- The paper introduces Agentic Consensus, a consensus layer that audits and governs human-AI coding by linking structural claims directly with evidence.
- It employs bidirectional synchronization using Φ and Ψ operators to translate intent into artifacts and rehydrate structure, reducing ambiguity as measured by consensus entropy.
- Case studies in data engineering demonstrate enhanced debugging and controlled rollouts, highlighting reduced cognitive load and improved intervention efficiency.
Agentic Consensus: Structural Traceability as the Foundation for Human-AI Coding Collaboration
Motivation: The Representation Gap in AI-Assisted Coding
The proliferation of AI-assisted code generation, encapsulated in the paradigm of "vibe coding," enables rapid production of correct and executable code from succinct natural-language prompts. However, this workflow collapses complex system topology into low-dimensional artifacts: the generated code and chat history. As a result, opaque systems emerge, lacking explicit records of structural commitments, dependencies, invariants, and evidence. Reviewers are unable to audit assumptions or rationales, leaving teams vulnerable to regressions and misaligned modifications. The paper articulates this as a "representation gap," distinguishing generation failures from control failures—systems function but lack cognitive accessibility and governability.
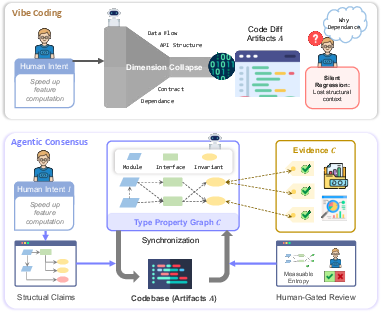
Figure 1: Vibe coding (top) offers speed but lacks traceability; Agentic Consensus (bottom) introduces a structured consensus layer mediating intent and artifact with persistent evidence linkage.
Agentic Consensus: The Governable World Model
The authors propose Agentic Consensus, establishing the consensus layer C as the primary engineering artifact. C is modeled as a typed property graph representing system entities, dependencies, invariants, and linked evidence. All realized artifacts (code, configuration, dataflows) are derived from C via a bidirectional synchronization regime based on operators Φ (realize) and Ψ (rehydrate). Φ translates structural intent into executable artifacts; Ψ rehydrates structure from artifact diffs using static analysis, dynamic detection, data provenance, and test results. Evidence is attached directly to structural claims, making commitments auditable and underspecification measurable via consensus entropy rather than silent guesses.
This paradigm refines programming as a negotiation and validation of explicit structural knowledge. Review surfaces shift from code diffs and chat logs to the structural claims documented in C, enabling systematic control, intervention, and traceability across the workflow.
Case Studies: Structural Auditability in Data Engineering
Two case studies demonstrate Agentic Consensus versus vibe coding in realistic data engineering settings.
In the first scenario, silent AUC degradation in an ML pipeline eludes fix after several chat-driven debugging sessions. The root cause—a feature window drift—is only identified when pipeline lineage and competing hypotheses are made explicit within C, allowing targeted discriminating evidence and rapid resolution.
In the second scenario, a statistically significant CTR lift is approved via vibe coding, despite feature leakage in the treatment group. Agentic Consensus, maintaining a causal DAG and enforcing feature parity contracts, blocks rollout pre-inference, catching the causally invalid result before deployment.
