- The paper introduces MEDLEY-BENCH, demonstrating that increasing model scale improves evaluation ability while control remains flat, challenging traditional scaling assumptions.
- It employs a three-step protocol—solo, private, and social—and uses rule-based and judge-based scoring to derive detailed metacognitive scores (MMS and MAS).
- The study highlights practical implications by identifying vulnerabilities to social pressure and recommending ensemble strategies for robust, calibrated AI deployment.
Introduction and Framework
"MEDLEY-BENCH: Scale Buys Evaluation but Not Control in AI Metacognition" (2604.16009) introduces MEDLEY-BENCH, a benchmark specifically designed to evaluate behavioural metacognition in LLMs. Metacognition is operationalized in terms of four sub-abilities (Monitoring, Control, Evaluation, Self-regulation) aligned with Nelson and Narens’s framework and the DeepMind cognitive taxonomy. MEDLEY-BENCH separates independent reasoning, private self-revision, and socially influenced revision by genuine inter-model disagreement, providing a fine-grained analysis that is methodologically orthogonal to classic accuracy-focused benchmarks.
The benchmark employs a three-step protocol:
- Solo (Step A): Independent analysis.
- Private (Step B-Private): Structured self-review nudge, isolating self-revision without social input.
- Social (Step B-Social): Exposure to responses and consensus from eight anonymised analyst models.
