- The paper introduces SCaTR, a novel framework that uses penultimate-layer embeddings to calibrate and enhance best-of-N candidate selection in LLMs with up to 9.1% accuracy improvement in math and 6.1% in coding.
- It employs a two-phase approach with a calibration phase training a shallow MLP, achieving comparable performance to fine-tuning with 700–1,000× fewer parameters and significant speedups.
- Empirical results show that SCaTR reliably outperforms traditional token-based confidence heuristics, closing up to 76.8% of the gap towards oracle selection across diverse domains.
SCaTR: Simple Calibrated Test-Time Ranking for Best-of-N Selection
Motivation and Problem Statement
Test-time scaling (TTS) has become a primary methodology for boosting LLM output quality by allocating additional compute during inference, typically via parallel rollout: generating N candidate responses and selecting the best. The effectiveness of parallel TTS hinges on the scoring function used for Best-of-N (BoN) selection. While learned selectors like process reward models (PRMs) deliver strong performance, their deployment cost is prohibitive; conversely, cheap confidence heuristics based on token probabilities are computationally efficient but empirically unreliable, particularly in open-ended domains (code, free-form generation). Existing confidence-based metrics consistently perform close to random selection, failing to reliably discriminate correct from incorrect solutions (Figure 1).
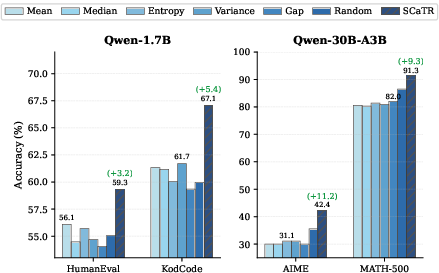
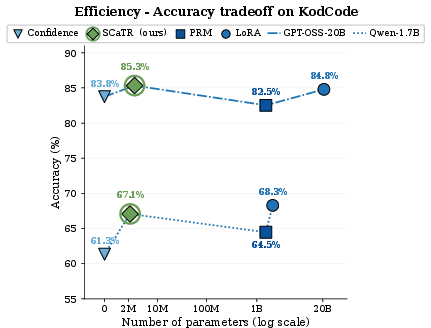
Figure 1: Tail-aggregated token uncertainty metrics versus random and SCaTR: confidence-based metrics provide limited signal for effective response selection.
Recent evidence suggests that hidden states, rather than superficial token-level signals, capture richer information about the underlying reasoning trajectory and output quality. The key challenge addressed by this paper is whether a lightweight, calibratable scoring model leveraging hidden representations can robustly outperform confidence heuristics, match strong learned selectors, and maintain high efficiency.
Methodology: SCaTR Framework
SCaTR proposes a two-phase approach:
- Calibration Phase: For a given LLM, candidate responses to prompts are generated and labeled for correctness (via domain-specific evaluators). The penultimate layer's hidden representation for the final non-padding token of each response is extracted. A shallow MLP scoring function is trained to predict correctness from these representations, using just a few hundred calibration problems per model.
- Inference Phase: At test time, the LLM generates multiple candidates. For each, the scoring model evaluates the penultimate-layer embedding and assigns a probability of correctness. The best candidate is selected either by maximizing the score (code/free-form), or by weighted majority vote (definite-answer domains, e.g. math).
This design enables model- and domain-specific calibration with minimal computational overhead—training the lightweight scorer is orders of magnitude faster than fine-tuning or PRM training, and inference incurs negligible latency.
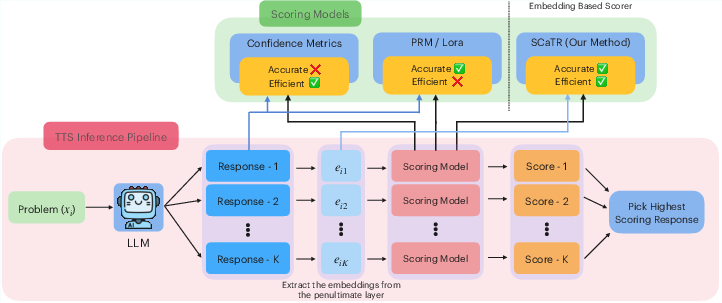
Figure 2: SCaTR pipeline: generation of candidate responses, extraction of penultimate-layer embeddings, scoring via calibration-trained MLP, and best-of-N selection.
Empirical Results
Accuracy Versus Baselines
SCaTR is evaluated across multiple LLMs (OLMo-2, Qwen3, GPT-OSS) ranging from 1.7B to 30B parameters, and both coding and mathematical reasoning benchmarks. Across all settings, SCaTR substantially outperforms confidence-based heuristics, achieving up to 9.1% improvement in accuracy for math and 6.1% for coding.
