- The paper introduces ErrorProbe, a multi-stage framework that applies taxonomic structural decomposition, backward tracing, and verified memory to enhance error diagnosis.
- It demonstrates significant improvements in step-level error attribution, with accuracy boosts from 8.7% to 39.4% across multiple benchmarks.
- The framework's design supports robust, self-improving diagnostics in long MAS interaction traces, validating its scalability and domain transferability.
Self-Improving Error Diagnosis for Multi-Agent LLM Systems: The ErrorProbe Framework
Motivation and Problem Context
As LLM-based Multi-Agent Systems (MAS) proliferate across domains such as software engineering, web navigation, and scientific reasoning, the challenge of debugging and failure attribution becomes increasingly salient. MAS architectures inherently generate long, causally entangled interaction traces, where early errors in agent specialization, coordination, or verification may only manifest much later as task failure. Attribution of failures—accurately identifying the responsible agent(s) and decisive causal step—remains a major unsolved obstacle for both diagnostics and transparent, reliable deployment. Prior work in taxonomy-driven fault analysis, tracer methods, and LLM-as-a-judge paradigms has not addressed the practical need for precise, scalable, and domain-transferable root cause analysis without expensive human annotation or retraining.
The ErrorProbe Framework
To address these issues, the paper presents ErrorProbe, a multi-stage, self-improving pipeline for semantic failure attribution in MAS. The core framework is composed of three stages:
- MAST-Guided Structural Decomposition: Utilizing the MAST taxonomy, ErrorProbe introduces a lightweight detector that annotates traces for specification, misalignment, and verification failures. This structural parsing transforms raw sequences into annotated, semantically-rich representations, yielding interpretable and targeted cues that restrict the hypothesis space for downstream analysis.
- Symptom-Driven Backward Tracing: Upon a detected failure symptom (e.g., an exception, incorrect final output), ErrorProbe reconstructs the relevant causal path by dependency graph analysis and context pruning. Through BFS over the dependency graph—linking only causally impactful turns—it efficiently extracts a reduced trace, mitigating the “lost in the middle” effect of long context and suppressing noise from irrelevant agent actions.
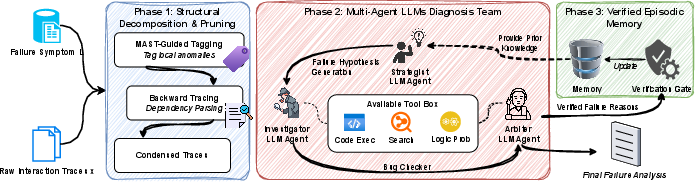
Figure 1: Overview of ErrorProbe. The system prunes long traces via dependency parsing, then employs a Strategist-Investigator-Arbiter team to diagnose the root cause, updating memory only upon successful verification.
- Multi-Agent Diagnosis with Verified Episodic Memory: Diagnosis is orchestrated by a specialized team:
- The Strategist forms initial hypotheses, leveraging both structural cues and historical error patterns via memory retrieval.
- The Investigator grounds each hypothesis with tool-based verification (e.g., re-executing code snippets, validating pre/post-conditions).
- The Arbiter consolidates evidence, adjudicates the root cause, and determines whether to update the verified memory with a new robust error pattern.
Crucially, ErrorProbe's verified episodic memory ensures that only diagnosis patterns with executable, tool-grounded evidence are retained. This “verify-before-commit” design contrasts with naive pattern caching, mitigating memory corruption, and enabling robust transfer and continual self-improvement.
Experimental Evaluation
The efficacy of ErrorProbe is established across three benchmarks—TracerTraj (synthetic faults with known ground truth), Who{content}When-Algo, and Who{content}When-Hand (organic, human-annotated MAS failures spanning code, logic, and web tasks). The main comparison features the following systems as baselines:
- LLM-as-a-Judge: A single LLM instance predicts the responsible agent and causal step directly.
- Agent-as-a-Judge (Baseline): A tool-augmented agent performs multi-stage diagnosis but lacks structured taxonomy and verified memory.
ErrorProbe (with and without memory) is instantiated with state-of-the-art open and proprietary LLMs (e.g., Claude 3.7 Sonnet, GPT-OSS-120B, Qwen3 32B).
Notably, single-pass judge protocols exhibit low step-level attribution accuracy, especially as trace length and causal depth increase. The introduction of ErrorProbe yields substantial improvements, particularly in step localization—which is critical for actionable debugging—not only agent-level attribution. On TracerTraj, step attribution accuracy increases from 8.7% (LLM-as-a-judge) to 39.4% (ErrorProbe+Memory, Claude 3.7 Sonnet), and similar trends are seen across benchmarks. Addition of verified episodic memory provides further gains, robust to backbone model capacity.
