- The paper presents a multi-turn, bidirectional approach to reward modeling that integrates forward and backward verifiers for enhanced logical reasoning.
- The paper demonstrates significant accuracy improvements on benchmarks like MATH500 and shows superior correction rates in iterative revision tasks.
- The paper validates that tool integration and structured agent collaboration mitigate error propagation in chain-of-thought reasoning.
Agentic Reward Modeling via Multi-Turn, Bidirectional Verification: An Analysis of AgentV-RL
Motivation and Problem Analysis
Reward modeling (RM) is a critical mechanism underpinning LLM alignment frameworks—especially in settings involving reasoning, code generation, or mathematics. Traditional outcome-level reward models (ORMs), which generate scalar preferences over entire solutions, and process-level reward models (PRMs), which provide step-level feedback, both suffer from issues of limited granularity, interpretability, and insufficient robustness for complex, chain-of-thought (CoT) reasoning. Generative reward models (GenRMs) attempt to generate natural-language rationale as supervision but are prone to error propagation and lack external grounding, leading to false positives when solutions are superficially plausible yet incorrect.
The AgentV-RL framework introduces the Agentic Verifier, a paradigm shift in reward modeling. Rather than treating verification as a static, single-turn operation, Agentic Verifier orchestrates two complementary agent roles—forward and backward—each performing multi-turn, tool-augmented, deliberative reasoning.
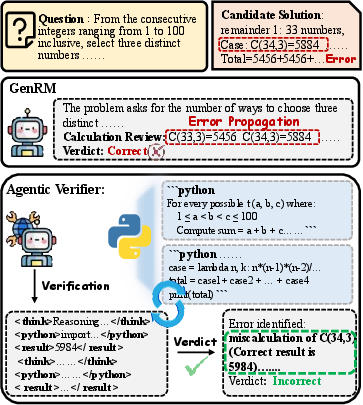
Figure 1: Comparison between GenRM and Agentic Verifier, highlighting the mitigation of error propagation and enhancement via external grounding.
Agentic Verifier Architecture
The Agentic Verifier is structured around a bidirectional, multi-agent process:
- Forward agent: Sequentially checks logical sufficiency by following the solution from premises to conclusion, decomposing reasoning into atomic steps, and validating each through internal reasoning and external (e.g., Python) tools as needed.
- Backward agent: Initiates from the claimed final conclusion and traces back to verify necessity—ensuring the solution is grounded in original constraints and accounts for omissions or logically unwarranted inferences.
This design is realized in a multi-stage pipeline:
- Planning: The agent decomposes the task into verifiable substeps.
- Validation: Iterative, tool-augmented checks on each substep using code execution when required.
- Verdict: Aggregation of stepwise evidence into a global binary assessment, outputting both a natural language critique and a confidence score.
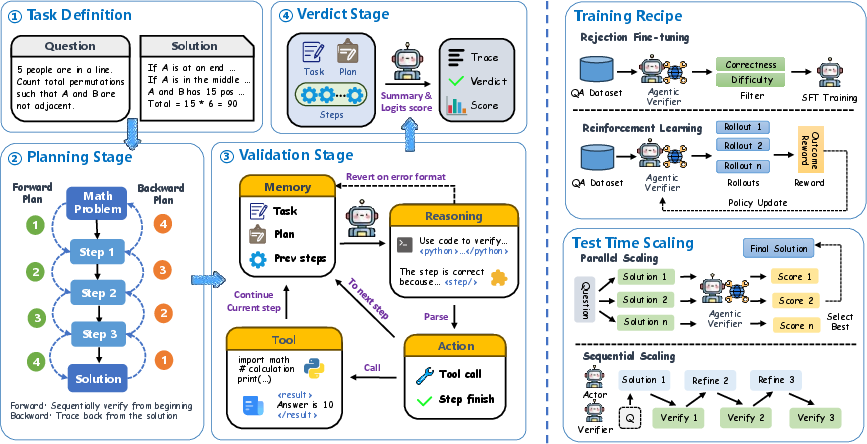
Figure 2: Architectural overview showing coordination of forward and backward agents, supporting multi-turn, tool-augmented verification processes.
Training Pipeline: AgentV-RL
To distill these agentic behaviors into a single LLM, AgentV-RL proposes a two-stage training pipeline leveraging a synthetic data engine and reinforcement learning:
- Synthetic Trajectory Generation: A scalable synthetic data generator automatically samples diverse questions, solutions (correct/incorrect), and verifies multi-turn, tool-integrated verification traces. Only trajectories whose verdicts align with ground truth are retained, ensuring high-quality supervision and comprehensive coverage of challenging reasoning types.
- Two-Stage Training:
- Supervised Fine-Tuning (SFT): The verifier LLM is fine-tuned to reproduce demonstration verification trajectories, aligning model behavior with the agentic decomposition and tool use.
- Group Relative Policy Optimization (GRPO): RL optimization incentivizes exploration of the verification space, enabling learning of long-horizon, multi-turn, and tool-integrated policies. Tool invocations are explicitly modeled and capped to prevent degenerate behaviors.