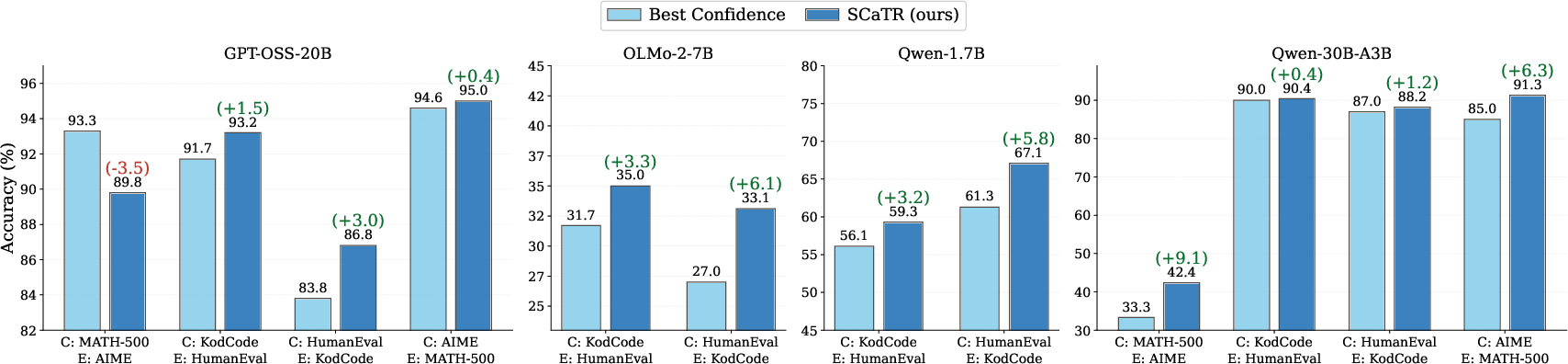
Figure 3: SCaTR consistently matches or exceeds the strongest confidence-based selection, yielding up to 9.1-point improvement on mathematical reasoning and 6.1-point gain on coding.
SCaTR bridges a substantial fraction of the gap toward oracle selection (choosing any correct candidate), closing up to 76.8% of the gap in the best cases.
Efficiency and Accuracy Trade-Off
Relative to LoRA fine-tuning on the same data, SCaTR attains comparable performance with up to 8,000× fewer trainable parameters, and training/inference speedups of up to 3,500× and 1,000×, respectively. Compared with PRMs (e.g., ReasonFlux-1.5B), SCaTR matches or outperforms them in accuracy on several datasets, but requires 700–1,000× fewer parameters and delivers orders-of-magnitude faster inference (Figure 4).
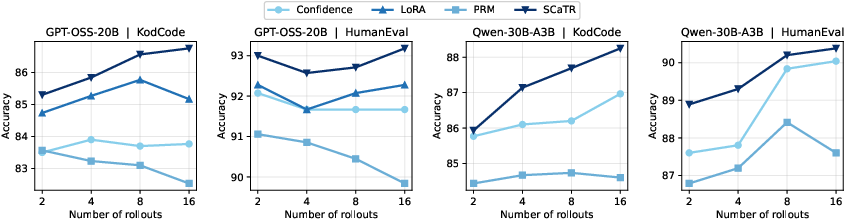
Figure 4: SCaTR remains competitive across rollout budget sizes and steadily improves as more candidates are available.
Absolute accuracy gains relative to PRMs reach up to 7.8 points on math and 4.2 points on coding benchmarks. When combined with weighted majority vote, SCaTR further improves performance if a canonical answer is present.
Robustness and Ablation Studies
Hidden Representation Choice
Performance ablation over layer selection shows penultimate-layer embeddings are robust, with low variance (Figure 5). Other deep layer embeddings also deliver comparable results, suggesting flexibility in representational choice.
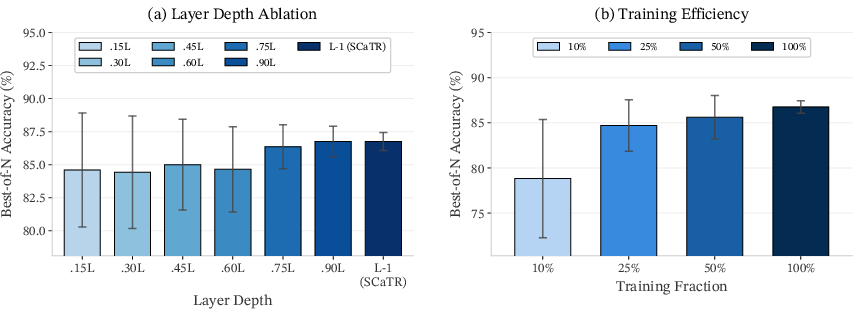
Figure 5: Left: Penultimate-layer embeddings exhibit low variance and robust performance. Right: Larger calibration set improves accuracy and reduces variance.
