- The paper’s main contribution is the UDM-GRPO framework, which redefines RL actions using the final clean sample to ensure stable training for discrete diffusion models.
- It employs forward-process trajectories and a reduced-step strategy to maintain distribution consistency and achieve faster, more reliable convergence.
- Experimental results demonstrate significant improvements in GenEval accuracy, PickScore alignment, and OCR performance, validating its practical effectiveness.
Introduction and Motivation
Uniform Discrete Diffusion Models (UDMs) have demonstrated robust capabilities in discrete generative modeling, particularly for high-fidelity text-to-image synthesis. However, standard training via cross-entropy optimization limits these models' capacity to address objectives such as fine-grained human preference alignment or non-differentiable reward signals. While reinforcement learning (RL)—notably Group Relative Policy Optimization (GRPO)—has boosted alignment and reasoning in language and visual generation, its application to UDMs faces unique instability challenges. This work introduces UDM-GRPO, a principled framework for integrating GRPO into UDMs to realize stable, efficient, and high-performing RL post-training for discrete generative models.
Instability of Naive GRPO Integration
Initial attempts to directly port Flow-GRPO techniques to UDMs, by treating intermediate denoising predictions as policy actions, create significant optimization issues. Reward collapse is observed after transient improvement, with reward oscillation and KL divergence explosion.
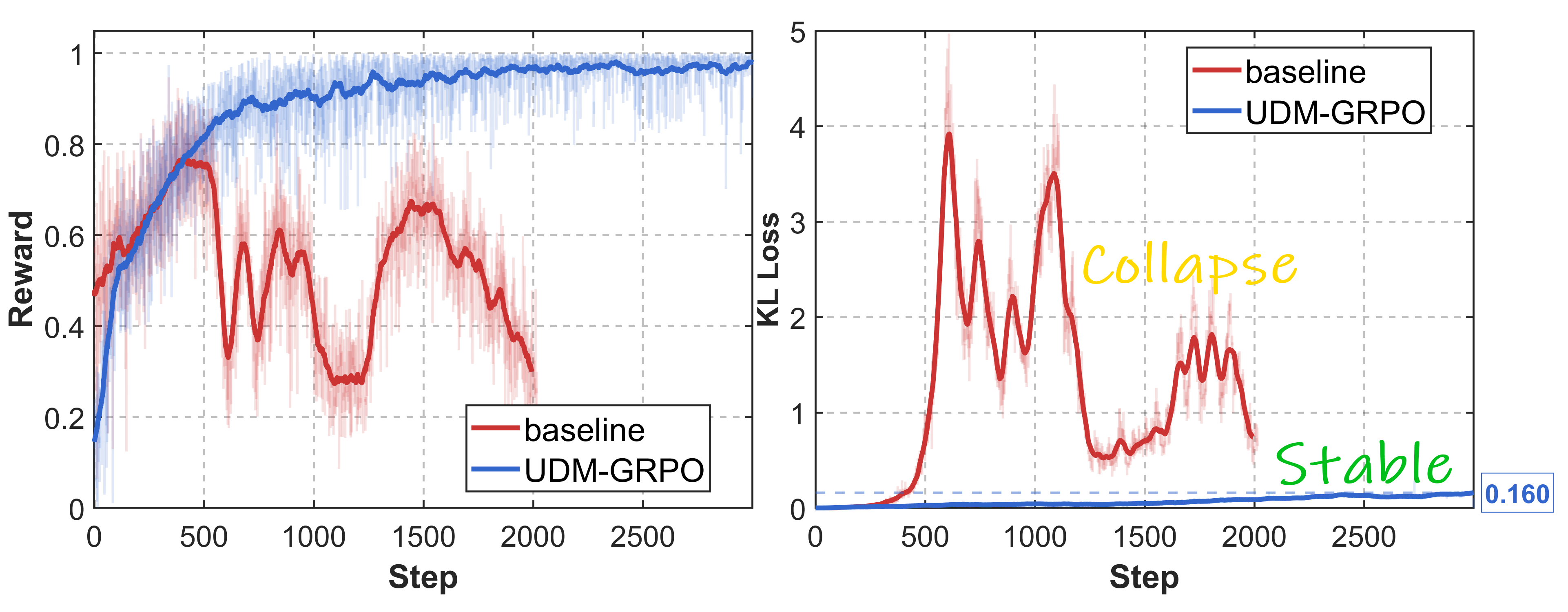
Figure 1: Reward-step training curve. The baseline suffers from catastrophic reward oscillation and exploding KL after initial improvements; UDM-GRPO achieves stable reward increase with bounded KL.
