- The paper presents a selective parameter optimization framework that identifies and freezes core parameters, preserving generalization during fine-tuning.
- It employs a gradient-based importance estimation, significantly reducing computational time and memory compared to traditional methods.
- Experiments on GPT-J-6B and LLaMA-3-3B demonstrate improved domain adaptation and maintained language capabilities with reduced catastrophic forgetting.
Efficient Task Adaptation in LLMs via Selective Parameter Optimization
Introduction
The paper "Efficient Task Adaptation in LLMs via Selective Parameter Optimization" (2604.17051) investigates the persistent issue of catastrophic forgetting in LLMs during domain-specific fine-tuning. Conventional full-parameter fine-tuning often results in the overwriting of generic language capabilities, adversely impacting cross-domain generalization and transferability. This work formalizes the parameter heterogeneity hypothesis—asserting that only a subset of parameters is critical to generalization—by introducing a selective parameter optimization framework that explicitly separates and protects core parameters during task adaptation.
Catastrophic forgetting remains a critical bottleneck when adapting LLMs to downstream domains. This phenomenon is exacerbated by the mismatch in data distribution between large-scale pre-training corpora and limited, domain-specific datasets. While prior methods such as Synaptic Intelligence (SI) and Elastic Weight Consolidation (EWC) have explored parameter-level importance estimation and regularization, they encounter computational bottlenecks in high-capacity networks. PEFT strategies (notably LoRA and its variants) address some resource-related challenges but do not fundamentally resolve the catastrophic forgetting problem, especially in continual or multi-domain adaptation scenarios.
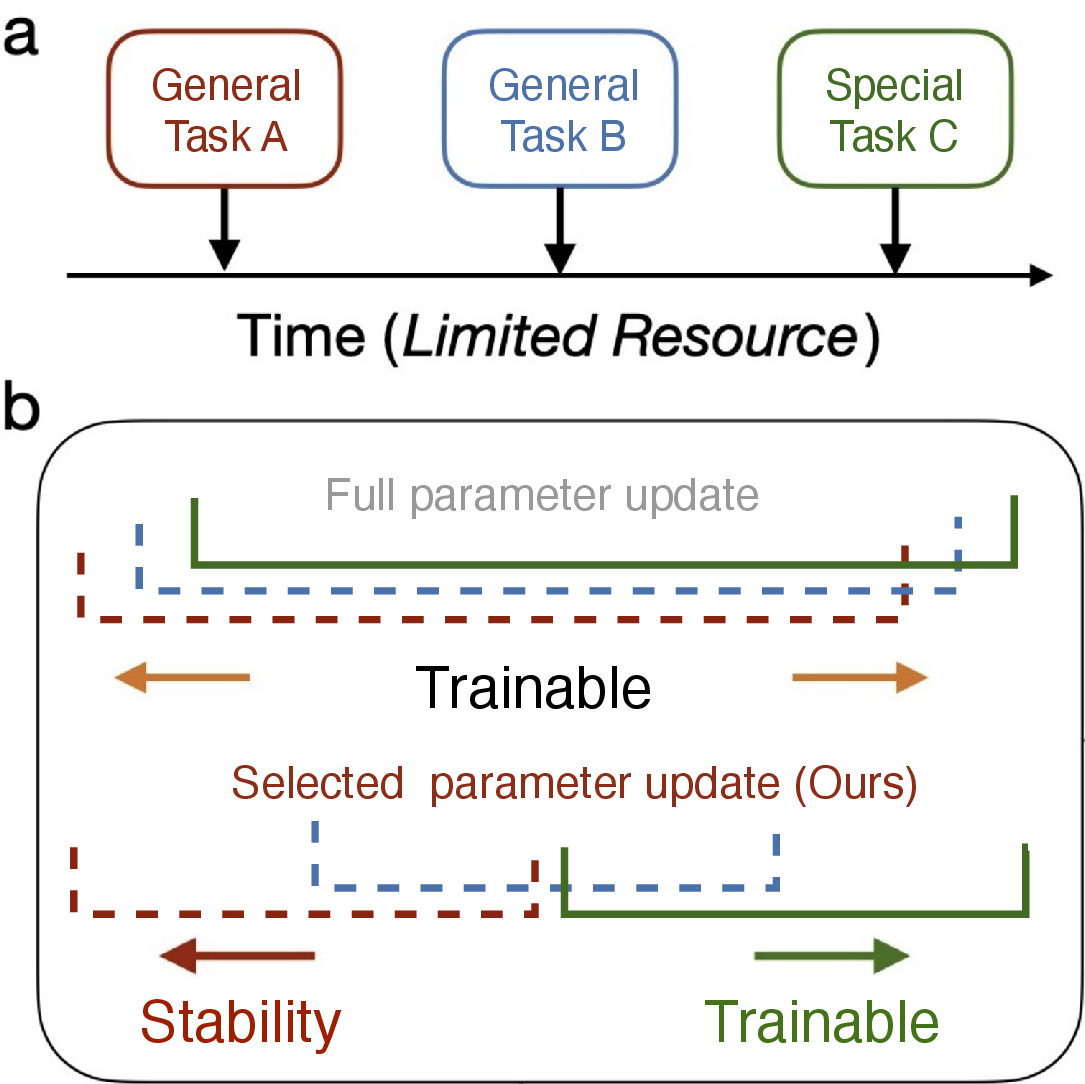
Figure 1: (a) Training data exposure timelines in LLMs; (b) the contrast between full-parameter and selective parameter fine-tuning in preventing catastrophic forgetting.
