- The paper's main contribution is the Reward Score Matching framework that unifies diverse reward-based fine-tuning methods for flow and diffusion models.
- The methodology reframes fine-tuning as score matching against an optimal reward-guided target, detailing estimator design, temporal weighting, and trust-region mechanisms.
- The study shows that streamlining auxiliary components and reallocating compute can yield up to 5× improvements in reward alignment efficiency.
Reward Score Matching: Unifying Reward-based Fine-tuning for Flow and Diffusion Models
Introduction and Motivation
Reward-based fine-tuning (RFT) is a central paradigm for aligning generative models—diffusion and flow-based—with human or task-specific objectives, under either differentiable or black-box rewards. Historically, RFT approaches have drawn from disparate perspectives: entropy-regularized reinforcement learning (Soft RL), GFlowNets, and optimal control. These perspectives yielded algorithmic variants differing in estimator construction, rollout patterns, temporal weighting, and trust-region heuristics, often obscuring shared structure and practical tradeoffs.
The core contribution of "Reward Score Matching: Unifying Reward-based Fine-tuning for Flow and Diffusion Models" (2604.17415) is the introduction of a unified framework—Reward Score Matching (RSM)—which concisely subsumes a broad class of prior RFT methods. The authors show that different methods correspond to specific choices within a common RSM loss, and key differences reduce to the construction of the value-guidance estimator and temporal allocation of optimization strength. This unification enables incisive characterization of bias–variance–compute tradeoffs and exposes auxiliary mechanisms that add complexity without substantive benefit.
RSM interprets reward-based fine-tuning as score matching toward an optimal reward-guided target distribution. Given a pretrained reference model, optimal alignment is achieved by matching model scores to those of a marginal distribution exponentially tilted by the soft value function Vt. This yields an ideal target score at each timestep:
st∗(xt)=stref(xt)+α1∇xtVt(xt)
where α controls the entropy regularization strength. The practical challenge is that Vt is intractable, necessitating surrogate estimators.
The RSM framework defines a general loss:
L(θ)=Eti,xti[C1(ti)∥stiθ−(stiref+Ψti)∥2+C2(ti)∥stiθ−stiθ†∥2]
where Ψti is an effective value-guidance estimator incorporating practical approximations and temporal reweighting. The framework seamlessly recovers first-order (Tweedie-based) and zeroth-order (policy-gradient-based) estimators as special cases, as summarized in Table 1 of (2604.17415).
This unification reveals that:
- First-order estimators differentiate through reward or value approximations and are used with differentiable rewards.
- Zeroth-order estimators use only reward signals (e.g., REINFORCE-style MC rollouts) and are agnostic to reward differentiability.
Both families are understood as alternative surrogates for the same underlying value-guidance signal.
Analysis of Design Tradeoffs Across Methods
The canonical RSM loss decomposes the gradient step into three axes: effective guidance (toward higher reward), KL regularization (toward the reference model), and trust-region anchoring (for prior or earlier policy adherence). The practical variation across methods arises in three main axes:
1. Estimator Design:
- Lookahead depth: Deeper rollouts (lower SNR, closer to the unnoised sample) reduce bias but increase variance and sampling cost.
- Branching width: Multiple descendants at a given step (particle-based averaging) trade compute for variance reduction.
- Stochasticity localization: Placement of stochastic versus deterministic components can alter the effective control landscape and estimation noise.
2. Temporal Weighting:
Key to sample-efficient training is the allocation of optimization mass and compute across timesteps. High-SNR (later) and low-SNR (early) steps differ in both estimator quality and impact on final sample quality. The authors show, e.g., that optimal zeroth-order methods concentrate effort where estimator variance is minimized (typically at low-SNR), while first-order methods suppress optimization at low-SNR due to bias from Tweedie approximations.
3. Trust-Region Realization:
Variants differ in regularization strength across time, e.g., via dynamic coefficients C2(ti) or PPO-style clipping, affecting how much value-guidance signal survives to update the parameters. Figure 1 illustrates the modulation of optimization strength.
