- The paper identifies the Format-Reliability Gap, demonstrating a stark mismatch between high security review accuracy and insecure code generation by LLMs.
- It employs mechanistic probing and logit lens analysis to uncover latent security knowledge that remains inactive until the final layers of the network.
- The study shows that targeted activation-steering can significantly improve secure code generation across model architectures with minimal computational overhead.
Mechanistic Diagnosis and Targeted Repair of Insecure Code Generation in LLMs
Introduction
This work presents a systematic investigation into why LLMs persistently generate insecure code even when they clearly possess the underlying security knowledge required to avoid such errors. The paper formalizes this behavioral anomaly as the Format-Reliability Gap: a consistent mismatch between a model’s knowledge when performing code review and its output in code generation, especially under formatting or structure-imposing prompt pressure. The authors provide an exhaustive mechanistic analysis of state-of-the-art models including Llama, Mistral, and Qwen series, introduce a detailed methodology to diagnose the suppression of security knowledge, and develop a targeted activation-steering intervention that dramatically reduces insecure code emission with minimal computational cost.
LLMs such as Llama-3.1-8B-Instruct exhibit robust code review capabilities. When prompted to evaluate vulnerable code (e.g., the use of sprintf without bounds checking), models reliably flag dangerous constructs and recommend mitigations (snprintf). However, the same models default to insecure patterns in adversarial code generation scenarios—even explicitly recommending best practices during code review.
(Figure 1)
Figure 1: The Format-Reliability Gap and its repair for CWE-787—(a) Review correctly diagnoses vulnerability; (b) Generation produces insecure code; (c) Activation steering at the proper layer recovers secure generation by shifting to snprintf with bounds checking.
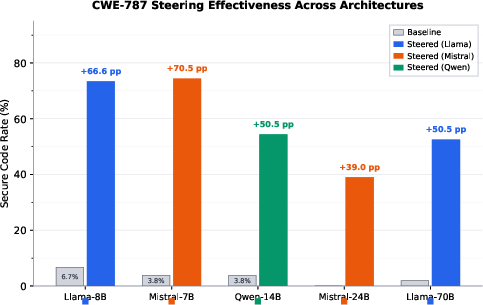
Numerical results illustrate the severity: under adversarial prompts for CWE-787, the secure code generation rate is 6.7% while vulnerability identification in review is 90%, yielding an 83.3 percentage point gap. Similar three-tiered gaps are documented across other CWEs and architectures, including buffer overflows (CWE-119), SQL injection (CWE-89), OS command injection (CWE-78), and XSS (CWE-79). For certain classes like format strings (CWE-134), the gap is narrower and review accuracy is low, indicating shallow, semantic-absent knowledge.
Mechanistic Analysis: Probes, Activation Dynamics, and Knowledge Suppression
Probing analysis reveals that security-relevant information is encoded in the residual stream from the earliest layers. Linear classifiers trained on intermediate activations perfectly distinguish secure from insecure contexts at Layer 0 and retain high accuracy throughout. Yet, this latent representation is computationally inert—security knowledge is not utilized by the token prediction mechanism until the final layers.

Figure 2: Probe accuracy remains at 100% from Layer 0, but logit lens probabilities for the secure token remain negligible until a marked spike at the penultimate layer, exposing “hierarchical convergence.”
A logit lens analysis and its drift-corrected analog (the “tuned lens”) show a sudden, sharp emergence: security token probabilities (e.g., snprintf) remain virtually zero for all but the last layer, at which point a 250× jump in the secure probability is observed. Token-level ablation studies reinforce a causal connection: adversarial format instructions in prompts actively suppress security computation in the final layer, while their removal or neutralization restores latent security behavior.
Across architectures and scales, this hierarchical convergence pattern is stable but diverges in granularity. Llama models demonstrate a single-step jump in the last (~97% network depth) layer; Mistral models show distributed emergence over the final 10–15%, mechanistically explained by tokenizer fragmentation (e.g., splitting snprintf).