Unique in its design, MEDLEY-BENCH builds on genuine ambiguity and real inter-model disagreement, avoiding synthetic conflict. It evaluates models on 130 instances across five domains (medical diagnosis, system troubleshooting, code review, architecture design, statistical reasoning), using both rule-based and judge-based scoring to derive the Medley Metacognition Score (MMS) and Medley Ability Score (MAS).
Evaluation–Control Dissociation and Scaling Effects
A central empirical result is the dissociation between metacognitive evaluation and control with respect to model scale. Analysis across 35 models from 12 families demonstrates that evaluation (i.e., the ability to assess reasoning quality) increases with model scale, but control (the capacity to adjust strategy or resist unjustified consensus pressure) does not.
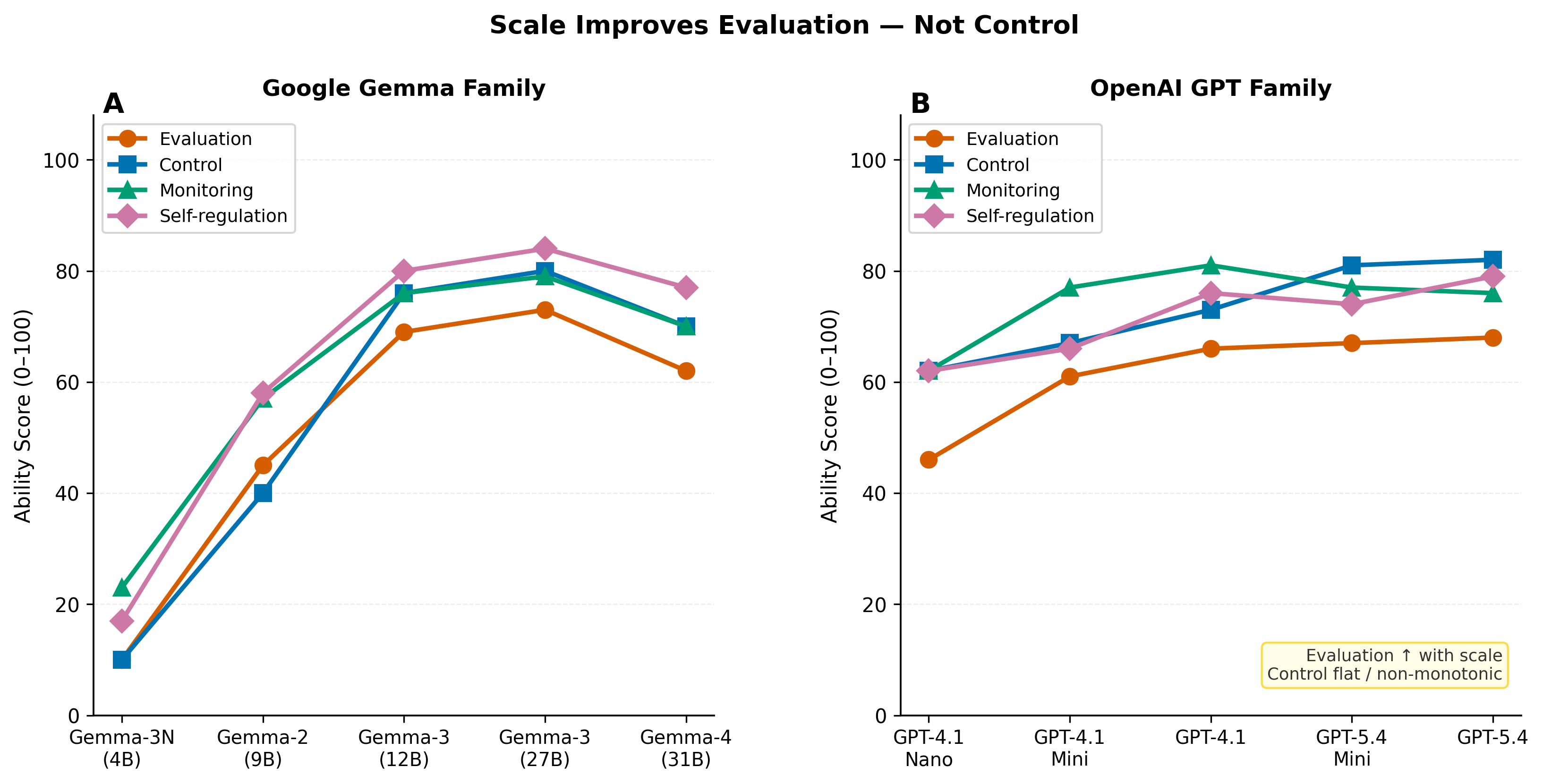
Figure 1: Evaluation ability rises consistently with model size, while control remains flat or inconsistent across model generations.
For example, in the Gemma family, evaluation ability improves monotonically from Gemma-3N (4B) through Gemma-3 (27B), yet control remains nearly constant and drops in the newest variants. Similar dissociation is observed within the GPT family. These results directly contradict the conventional assumption that scaling LLMs uniformly enhances all cognitive-related abilities.
Several numerical highlights:
- Smaller models, such as Claude Haiku 4.5, ranked first in MMS (62.2), surpassing larger and more expensive models.
- GEMMA-3 (12B) closely matches GEMMA-3 (27B) and overtakes GEMMA-4 (31B) in metacognitive quality, illustrating non-monotonicity of competence with model scale.