Figure 1: Temporal profiles of optimization strength for canonical first-order, improved zeroth-order, and residual trust-region regularization across timesteps.
Theoretical and Practical Consequences of the RSM Perspective
Canonical Bias–Variance–Compute Analysis
Through synthetic experiments with ground truth reward-tilted distributions, the authors explicitly show the bias/variance/computational tradeoff of estimator variants, as illustrated in Figure 2. Pointwise MC rollouts (zeroth-order) are unbiased but high-variance; shallow lookahead (first-order) is low-variance and compute-efficient but severely biased at early (low-SNR) timesteps. Multi-branching and reward centering act as effective variance controls.
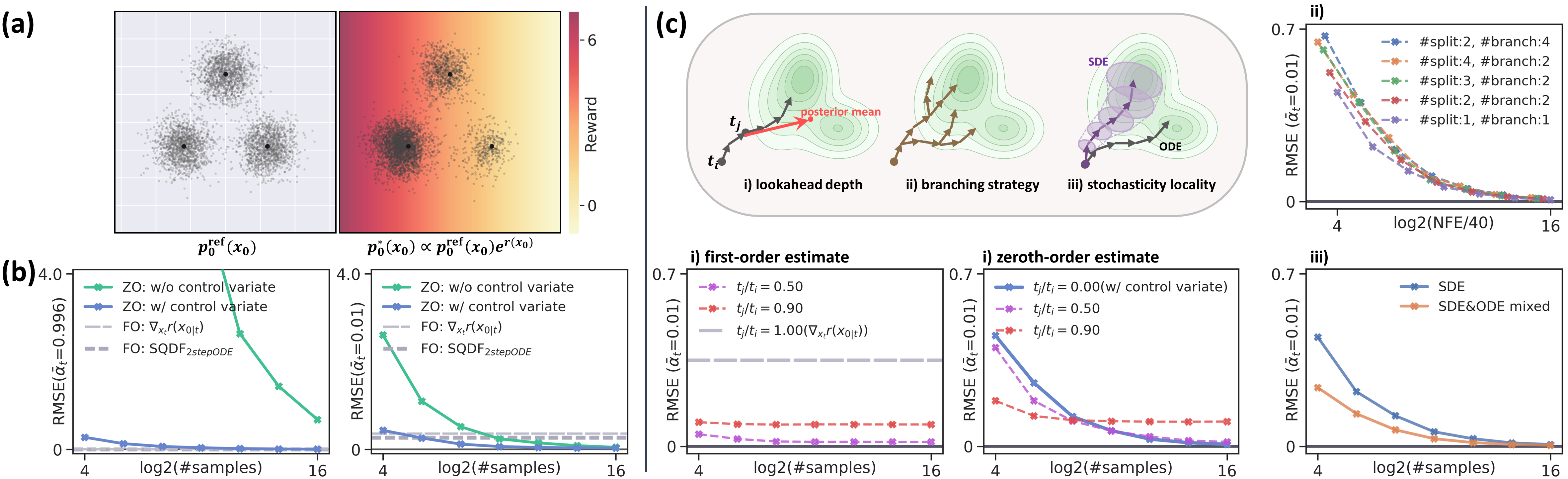
Figure 2: RMSE of first-order and zeroth-order estimators, with varying lookahead depth, branching, and stochasticity localization; ground truth in toy setting.
Temporal weighting and fair compute allocation across timesteps are critical: allocation mismatch (e.g., TempFlow-GRPO's uniform branching at high-SNR, where signal is unreliable) is sub-optimal both empirically and theoretically. Re-weighting updates (“variance-aware redistribution”, Figure 3) achieves faster reward improvement and higher compute efficiency.