Root causes for this instability are:
- Inaccurate Intermediate Actions: Early diffusion steps yield high-entropy, noisy outputs. Using them as RL actions injects spurious gradients.
- Distribution Shift in Trajectory: Backward (reverse-process) training trajectories diverge from the pretraining (forward-process) manifold, exposing the model to OOD states.
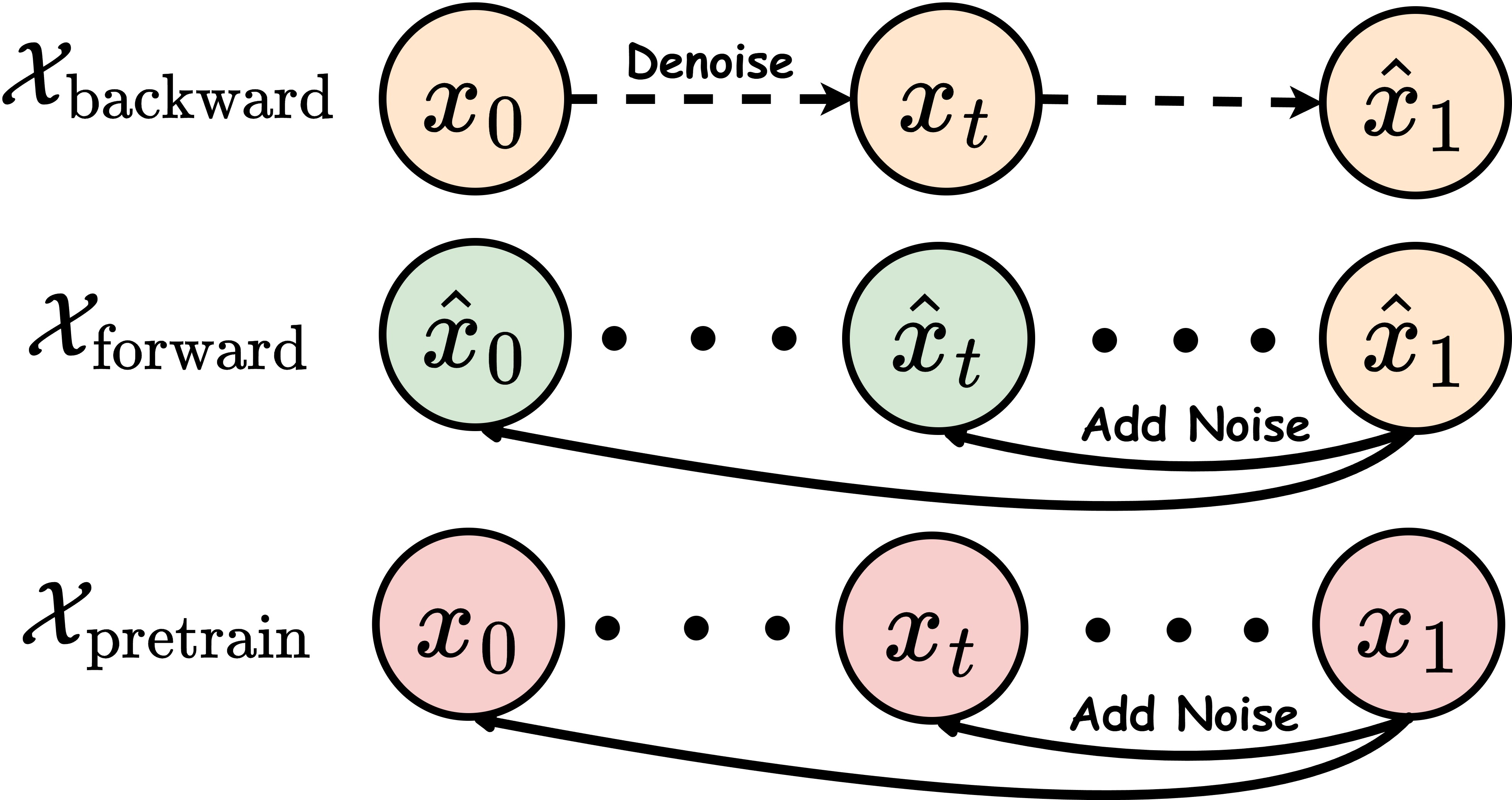
Figure 2: Illustration of the three trajectories (backward, pretraining, forward). Forward trajectories perturb the model’s own clean samples, preserving distributional alignment.