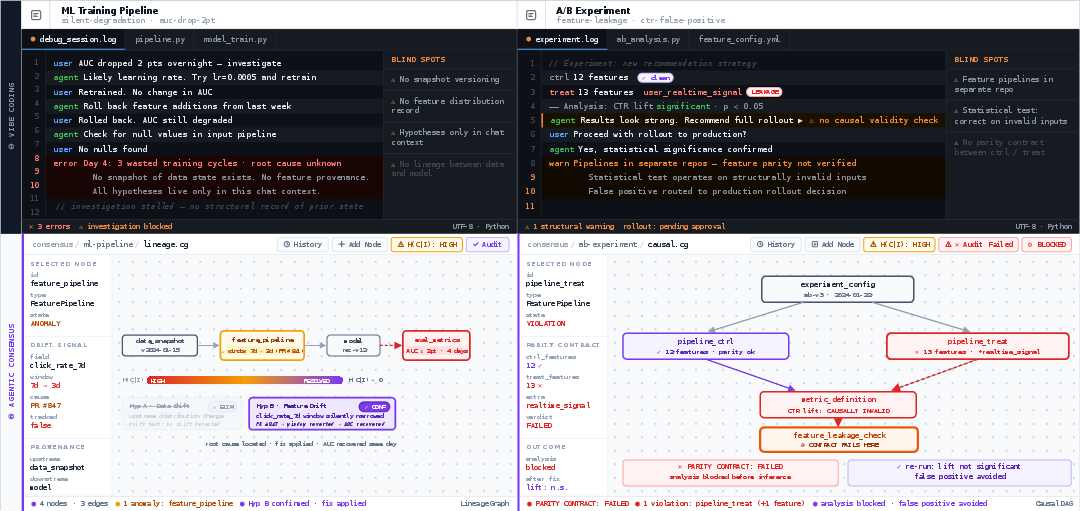
Figure 2: Case studies: Vibe coding (left) yields context-free debugging and incorrect rollouts; Agentic Consensus (right) enables precise diagnosis and valid experiment gating via structural audits.
These cases illustrate C as both a diagnosis surface and a validity gate: hypothesis management, entropy collapse, and contract enforcement are feasible only when structural claims and evidence are rigorously linked.
Synchronization and Evaluation Criteria
Maintaining round-trip consistency between C0 and artifacts is a monitored, approximate invariant. C1 is targeted, but strict equality is unattainable; structural drift is measured and diverging regions flagged. Ambiguous rehydration yields candidates and uncertainty scores, escalating clarification rather than making silent guesses. Commitment and rollback remain human-gated, but decisions are driven by structural rather than artifact-level analysis.
The evaluation framework discards code correctness as a sole metric. Four core criteria are introduced:
- Alignment fidelity (C2): Measures whether C3 makes intent explicit and predictive.
- Consensus entropy (C4): Quantifies structural ambiguity; high entropy triggers clarification, not execution.
- Intervention distance: Counts and characterizes human corrections required to reach correct consensus.
- Cognitive load: Assesses whether humans achieve faster comprehension via C5 interactions.
Benchmarks such as FeatureBench and HAI-Eval, focused on multi-commit, collaboration-necessary tasks, are adapted to measure reductions in human intervention and cognitive overhead.
Multi-Agent Specialization and Orchestration
The full maintenance and evolution of C6 necessitate pipelines of specialized agents—architect, builder, auditor, navigator—who interact over C7 as the shared coordination surface. Agent negotiation resolves conflicting structural proposals, projecting outcomes back to C8 rather than relying on opaque message exchanges. The knowledge base evolves as feedback accumulates, shrinking intervention distance and entropy.
Implications, Limitations, and Future Directions
Agentic Consensus does not depend on weak models or static artifacts; it persists as the locus of human oversight even as agents become more capable. It addresses risks of hallucinated structure, unreliable evidence, and cognitive overload with continual monitoring, evidence weighting, entropy escalation, and task-relevant structural projections.
For large legacy systems, incremental rehydration and distributed consensus layers enable progressive adoption. The paradigm generalizes to knowledge discovery systems beyond coding, supporting agentic workflows in complex socio-technical domains.
The core implication is epistemological: as AI throughput outpaces human capacity for inspection, structural claims, not code or chat logs, must become the unit of governance and intervention.
Conclusion
Agentic Consensus reorients AI-assisted system engineering around explicit, auditable structural agreements as the primary artifact. By introducing a governable consensus layer, it enables scalable human-AI collaboration with persistent traceability, cognitive accessibility, and reliable intervention interfaces. The open challenge is constructing robust infrastructure for such consensus-based workflows, aligning deep knowledge representation with practical control in AI-driven engineering systems.