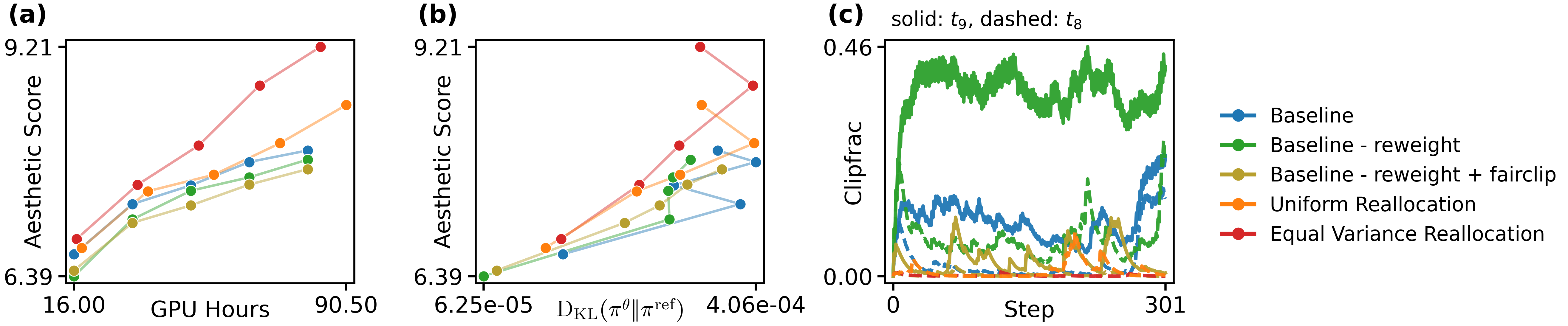
Figure 3: Assessing the effect of timestep-fair clipping and reallocation—optimized budget allocation delivers faster increases in reward efficiency.
End-to-End Improvements: Redundant Heuristics and Efficient Alignment
By reframing existing methods, the authors establish that:
- Auxiliary components (notably, refinement networks like gϕ and detailed-balance backward losses) are superfluous in practice (see Figures 8, 9), providing negligible signal but substantial computational burden.
- Trust-region realization and reward centering, while stabilizing, can be replaced with simpler and more transparent optimizer knobs.
- Well-calibrated temporal weighting and variance-aware branching deliver strong performance across differentiable (first-order) and black-box (zeroth-order) reward settings, yielding up to 5× wall-clock speedups in GenEval-alignment tasks.
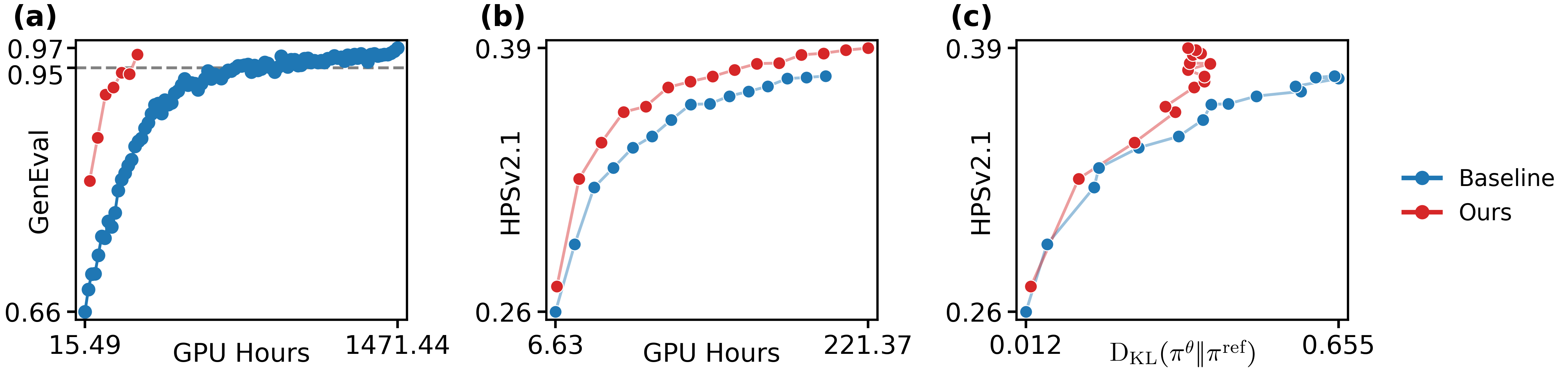
Figure 4: Zeroth-order reward-alignment improvements (GenEval/HPSv2.1). Principled budget allocation across timesteps yields consistently superior reward efficiency.