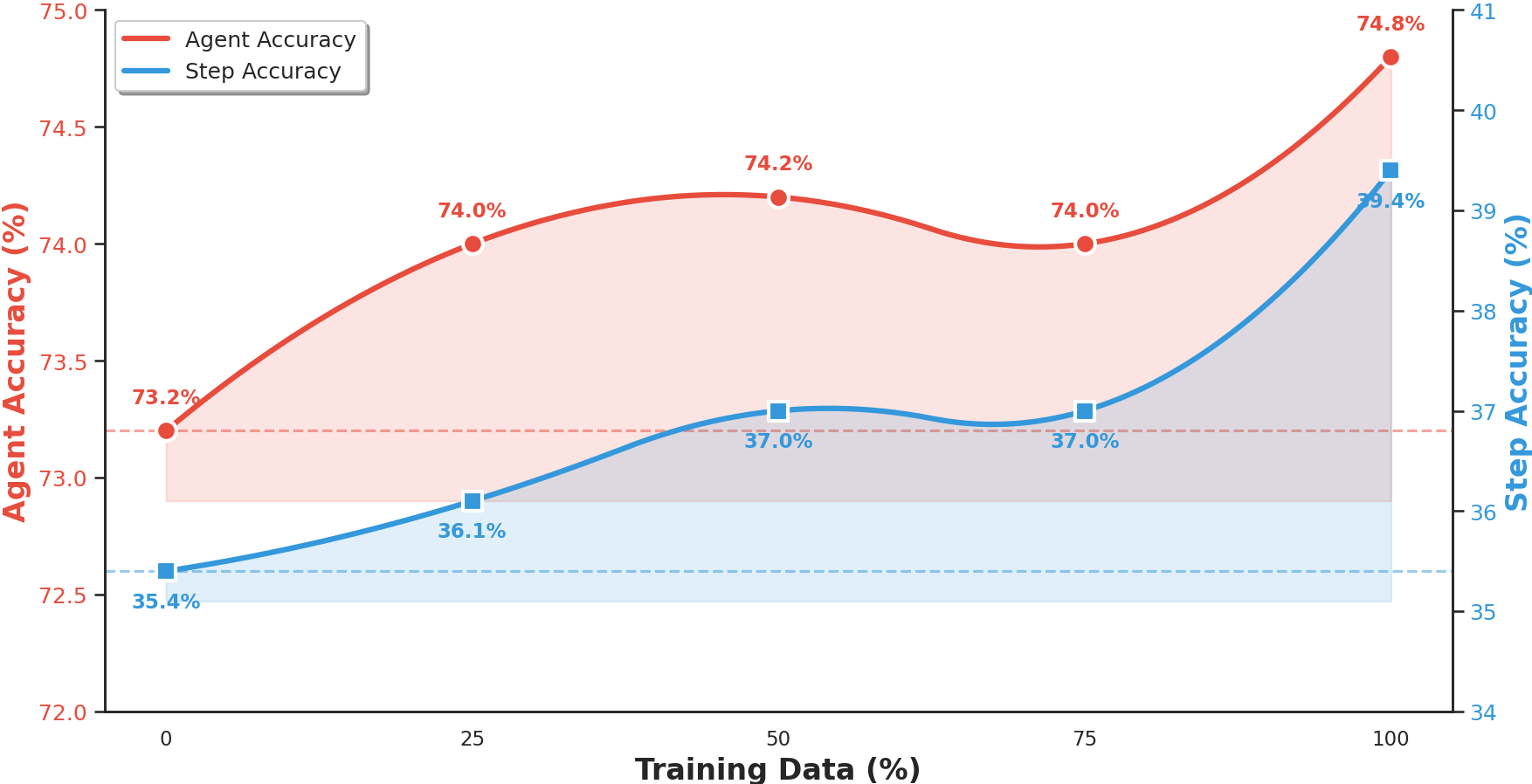
Figure 2: Learning curves for Agent and Step accuracy as memory is populated with increasing portions data. Both metrics, especially step-level accuracy, improve non-linearly with more verified patterns.
Complementary in-domain and cross-domain transfer experiments with curated MAS errors (MBPP, KodCode, GSM8K, MATH) show that verified memory enables diagnosis generalization, with greatest benefit in domains characterized by repetitive or template-driven failure patterns. Even under distribution shift, performance does not degrade, supporting strong claims for ErrorProbe's robustness and scalability.
Implications and Theoretical Insights
The empirical results support several key theoretical implications:
- Structured, Taxonomic Reasoning is necessary for breaking the causal complexity of long MAS traces. Direct LLM-based approaches lack the granularity to pinpoint early, non-salient errors.
- Explicit, Tool-Grounded Verification is critical for mitigating hallucinated diagnoses and for ensuring that stored diagnostic patterns enhance, rather than degrade, future performance.
- Self-Improvability via Controlled Memory: By strictly verifying before memory commits, ErrorProbe demonstrates stable continual learning—distinguishing it from episodic or skill-library memory that is vulnerable to drift or corruption.
Practically, these findings advocate for error diagnosis architectures in MAS that mimic expert debugging workflows: structurally-guided hypothesis generation, tool-based evidence gathering, and robust curation of reusable diagnostic knowledge. Such capabilities will be essential as multi-agent orchestration scales, especially for critical domains (e.g., automated code generation, scientific discovery).
Future Directions
Open avenues include: finer granularity in anomaly detection (capturing silent or latent errors lacking explicit signals), optimizing the compute/inference trade-offs to expand ErrorProbe beyond offline or asynchronous analysis, and confirmation of architecture-agnostic generalizability through exhaustive benchmark scaling with additional models and domains. Integration with real-time test oracles, more expressive structural taxonomies, and tighter coupling of diagnosis and automated repair are promising directions.
Conclusion
ErrorProbe provides a rigorous, empirically validated framework for semantic failure attribution in MAS, coupling symptom-driven backward reasoning, structured taxonomy-based tagging, and robust, tool-verified memory. Its significant improvements over baseline paradigms, especially for decisive-step localization in long, delayed-failure traces, establish the necessity of explicit structure and verification for trustworthy multi-agent AI. Future MAS deployments are likely to require such self-improving diagnostic cores for safe, scalable, and interpretable autonomy.