- The paper presents a multimodal pipeline using the DGS-Fabeln-1-SE corpus with majority LLM voting and MediaPipe-based spatiotemporal feature extraction.
- It employs an XGBoost classifier with nested cross-validation and feature reduction to 96 key predictors, achieving a balanced accuracy of 63.1% and macro-F1 of 63.5%.
- Insights reveal that both facial and bodily cues are critical for sentiment expression, guiding future research in affective computing and sign language translation.
Sentiment Analysis of German Sign Language Fairy Tales: Methodology, Findings, and Implications
Introduction
The paper proposes a systematic approach for sentiment analysis in German Sign Language (DGS) with a focus on expressive, emotionally rich content from fairy tales. The work leverages the DGS-Fabeln-1 corpus, a parallel collection of 574 narrative sentence segments and corresponding sign language videos, to construct and evaluate a multimodal sentiment detection pipeline. The research introduces DGS-Fabeln-1-SE, an extended resource enriched with detailed annotations—sentiment labels derived by majority voting among four LLMs and a high-dimensional set of spatiotemporal body and face motion features extracted via MediaPipe. Both the dataset and the pipeline provide a reproducible foundation for future work in affective computing and sign language understanding.

Figure 1: A representative frame from the DGS-Fabeln-1 corpus, showing the rich expressivity in sign language interpretation of the opening lines of "The Hare and the Hedgehog."
Dataset and Labeling Pipeline
The DGS-Fabeln-1 corpus uniquely features parallel text and video data for DGS fairy tales, selected due to their inherent narrative-driven emotional variability and robustness for affective modeling. The 574 segments (approximately 2.5 sentences per segment) are each linked to a 9.6-second sign language video (average), resulting in 92 minutes of annotated sign language performance.
The sentiment annotation combines state-of-the-art LLMs—GPT5, Sonic, Gemini Flash 2.5, and GPT OSS 20B—in a strict three-level scheme (positive, neutral, negative). Each segment is analyzed via standardized prompts, with majority voting applied to derive a gold-standard sentiment label. Segments with ambiguous or mixed-emotion readings, or where LLMs do not converge, are systematically excluded, yielding 520 labeled instances with a Krippendorff’s alpha of 0.786, reflecting strong inter-model agreement.
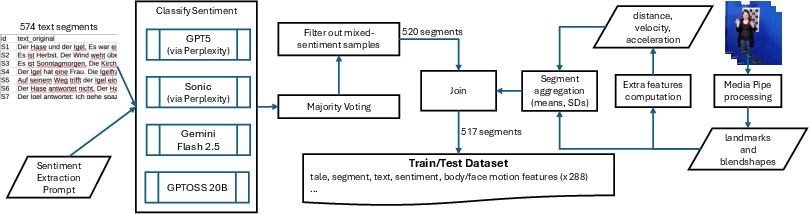
Figure 2: The complete dataset preparation pipeline integrates LLM sentiment voting and detailed video feature extraction, followed by model training and evaluation.
One clear trend is the distributional balance of sentiment classes, as visualized below.
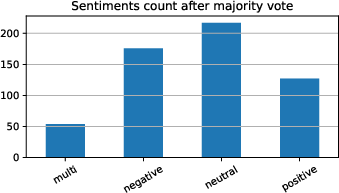
Figure 3: Histogram of sentiment labels across the corpus, illustrating class balance after majority voting and filtering.
Temporal sentiment trajectories are consistent with literary analyses of fairy tales, supporting the plausibility of the automated annotation methodology.
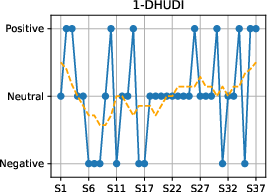
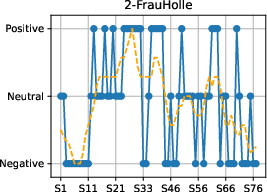
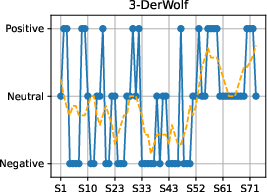
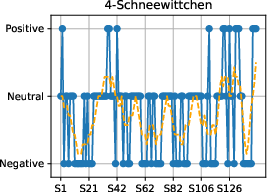
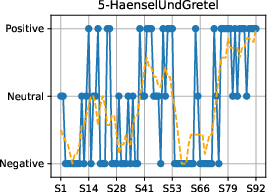
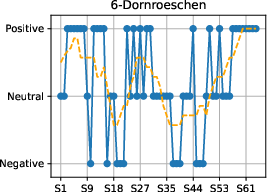
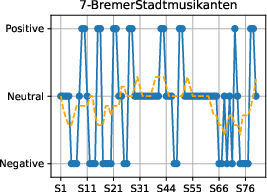
Figure 4: Sentiment progression over narrative time in each fairy tale, confirming genre-typical emotional flow toward positive resolutions.
Feature Extraction and Model Training
Video analysis employs the MediaPipe Holistic and Face Landmarker v2 pipelines to extract 396 per-segment features, capturing dynamics of face (52 blendshapes, head pose), hands, upper body, and torso across three-dimensional motion, velocities, accelerations, and spatiotemporal statistics (mean, standard deviation, aggregate movement, peak rates).
