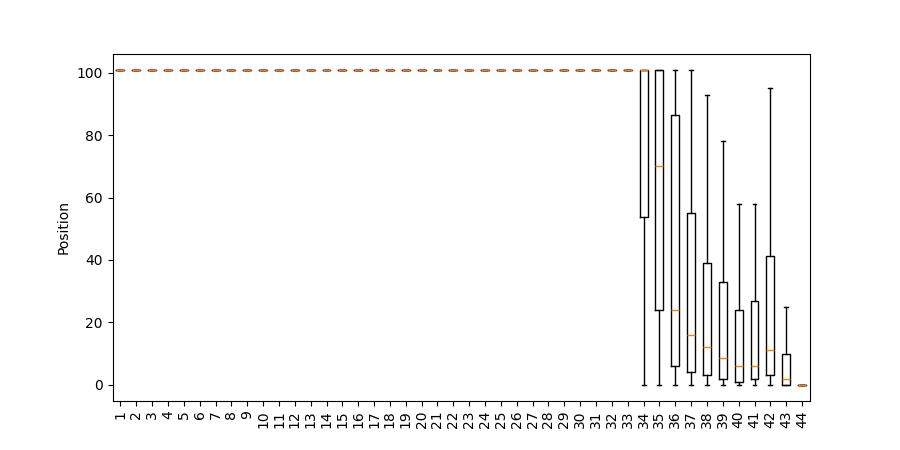
Figure 6: Position of the correct result among predicted tokens in post-MLP predictions, addsmall and addlarge.
Notably, for easier instances, the correct token appears earlier. This task-complexity dependence suggests a functional, not purely rote, mechanism for mathematical processing.
Distinct attention modules are responsible for propagating operand (input number) information toward the final token position, as evidenced by spikes in numerical probability mass at specific layers in post-ATT decoding. For each operand, a nontrivial fraction of prompts elicit rank 1 predictions at discrete mid-network layers, localized near layers 21.
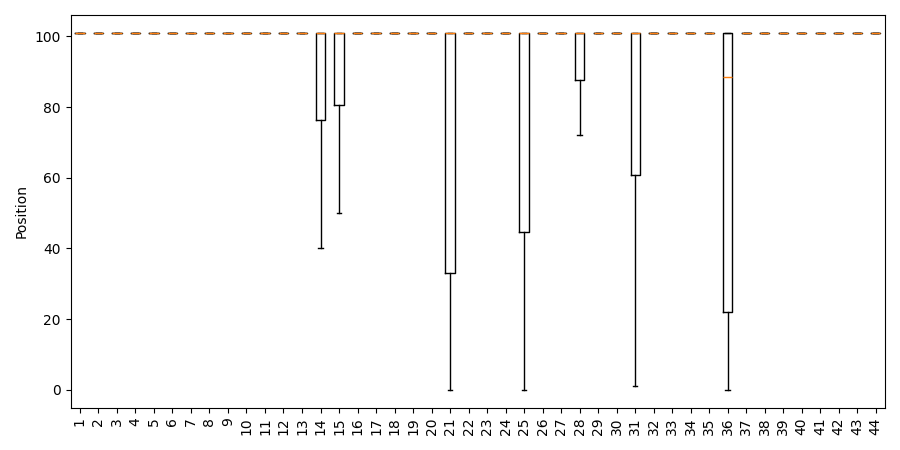
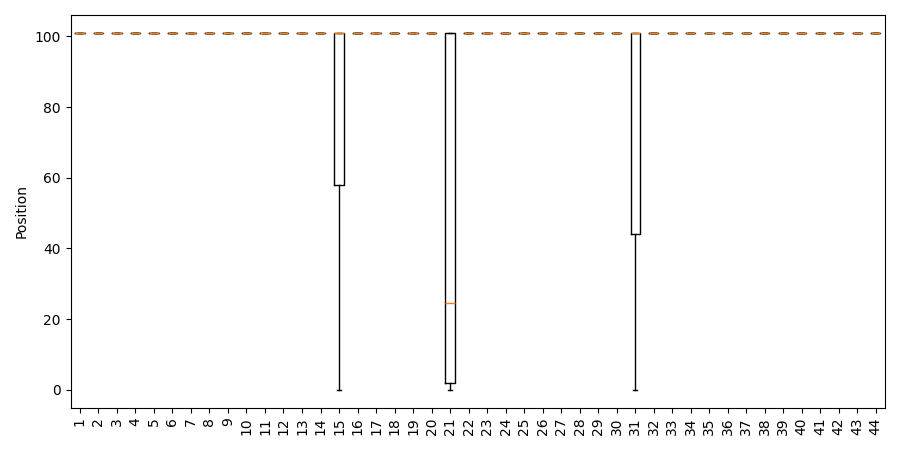
Figure 7: Layerwise position of (a) operand 1 and (b) operand 2 in post-ATT predictions (addlarge).
