- The paper introduces AdaLeZO, which adaptively optimizes layer selection in zeroth-order methods to reduce computational overhead and variance in LLM fine-tuning.
- It recasts layer selection as a non-stationary multi-armed bandit problem and employs EMA-based reward smoothing to balance exploration and exploitation.
- Empirical results demonstrate 1.7x–3.0x speedups over traditional methods while maintaining competitive accuracy across various large language models.
Universally Empowering Zeroth-Order Optimization via Adaptive Layer-wise Sampling: A Technical Analysis
Motivation and Critique of Standard ZO Optimization
Zeroth-Order (ZO) optimization has emerged as a memory-efficient solution for LLM fine-tuning, enabling gradient estimation through forward passes. This paradigm circumvents the memory bottleneck imposed by backpropagation, permitting training on consumer hardware. However, conventional ZO methods such as MeZO perform dense, uniform perturbations across all parameters, leading to two core deficiencies: inflated wall-clock convergence time due to linear scaling of perturbation/update operations, and substantial estimation variance—both exacerbated in billion-scale models. The phenomenon dubbed "Policy Blindness" reflects how uniform ZO exploration disregards the inherent heterogeneity in layer sensitivities, resulting in wasteful updates to insensitive parameters.
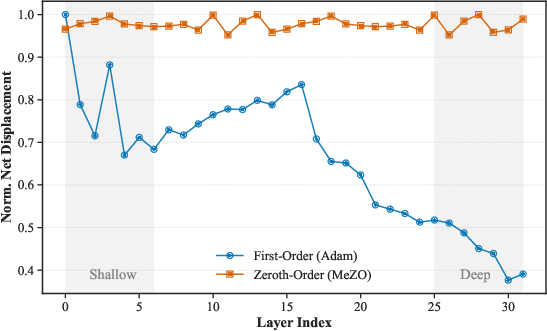
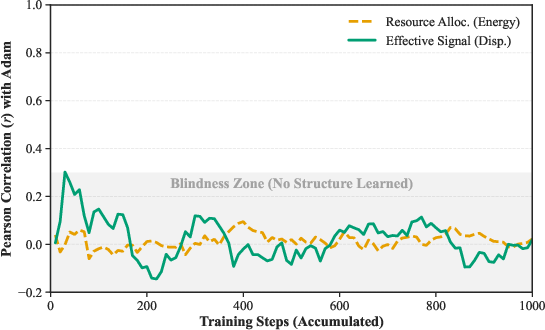
Figure 1: Layer-wise Net Displacement highlighting uniform updates in ZO vs. heterogeneous sensitivity revealed by first-order optimization.
Empirical analyses demonstrate that while first-order optimizers (e.g., Adam) focus updates on select layers, MeZO distributes updates uniformly, squandering computational budget and impeding convergence. System profiling exposes that perturbation and update overheads can comprise up to 46% of total training step latency, forming a scalability barrier for ZO fine-tuning.
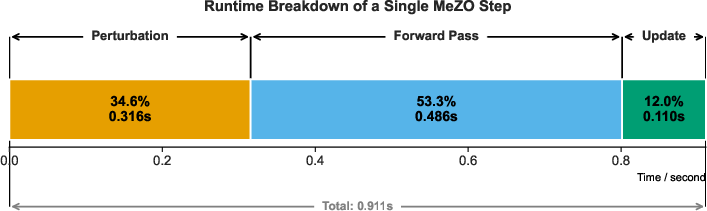
Figure 2: Time breakdown in MeZO showing perturbation and update constituting a major portion of training step time.
AdaLeZO Framework and Algorithmic Innovations
AdaLeZO addresses these structural inefficiencies by recasting layer selection as a non-stationary Multi-Armed Bandit (MAB) problem. The framework adaptively allocates the perturbation budget to sensitive layers based on real-time reward statistics derived from noisy ZO gradient magnitudes. An Exponential Moving Average (EMA) smooths reward signals, and the sampling policy balances exploration and exploitation via a Softmax distribution mixed with uniform exploration to prevent layer starvation.
The sparse gradient estimator employs Sampling with Replacement and a count-aware Inverse Probability Weighting (IPW) mechanism. For each active layer, the update is weighted by the count of times it is sampled and inversely proportional to its sampling probability, subject to clipping for variance control. This ensures unbiased gradient estimation relative to Gaussian smoothed objective while lowering variance and compressing computational overhead.