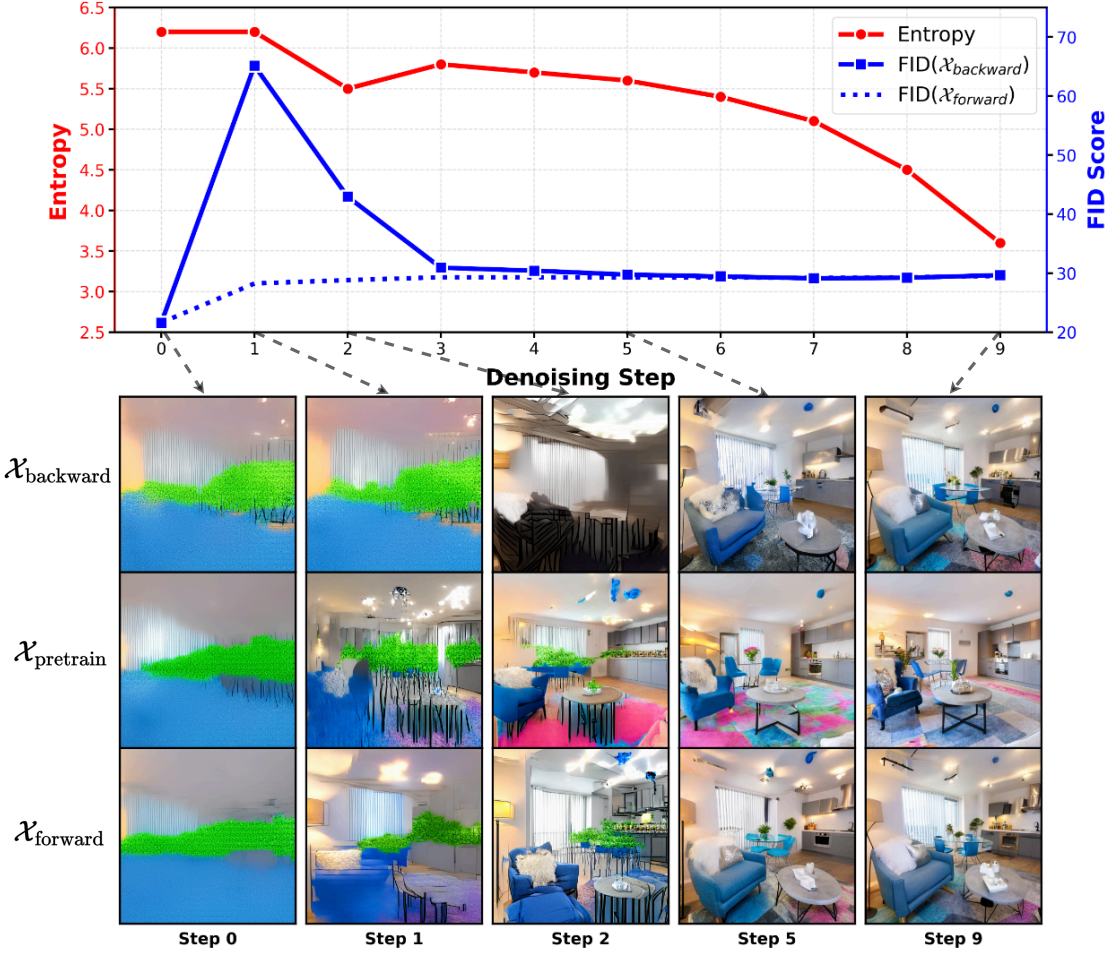
Figure 3: Entropy and FID analyses highlight that early denoising steps introduce high entropy and distribution mismatches when using backward trajectories and intermediate actions.