However, the model exhibits mutually exclusive operand propagation in 64% of cases: usually, only one operand is explicitly attended to as the top prediction in any given forward pass. The other must be preserved in the residual stream implicitly, indicating a functional, argument-transforming paradigm rather than pure memorization.
Operator and Task Marker Routing
The operator token ("+") also becomes highly probable at a specific late attention module (layer 37), aligning temporally with the emergence of the correct result in MLP predictions. Other task-relevant cues (e.g. "answ") surface immediately preceding solution readout.
Mechanistic Causality: Interventions
Interchange intervention experiments systematically substitute the attention output for a given token/layer between base/source prompts differing by one operand or operator. Results show sharp drops in probability assigned to the correct result, especially for interventions in specific early-mid attention layers (12-19). This confirms that operand/operator information is not simply present but necessary for correct solution construction in identified modules.
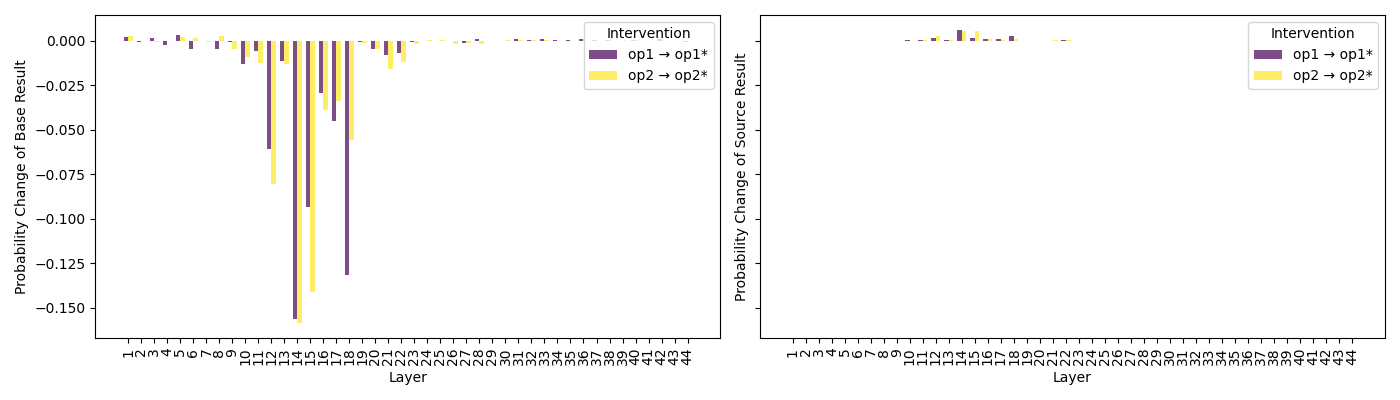
Figure 8: Impact of operand interchange interventions on (left) base result probability and (right) source result probability across layers (addlarge).