Calibration Set Size
Reduced calibration size degrades accuracy gracefully; on larger datasets, SCaTR's performance plateaus, indicating data efficiency.
Scoring Architecture
More sophisticated scoring models (ensemble, transformer-based, multi-layer) do not afford consistent gains over the simple penultimate-layer MLP, validating the simplicity and efficiency of SCaTR’s default design.
Uncertainty Metrics: Empirical Failure
Extensive comparative analyses establish that confidence-based metrics (mean, median, variance, probability gap, entropy) aggregated by various strategies—over sequence, tail, or low-confidence token groups—consistently fail to yield discriminatory power, and never reliably outperform random selection (Figures 7, 8, 9).
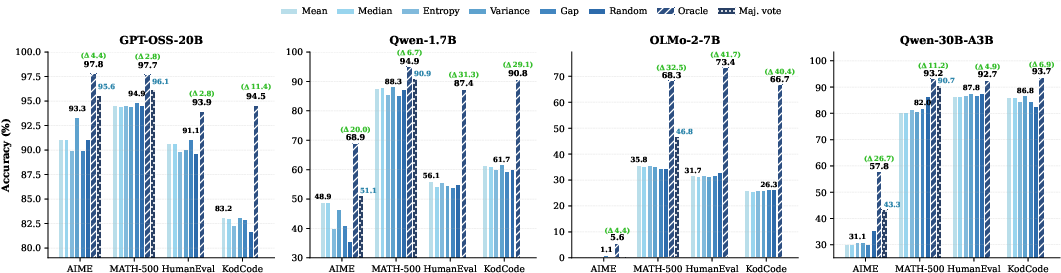
Figure 6: Confidence-based metrics behave similarly to random selection and remain far below oracle performance.
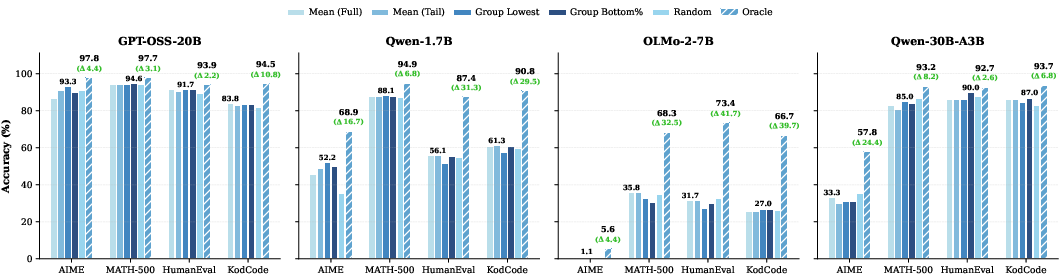
Figure 7: Different aggregation strategies yield similar performance, offering no clear criterion for confidence-based selection.
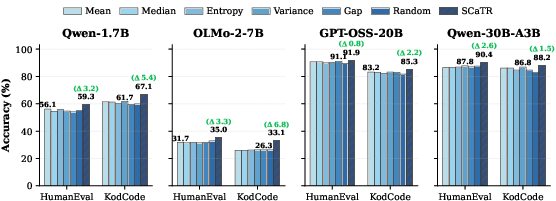
Figure 8: SCaTR outperforms confidence-based uncertainty metrics across all models in the coding domain.
Implications and Future Directions
The results validate that lightweight calibration models trained on hidden states provide scalable, efficient response selection for TTS, enabling practical deployment in compute-sensitive scenarios. This is of immediate significance for open-weight LLMs, where access to hidden representations is feasible. The findings challenge the utility of fixed confidence heuristics and reinforce the value of model-internal signals for downstream selection tasks.
Given its efficiency, SCaTR opens the door for domain-adaptive and model-specific selection pipelines requiring minimal supervision. Extensions to multi-turn reasoning, use of richer internal signals (token-level states, attention maps), or hybrid approaches combining lightweight scorers with PRMs for fallback in hard cases are promising future avenues.
Conclusion
SCaTR establishes a strong accuracy-efficiency tradeoff for scalable test-time candidate selection in LLMs. By exploiting hidden representations and lightweight calibration, it significantly outperforms confidence-based heuristics and matches strong learned selectors while maximizing efficiency. The approach is robust, data-efficient, and model-adaptive, and its empirical findings have implications for both theory and practical deployment of scalable inference pipelines. Future work will explore its extension to multi-turn and complex reasoning, as well as richer utilization of internal model dynamics.