The UDM-GRPO Framework
Core Algorithmic Designs
UDM-GRPO eliminates the instability by two critical interventions:
- Action Redefinition: The policy action at every timestep is universally set to the final clean sample (x^1), not temporally-local noisy predictions. This ensures the optimization is always reward-aligned and stable.
- Forward-Process Trajectory: Training states are always generated by corrupting x^1 via the forward process. This design maintains strict consistency with the distribution the model was pretrained on, eliminating OOD effects.
Figure 4: Overview of UDM-GRPO. For each prompt, clean images are sampled, perturbed via the forward process (blue path), and used with group GRPO loss. Reduced-Step and CFG-Free strategies further boost efficiency.
Mathematically, RL optimization proceeds over forward trajectories x^t∼pt(x∣x^1) with the group-normalized GRPO loss, computing probability ratios exclusively for final clean samples.
Training Efficiency: Reduced-Step and CFG-Free
- Reduced-Step Strategy: Rather than diffusing gradients over the entire denoising trajectory, policy optimization is concentrated on a few high-noise early steps, driving faster, more stable convergence.
- CFG-Free RL: Classifier-Free Guidance (CFG) is removed during RL, cutting computational burden and, after a short period of degraded sample quality, yielding superior final solutions and lower KL regularization.
Experimental Evidence and Results
Comprehensive experiments demonstrate that UDM-GRPO advances state-of-the-art performance on GenEval compositional reasoning, PickScore user-preference alignment, and OCR-based text rendering evaluations.
- GenEval: URSA (base) accuracy improves from 0.69 to 0.96, outperforming both major continuous (e.g., SD3.5-L, FLUX.1 Dev) and discrete models.
- PickScore: Increases from 20.46 (CFG-free baseline) to 23.81.
- OCR: Rises from 0.08 (baseline) to 0.57, a significant leap for discrete models.

Figure 5: Qualitative comparison of UDM-GRPO vs. SD3.5-L, Flux.1 Dev, and URSA on compositional and preference prompts; UDM-GRPO yields more semantically aligned and artifact-free generations.