Training employs an XGBoost classifier with hyperparameters tuned via nested cross-validation, SGKF folding by tale, and macro-F1 selection to guard against overfitting and data leakage. Feature selection reduces model complexity to the 96 most informative motion attributes.
Empirical Results
The cross-validation regime yields a mean balanced accuracy of 63.1% and macro-F1 of 63.5%, indicating robust sentiment classification capacity in a highly multimodal, non-textual domain. Detailed metrics show parity across the three sentiment classes, though the model exhibits characteristic confusion between negative and neutral segments.
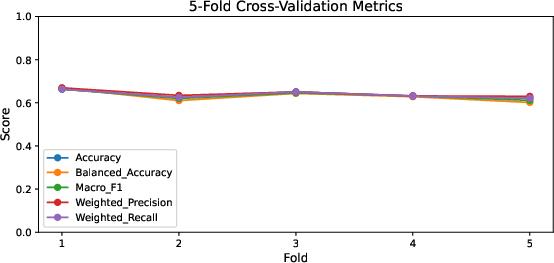
Figure 5: Test metrics (accuracy, macro-F1, balanced accuracy) for each cross-validation fold, reflecting model stability.
The confusion structure is further illustrated for the best fold.
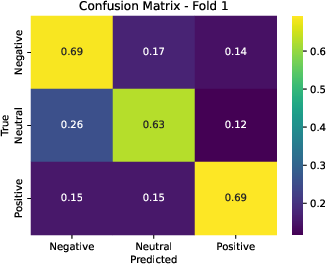
Figure 6: Confusion matrix (fold 1): confusion between neutral/negative sentiment dominates misclassifications, consistent with the ambiguous nature of some segments.
A regression-style evaluation (mapping sentiment to {−1,0,1}) yields a Pearson ρ = 0.529, which, while lower than text-based benchmarks (ρ=0.65), reflects the increased difficulty of multimodal sentiment analysis in sign language compared with text-only domains.
Interpretability and Feature Analysis
The model’s explainability via XGBoost enables direct inspection of feature importances. Notably, the top 30 predictors span both facial (smile, eyebrow activity, mouth corners) and bodily (elbow elevation, hip and torso motion, inter-arm distance) attributes. This establishes, with quantitative backing, the parity of body and face in expressing sentiment in DGS, contradicting approaches privileging either channel.
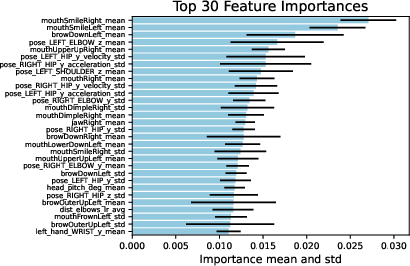
Figure 7: The 30 most informative features for sentiment prediction, combining face blendshapes, head pose, and detailed body limb dynamics.
Several strong, hypothesis-driven findings emerge:
- Facial cues (smile, eyebrow orientation) are critical for detecting positive and negative affective states.
- Elbow and shoulder positioning: Positive valence correlates with raised elbows and open arm postures, suggesting more expansive gestures when expressing positive sentiment.
- Hips and verticality: Increased vertical hip motion is associated with negative valence, reflecting "troubled" narrative contexts (e.g., enacted distress or conflict).
- Arm span and directionality: Wider actions and certain torso rotations covary with sentiment and role shifts in storytelling.
Limitations
The study’s primary limitation is the lack of human sentiment annotation for either the source text or sign language videos, relying instead on high-agreement LLM-driven labeling. While prior work attests to robust LLM-human agreement for German texts, human annotation on the video material by native DGS signers is essential for definitive ground-truth establishment. Further, the analyses are confined to the frontal camera perspective and may conflate sentiment expressivity with narrative role shifting via body orientation.
Theoretical and Practical Implications
By providing evidence of robust, explainable, and joint body-face sentiment decoding in a narrative SL setting, this paper pushes the field beyond frame-level or hand-centric approaches prevalent in prior works. The findings are instructive for:
- Affective SL recognition pipelines: Future research can build upon this interpretable feature set to improve real-world SL translation and avatar synthesis, addressing criticisms regarding the emotional flatness of generated sign language.
- Corpus design: DGS-Fabeln-1-SE can act as a resource for validating new models or benchmarking multimodal architectures.
- Cross-modal emotion dynamics: The quantitative demonstration of full-body involvement in emotion marking in SL informs linguistic theory about expressivity and grammaticalization of affect in signed communication.
Future Directions
Progress will require segment-level annotations by native signers, richer video analytics using multi-view geometry or more precise pose estimation (e.g., OpenPose rather than MediaPipe), and temporal subsampling to better localize sentiment expression at the sign or phrase level within each segment. The methodologies developed here generalize to other sign languages and narrative contexts, targeting the development of explainable, deployable affective computing agents in assistive, educational, and interactive systems.
Conclusion
This work systematically advances multimodal sentiment analysis for German sign language, establishing a robust pipeline, interpretable modeling, and a publicly available resource. The empirical parity of face and body features for sentiment recognition challenges conventional SL research assumptions and provides a foundation for linguistically informed, affectively expressive SL translation and synthesis research.