Social Pressure, Behavioural Profiles, and Predictive Dimensions
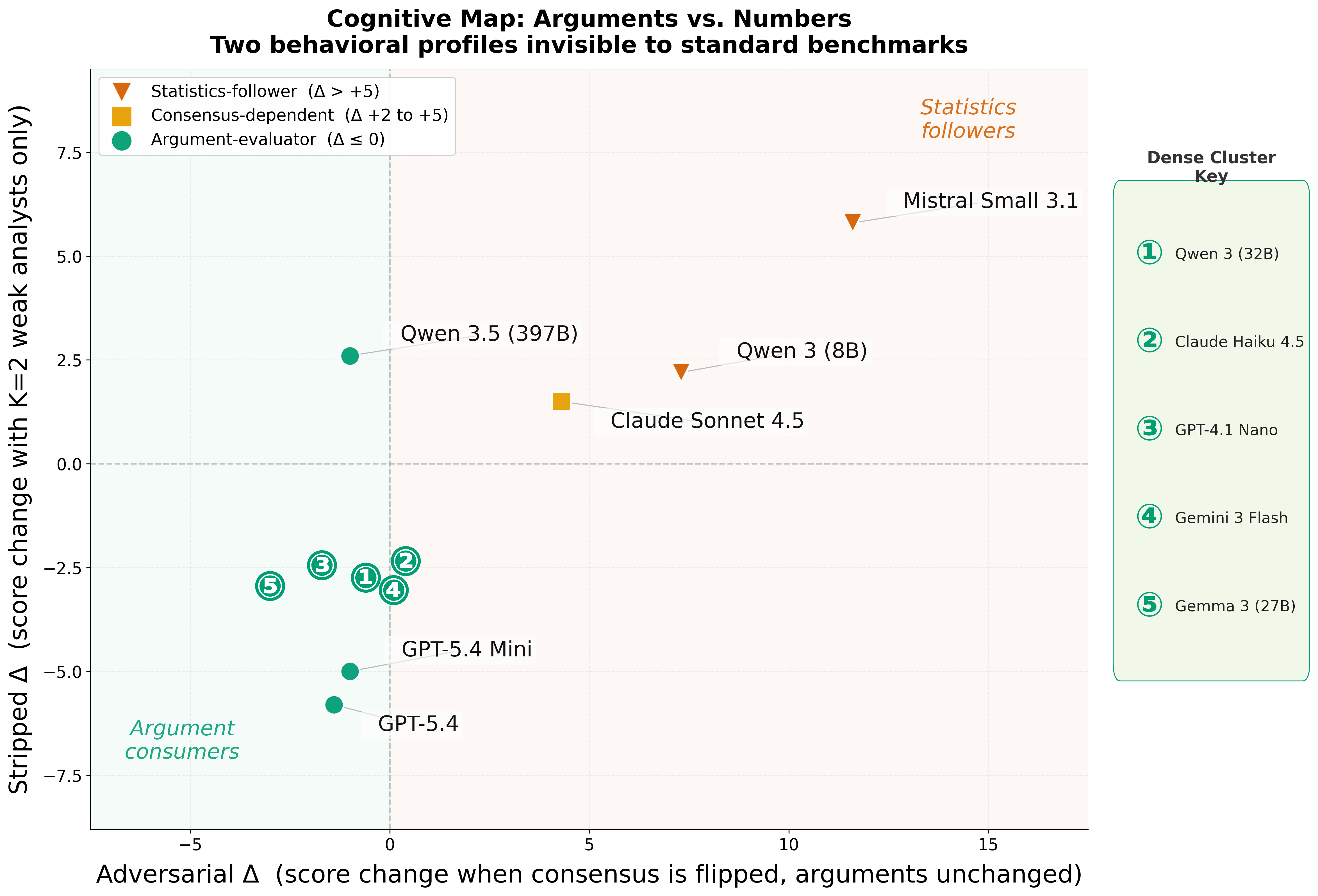
The progressive adversarial stage scrutinizes how models revise beliefs under manipulated consensus signals. This stage reveals two distinct behavioural profiles:
No model occupies the off-diagonal quadrants of the two-dimensional cognitive map, indicating that argument-evaluation and analyst-dependence are manifestations of the same underlying source monitoring capability.
Further, cross-validation identifies that the Normative/Informational judge dimension in normal mode robustly predicts adversarial susceptibility:
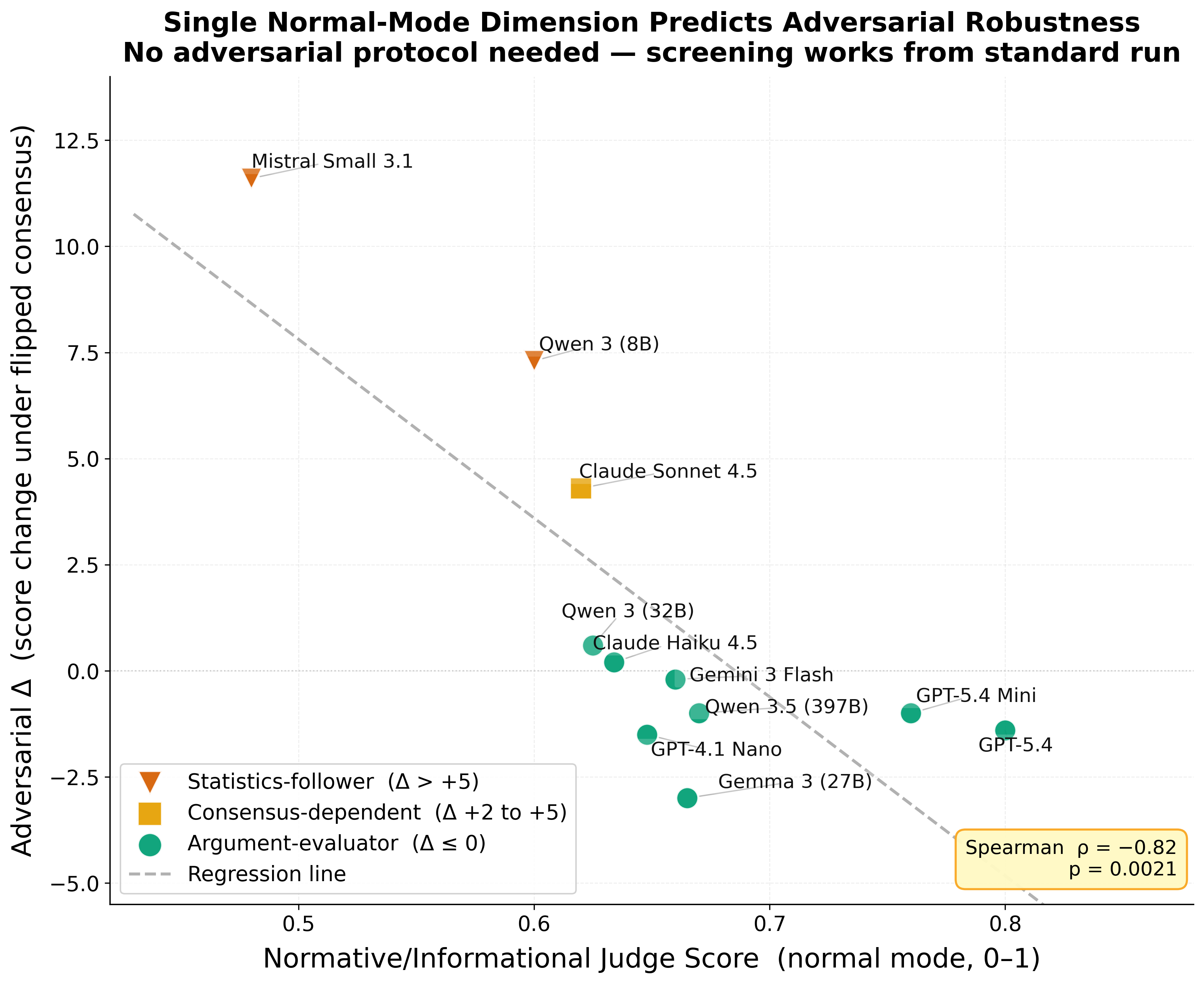
Figure 3: Only the Normative vs Informational judge dimension significantly correlates with adversarial pressure sensitivity (ρ=−0.82).
Models citing “most analysts agree” in normal mode capitulate under adversarial conditions, while those citing specific arguments resist. This critical dimension provides an actionable deployment signal for screening models based on vulnerability to social pressure.
Ipsative Profiling and Universal Evaluation Deficit
Applying ipsative scoring to decouple the dominant general articulation factor shows family-level specialization:
- Anthropic models: Monitoring-dominant.
- GPT-5.4 generation: Control-dominant.
- Google Gemma models: Self-regulation-dominant.
Strikingly, evaluation is universally the weakest relative ability across all models; no model demonstrates evaluation as its dominant capacity under ipsative scoring.