Empirical Results
AgentV-RL is evaluated on extensive mathematical and reasoning benchmarks under both Best-of-N (BoN) selection and sequential refinement (verifier-actor cycles).
Best-of-N Sampling:
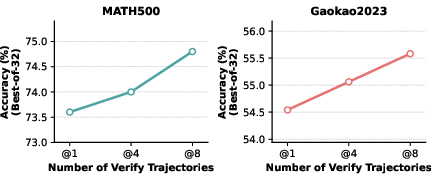
The Agentic Verifier (Qwen3-4B) demonstrates state-of-the-art accuracy, e.g., achieving up to 79.0% on MATH500, outperforming the best ORM (Skywork-V2-Llama-8B) by a margin of 25.2 percentage points, and with consistently strong results across GSM8K, Gaokao2023, and AIME24. Performance scales positively with the number of sampled solutions and the amount of compute allocated to verification.
Verifier Guidance for Iterative Refinement:
When serving as the critique model in sequential revision, Agentic Verifier yields high correction rates in the first iteration (e.g., 41.6% Δ↑ on MATH500 for iteration 1) with minimal regression, converging faster and maintaining stability compared to other verifiers.
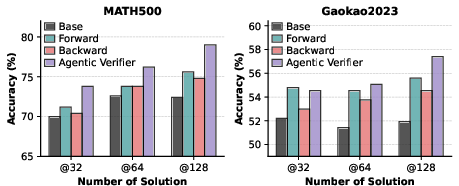
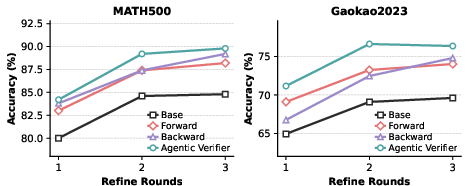
Figure 3: Ablation comparing Best-of-N and verifier-revision variants; the integration of both agents delivers the best results.
Ablative Analysis:
- Both the forward- and backward-only agent variants are competitive, but their synergy in the full bidirectional system yields superior generalization and reliability, confirming the theoretical motivation.
- Tool integration confers additional accuracy, especially on computation-heavy problems, but much of the benefit derives from the structured, multi-turn agentic verification procedure itself, with moderate tool usage sufficing (median 1–2 calls per sample).
Training Strategy:
Supervised fine-tuning alone offers notable gains over train-free variants, and combining with RL further boosts performance—demonstrating the efficacy of direct trajectory-level exploration.
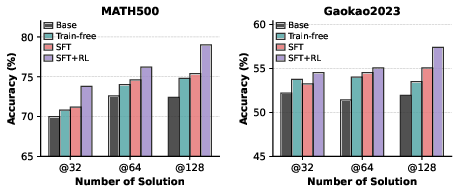
Figure 4: Training recipe study demonstrating that SFT+RL achieves the strongest improvements in BoN performance.
Scaling Effects:
Generalization:
Agentic Verifier achieves superior results on LiveCodeBench and HotpotQA, highlighting robustness outside mathematics and confirming the generality of bidirectional, tool-augmented agentic verification.
Implications and Theoretical Insights
The Agentic Verifier paradigm evidences that static or unidirectional RMs are insufficient for robust solution evaluation, especially for mathematical and chain-of-thought settings. Integrating multi-turn, bidirectional reasoning and grounding via external tools directly into the RM allows the detection and tracing of complex error modes—preventing the error propagation that plagues single-pass verifiers.
Tool augmentation, while beneficial, is not the sole driver of improved generalization: the agentic, structured, multi-stage decomposition is essential. AgentV-RL’s approach aligns naturally with human-in-the-loop verification workflows and offers a blueprint for future RMs that must operate in domains with high logical or computational density.
Practically, the increased computational overhead of multi-turn, deliberative verification poses challenges for real-time or resource-constrained applications, but the modular agent structure allows scalable trade-offs (e.g., using forward/backward agents in isolation).
Future Directions
This work suggests several promising directions:
- Further agent specialization: Embedding additional specialized agents for retrieval, symbolic computation, or factuality checking could extend coverage to multimodal or deeply knowledge-intensive settings.
- Tool ecosystem expansion: Broader integration of diverse external tools and APIs would improve robustness, but also raise new challenges in reliability and security.
- Few-shot and transfer learning: Adapting the agentic verification skill to out-of-domain reasoning tasks with minimal demonstration remains a critical avenue for enhancing generalization.
On the theoretical side, the success of explicit decomposition and bidirectional checking motivates formal studies on error modes under various agent aggregation and reasoning orchestration schemes.
Conclusion
AgentV-RL formalizes and operationalizes reward modeling as a multi-turn, bidirectional, agentic process, augmenting reasoning models with interpretable, tool-grounded verification capabilities. Empirical evidence supports robust gains in both parallel (BoN) and sequential (iterative critique) settings, achieving superior accuracy and correction rates with scalable real-world applicability. The paradigm provides a compelling framework for next-generation reward modeling and solution verification architectures in advanced LLM systems (2604.16004).