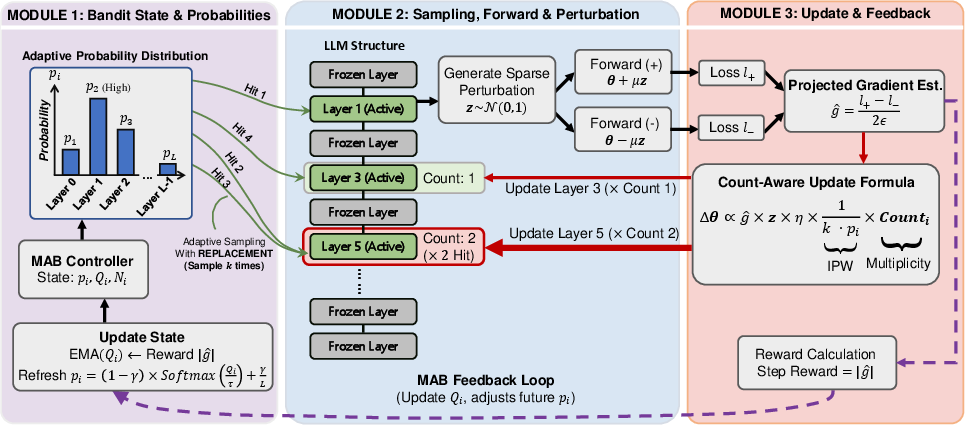
Figure 3: The AdaLeZO workflow—adaptive selection, sparse perturbation, and count-aware IPW update.
Layer selection and update sparsity reduce both perturbation generation and parameter update complexity from O(d) to O(ρd) for d parameters and sampling ratio ρ≪1, yielding significant wall-clock speedups.
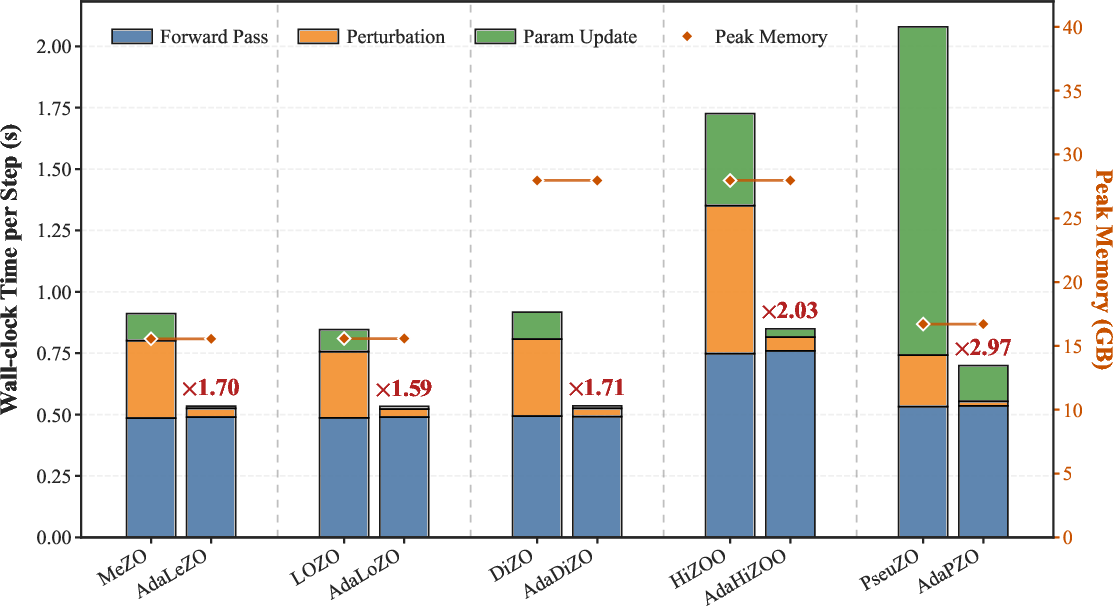
Figure 4: Wall-clock time and memory breakdown; AdaLeZO compresses perturbation/update overhead dramatically compared to dense ZO.
Empirical Results and Ablations
Extensive experiments on LLaMA (2–7B, 3.1–8B) and OPT (6.7B–30B) models across 11 downstream NLP tasks demonstrate that AdaLeZO attains 1.7×–3.0× acceleration relative to MeZO and other ZO baselines, with equal or superior accuracy performance. Notably, AdaLeZO can function as a universal plug-in, synergistically accelerating LoZO, HiZOO, DiZO, and PseuZO, maintaining competitive accuracy at higher throughput.
Ablation studies validate the necessity of adaptive sparsity and variance reduction. The optimality of bandit-driven layer selection is evident; AdaLeZO outperforms random sparse selection by 2.12% on average, confirming that efficiency arises from adaptivity rather than sparsity alone.
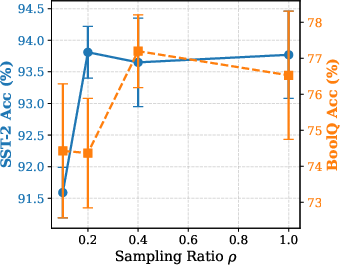
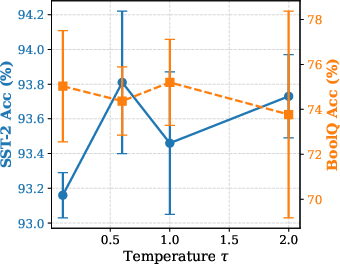
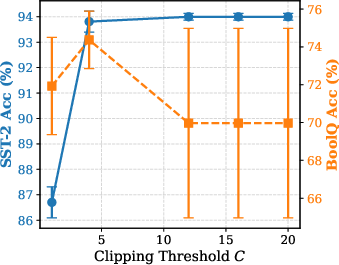
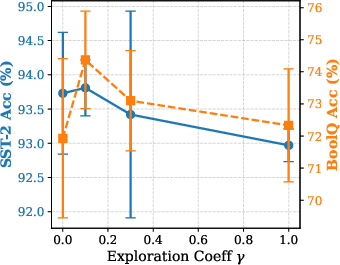
Figure 5: Effect of Sampling Ratio ρ: excessive sparsity impairs accuracy, dense updates degrade due to amplified variance.