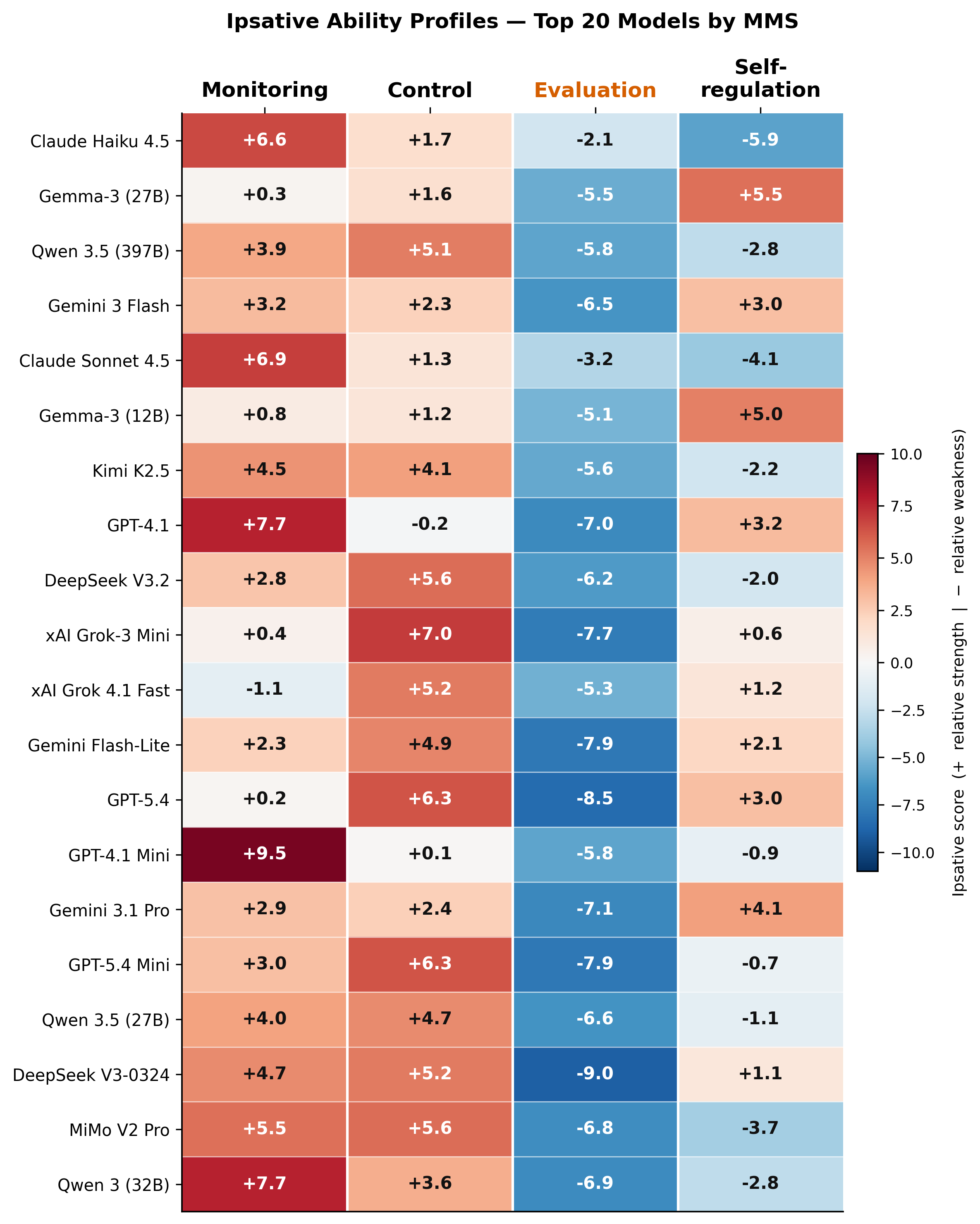
Figure 4: Heatmap of ipsative ability profiles highlights the universal evaluation deficit and family-level metacognitive specializations.
This pattern exposes a systematic knowing–doing gap, substantiating the discrepancy between recognizing the quality of reasoning and regulating one’s own reasoning processes.
Practical and Theoretical Implications
The results have direct ramifications for both the design and deployment of AI systems. Aggregate task performance, commonly used in leaderboards, insufficiently captures metacognitive robustness or belief revision under social pressure. Explicitly optimizing models for metacognitive calibration and resistance to consensus error is absent in current alignment pipelines (including RLHF, Constitutional AI, DPO).
MEDLEY-BENCH provides deterministic, behaviourally targeted metrics suitable for incorporation into training reward signals. Screening for metacognitive diversity and robustness (rather than only output quality) is relevant for ensemble system design and regulatory compliance, especially under frameworks such as the EU AI Act.
Practically, models vary in their failure modes under social influence. Deploying models that privilege argument quality over majority agreement is critical in multi-agent contexts to avoid propagation of consensus errors and mitigate sycophantic interactions. Ipsative profiling enables construction of ensembles with complementary metacognitive strengths.
Limitations and Future Directions