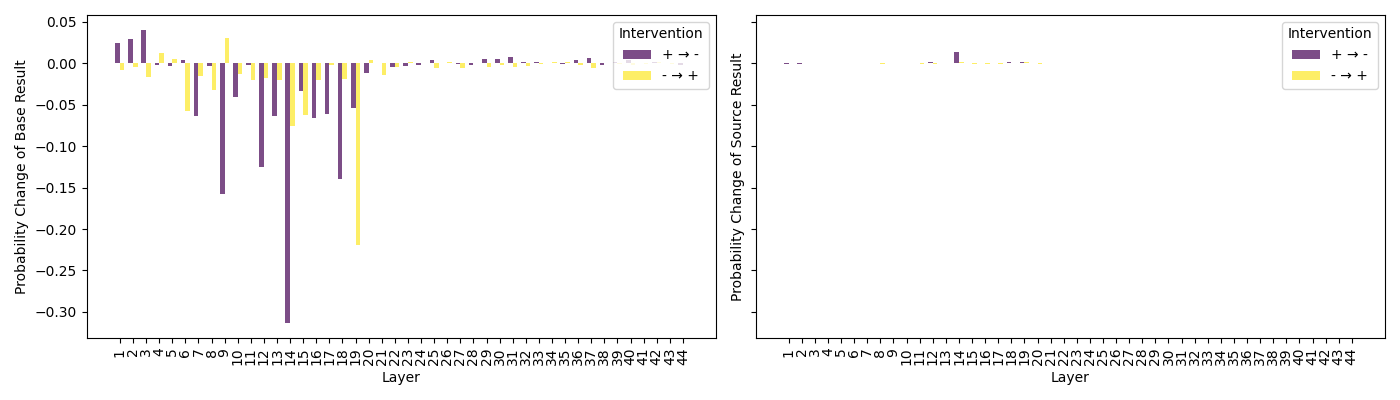
Figure 9: Operator intervention effects for addition and subtraction, showing substantial mediation in early-mid layers.
Limitations of Arithmetic Generalization
GPT-NeoX-20B’s proficiency with two-operand arithmetic does not extend robustly to three-operand tasks or more complex operations. Performance collapses (accuracy ≤12%) when required to route multiple operands/operators simultaneously. Analysis reveals that only one or two input elements are explicitly propagated, often insufficient for multi-step computation—highlighting bottlenecks in functional abstraction and reasoning depth.
Comparative Analysis: Role of Model Scale and Architecture
The division of labor between attention (information routing) and MLP (integration/aggregation) sub-networks is absent in GPT-2 XL, the arithmetic-poor model. Intermediate predictions remain noisy and unsystematic; neither the task-type nor operands/results are reliably surfaced in the residual stream at any layer.
Implications and Theoretical Perspectives
This work substantiates a functional account of arithmetic reasoning in LLMs: successful models segregate the roles of attention (propagation/selective loading) and MLPs (aggregation, transformation) in line with theories of modular computation [geva-etal-2023-dissecting, stolfo_mechanistic_2023]. The delayed emergence of correct solutions and the mutual exclusivity in operand routing supports a "systematic transformation" perspective over a pure recall/memorization strategy.
These empirical findings bolster the interpretation of reasoning as sequential, module-specific computation with explicit and implicit state (argument-passing), a contrast to the “bag of heuristics” hypothesis [nikankin2024arithmetic]. They also expose limitations: even state-of-the-art LLMs fail to robustly generalize to deeper/multi-operand arithmetic, consistent with scaling law breakdowns and the challenges of compositional generalization [zhou2023algorithmstransformerslearnstudy, thomm_limits_2024].
Conclusion
"Disentangling Mathematical Reasoning in LLMs" (2604.15842) provides precise, layer-resolved evidence that transformer LLMs like GPT-NeoX-20B employ a distinct computational pipeline for mathematical reasoning: attention modules explicitly propagate input numeric information, operators, and task markers, upon which late-stage MLP modules operate to generate the correct result, predominantly in the final layers. Lesser models lack this functional organization and fail at even elementary arithmetic. The results challenge explanations based on rote memorization and pattern matching, instead highlighting modular, functional computation as an enabling mechanism for LLM reasoning. These findings have significant implications for interpretability, the design of future LLMs, and the prospects for expanding arithmetic proficiency to deeper reasoning tasks, suggesting further research into architectural enhancements and targeted interventions may be necessary to overcome current limitations.