Hyperparameter analysis reveals critical bias-variance trade-offs; moderate IPW clipping thresholds and balanced temperature/exploration coefficients are essential for stability. AdaLeZO's approach strikes a balance between rapid adaptation to gradient heterogeneity and robust denoising of stochastic ZO signals.
Structural Learning and Temporal Denoising
AdaLeZO successfully reconstructs layer sensitivity structure using only noisy forward-pass feedback. The temporal aggregation of bandit rewards drives convergence of the layer sampling probability distribution toward the oracle (true gradient norm) profile, with empirical Pearson correlation reaching r≈0.88.
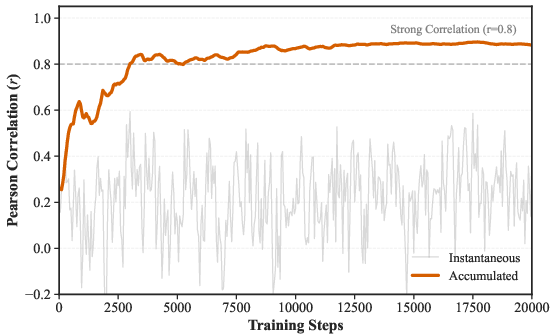
Figure 6: Pearson correlation between AdaLeZO-assigned probabilities and true gradient norms—aggregated statistics approach r=0.88.
Further visualization shows that AdaLeZO, starting from a nearly random policy (r=0.32), converges to strong alignment O(ρd)0 with oracle layer sensitivity, despite absence of any first-order gradients.
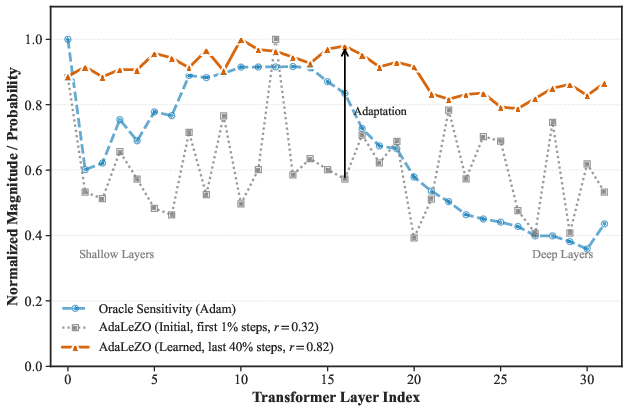
Figure 7: Layer-wise sensitivity alignment: AdaLeZO's adaptive policy evolves to match the true gradient distribution.
Convergence and Theoretical Guarantees
Theoretical analysis establishes that AdaLeZO maintains unbiasedness with respect to Gaussian smoothed gradients and achieves an O(ρd)1 convergence rate for non-convex objectives, similar to standard ZO methods. Variance is tightly controlled via clipping and adaptive sampling, with the dimension dependence O(ρd)2 strictly preserved in the second moment, precluding any paradoxical dimension-free scaling.
Practical Implications and Future Directions
Practically, AdaLeZO enables rapid, memory-efficient fine-tuning of giant LLMs on constrained hardware, removing the linear barrier imposed by dense ZO operations. Its universal compatibility and plug-and-play design facilitate integration with advanced ZO variants and parameter-efficient fine-tuning methods. The ability to reconstruct structural layer sensitivity from low-fidelity scalar rewards opens avenues for adaptive optimization in settings where first-order signals are inaccessible, potentially extending to multimodal architectures and RLHF.
Theoretically, the explicit convergence rate and rigorous variance/bias bounds establish AdaLeZO as a stable sparse ZO optimizer. The multi-armed bandit formulation provides a principled approach to temporal denoising in high-dimensional stochastic optimization.
Further expansion may involve validation beyond NLP—exploring adaptive ZO optimization in vision, multimodal LLMs, and reinforcement learning contexts. Closing the residual performance gap relative to first-order fine-tuning remains a future challenge, along with refinement of structural learning mechanisms for even more granular adaptivity.
Conclusion
AdaLeZO advances the state of ZO fine-tuning for LLMs, breaking the linear computational bottleneck via adaptive layer-wise sparsity and importance-weighted estimation. The framework capitalizes on temporal denoising and structural learning to deliver rapid, stable optimization without memory overhead, forming a robust foundation for scalable, plug-and-play ZO solutions in large-scale AI model adaptation.