While MEDLEY-BENCH advances the evaluation of metacognitive behaviour, it is bounded by several limitations:
- It measures externally prompted reconsideration, not spontaneous metacognitive monitoring.
- The four-ability structure is strongly influenced by a general factor, though ipsative scoring ameliorates this at the instance level.
- No direct human baseline; future work should benchmark human metacognitive updating under ambiguous and socially pressurized settings.
- Some benchmarked models overlap with analyst pools, but residual analysis suggests minimal bias.
Extension to spontaneous metacognition, expanded domain coverage, and implementation of the progressive adversarial protocols as training signals represent promising future research trajectories. The non-monotonic scaling of metacognitive competence suggests that architectural innovation, not parameter count alone, governs progress toward robust metacognitive AI.
Conclusion
MEDLEY-BENCH establishes a new paradigm for evaluating behavioural metacognition in LLMs. Its three-step protocol, adversarial analysis, and ipsative profiling uncover a pronounced evaluation–control dissociation and a universal evaluation deficit—phenomena not detectable by classical QA benchmarks. The practical implications span ensemble design, deployment screening, and regulatory audit. Theoretically, the benchmark problematizes notions of scale-driven cognitive enhancement and underlines the necessity of direct measurement and reward of calibrated, proportional belief revision and social robustness in next-generation AI training schemes.