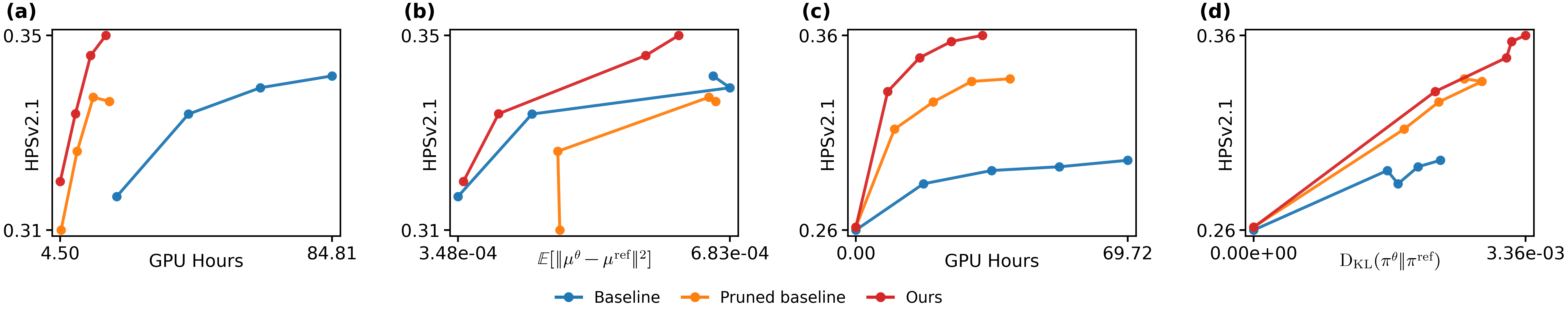
Figure 5: Validation for first-order methods: reward-guidance at low-SNR timesteps accelerates reward gains.
Qualitative comparisons (Figures 12–15) reinforce the claim that these architectural simplifications do not lead to excessive reward hacking or collapse in diversity, and instead produce desirable diversity–reward tradeoffs as measured by DreamSim and auxiliary metrics.
Theoretical Implications and Future Directions
RSM sharpens the theoretical understanding of reward-based fine-tuning by mapping method-specific innovation to a smaller, interpretable space:
- The choice between first- and zeroth-order estimators corresponds to a direct bias–variance–compute frontier.
- Timesteps’ roles are dictated by estimator regime (variance- or bias-limiting) rather than heuristic schedule inheritance from reference pretraining.
- Many recently proposed architectural or regularization mechanisms are theoretically and empirically non-essential.
This framework predicts that further progress will derive from targeted engineering of estimator reliability and compute allocation (e.g., joint tuning of sampler, rollout depths, and branching structures) rather than introduction of new proximal objectives. As highlighted, inference-time score alignment strategies such as DNO can also be interpreted as RSM in noise space, facilitating transfer of training-time advances to downstream sample alignment.
Conclusion
This work provides a unifying analysis of reward-based fine-tuning for flow and diffusion models. The RSM framework demonstrates that the main distinctions among prior algorithms are estimator design, temporal weighting, and trust-region realization rather than fundamentally altered objectives. This yields actionable insights: auxiliary modeling components can be pruned, compute can be systematically reallocated according to estimator quality, and both differentiable and black-box reward settings are covered within a shared score-matching lens.
Methodologies initially perceived as fundamentally distinct—Soft RL policy gradients, GFlowNet variants, direct regression, and more—emerge as instances of a single meta-objective with shared theoretical properties. RSM thus offers a precise language for comparative analysis and a foundation for future developments in alignment and steering of normalizing flows and diffusion generative models.
References:
- "Reward Score Matching: Unifying Reward-based Fine-tuning for Flow and Diffusion Models" (2604.17415)