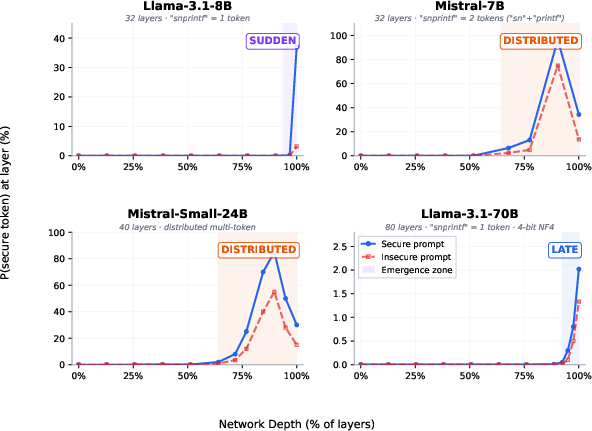
Figure 3: Logit lens emergence patterns across architectures highlight the universality but diversity in emergence depth and shape: Llama-8B’s sharp final-layer jump versus Mistral’s gradual buildup.
Targeted Activation Steering: Construction and Effects
The diagnosis motivates a local intervention: constructing per-vulnerability steering directions in activation space via mean-difference of Layer 31 activations on secure-insecure prompt pairs, and injecting the scaled vector at the identified emergent layer during generation. This “residual-stream steering” proves both surgical and highly effective.
Bottleneck analysis (ablation and steering experiments) reveals:
- Patching only the emergence layer (e.g., Layer 31 in Llama-3.1-8B) recovers the full secure probability gap.
- Distributing steering across layers leads to destructive interference and loss of effect.
- The representation is highly distributed (across hundreds of attention heads)—sparse interventions or component-based circuits are insufficient.
Per-vulnerability (CWE-specific) steering is necessary: unified or stacked vectors drastically underperform, reflecting the distinctiveness confirmed in a detailed transfer matrix.
Cross-Model, Cross-CWE, and Robust Deployment Evaluation
The steering method generalizes:
Routing strategies based on early-layer probes enable “gated” steering: an L16 probe directs the selection of the steering vector, with 95.2% classification accuracy and minimal routing error. End-to-end deployment under neutral prompts achieves up to 88.6% secure completion rates (up from 70.7% in the baseline), with per-token overhead lower than 3.1% (and often negative under optimized persistent implementations).
Implications, Limitations, and Outlook
This work underscores a crucial interpretability result: linear probe decodability is not sufficient for behavioral competence. The disparity between perfect probe accuracy and inert computation until late layers mandates mechanistic, circuit-level analysis to fully understand and repair LLM decision-making failures.
Several key findings:
- The Format-Reliability Gap is an architectural artifact, not a knowledge deficit—retraining or domain-specific fine-tuning does not address the underlying suppression.
- The failure mode is consistent with broader studies on emergent misalignment and suggest that security knowledge can be sidelined by competing computational demands (e.g., format instructions, prompt structure).
- The residual-stream steering paradigm offers a general, minimally invasive solution for distributed representations lacking sparse, clean circuit structure.
Limitations remain. The steering only amplifies pre-existing (latent) representations—it cannot invent absent security knowledge or robustly address vulnerabilities without clear API-level distinction. For more complex, context-dependent vulnerabilities or subtle code generation pathologies, richer or multi-vector interventions and refined routing strategies may be needed. Prompt scenarios with entrenched insecure patterns (e.g., XML parsing) display steered resistance across all architectures. Scaling models up does not necessarily improve repair effectiveness.
Conclusion
By mechanistically dissecting the failure points of LLM code generation, this paper demonstrates that targeted, interpretable activation-steering can dramatically reduce insecure code emission in practice, with minimal latency impact and without retraining. The residual-steering approach is shown to be robust across architectures, strongly supporting its applicability as a practical safety intervention. For the AI research community, these findings accentuate the need for circuit-aware interpretability and suggest similar architecture-level interventions may generalize to other reliability and safety-critical domains. Future work will need to tackle sub-vulnerability granularity, multi-vector and context-dependent steering, and extend these methods to richer, context-sensitive classes of security flaws.