Methodology
Parameter Importance Estimation
The key contribution is a two-phase process that quantifies parameter importance for general abilities using a gradient-based criterion over a general corpus. Each parameter’s importance is assessed as the expected magnitude of its gradient relative to the pre-training objective. Formally, parameters with importance scores exceeding a chosen threshold θ are designated as "core," and the remainder as "non-core". Importantly, only non-core parameters are allowed to update during domain fine-tuning, while all core parameters remain frozen.
This discrimination leverages the empirical observation that updates to less critical parameters suffice for effective domain transfer, while freezing highly salient parameters effectively preserves generalization.
Domain-specific Adaptation
Fine-tuning then proceeds exclusively over the non-core parameter set. This selective update rule ensures that task adaptation is achieved without incurring the loss of linguistic generality, as evidenced by the contrast to traditional full-parameter or naive LoRA-based adaptation approaches.
Computational Efficiency
The gradient-based importance estimation is substantially more efficient than EWC-type approaches that require Fisher matrix computations and significant memory/storage resources. The proposed method reduces time and space complexity by an order of magnitude relative to EWC/LoRA hybrids.
Experimental Results
The method demonstrates its effectiveness on GPT-J-6B and LLaMA-3-3B backbones, transferring from general-purpose corpora to scientific, medical, and physical reasoning tasks (including evaluation on MedMCQA, SciQ, and PiQA datasets). Key outcomes include:
- Consistent retention (and in many cases improvement) of generalization, as measured by perplexity and task-specific accuracy, even after multiple sequential fine-tuning steps.
- The lowest perplexity (PPL) values relative to both PEFT and full-finetuning baselines, confirming improved general knowledge retention.
- Similar or higher accuracy on domain tasks compared to state-of-the-art approaches, notably outperforming EWCLoRA and RSLoRA methods.
The loss decomposition analysis shows that the regularization component, enforcing the constraint on parameter drift, first increases and then decreases, reflecting a controlled and stable adaptation trajectory that is absent in full-parameter approaches. The method also significantly accelerates importance computation (1.15–1.19 hours vs. >25 hours for EWC analogues) and reduces storage demands (3.5 GB vs. ~23 GB for Fisher-based methods).
Implications and Future Directions
This work demonstrates that parameter-level discrimination is an effective and scalable mechanism for controlling knowledge retention in LLMs during fine-tuning. Immediate practical implications include:
- Facilitating rapid, low-overhead domain adaptation for LLMs in resource-limited settings or federated/multi-domain deployments.
- Enabling dynamic or continual learning scenarios, where the spectrum of domain tasks is diverse and sequentially encountered.
- Providing a general abstraction that unifies stability–plasticity trade-offs under a single, computationally feasible framework.
Theoretically, this approach opens further studies in parameter attribution, such as adaptive thresholding, group-wise importance, and the interaction between importance scores and LLM modularity. In the context of task-agnostic LLMs, the method suggests potential directions for developing models with lifelong learning attributes, explicit isolation of "knowledge regions," and automatic discovery of reusable submodules.
Conclusion
Selective parameter optimization offers a robust, efficient, and empirically validated protocol for LLM task adaptation, with strong evidence for mitigation of catastrophic forgetting and improved knowledge transfer. The reported results establish a new baseline for balancing general and domain-specific abilities in large-scale neural models (2604.17051).