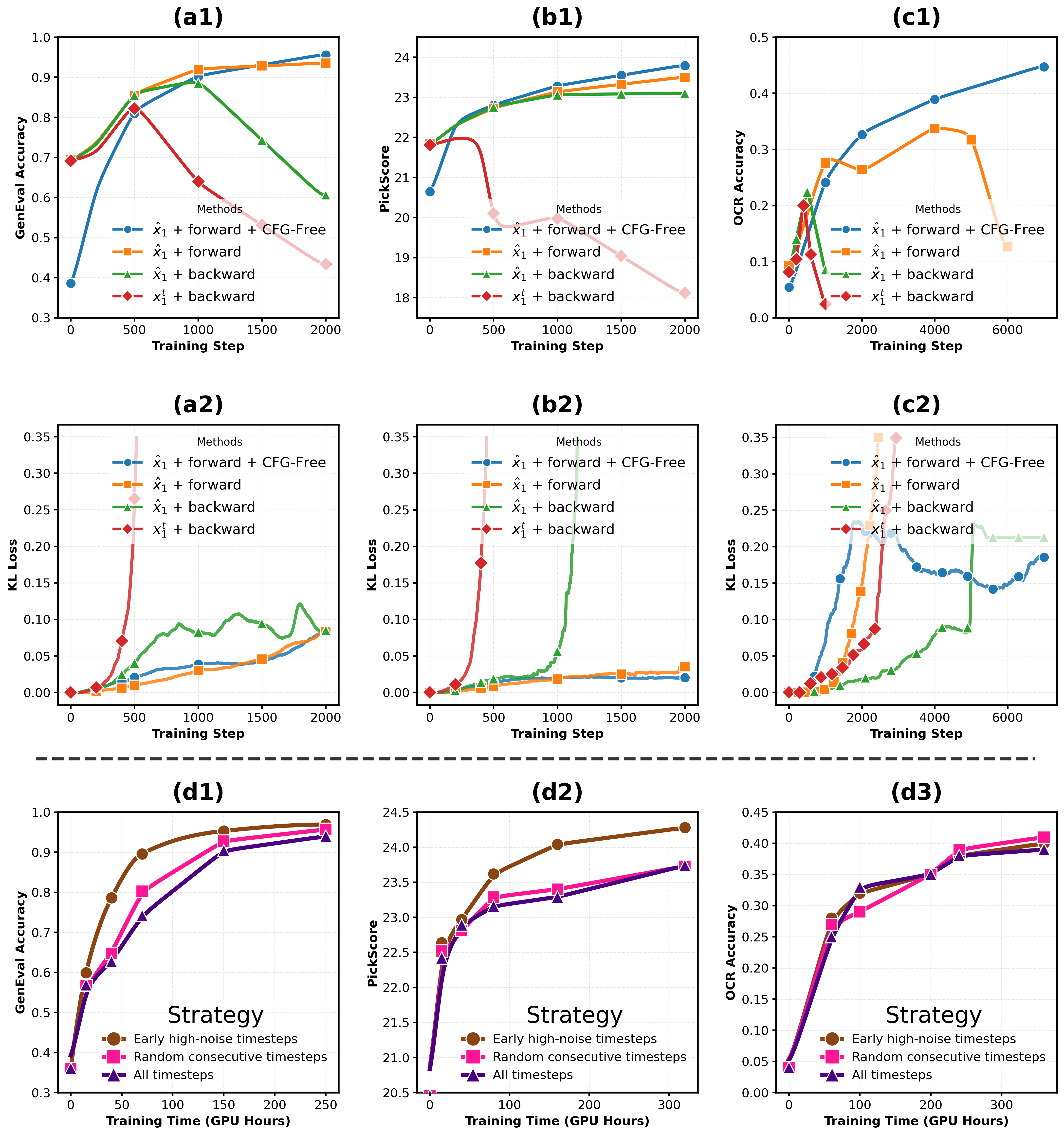
Figure 6: Performance and KL loss curves across GenEval, PickScore, and OCR, with analysis of various timestep optimization strategies; early-step optimization dominates.
Ablation studies indicate that:
(Figure 8, 9, 10)
Figure 8: UDM-GRPO versus SD3.5-L and Flux.1 Dev in challenging scenarios; Figure 9: Visualizations highlighting differences among methods; Figure 10: Progression of sample quality through RL steps.
Theoretical and Practical Implications
The UDM-GRPO paradigm reframes RL for discrete diffusion: rather than local approximations, it globally connects RL loss to the entire pre-trained data manifold. Its design aligns policy updates, reward structure, and sample distribution, minimizing training divergence and collapse risk. This makes large-scale fine-tuning of T2I UDMs tractable, enabling:
- Direct optimization for non-differentiable, user-alignment objectives,
- Systematic compositional reasoning and attribute control,
- Generalization to complex evaluation protocols.
The successful decoupling from CFG during RL and empirically driven step-reduction suggests broader applicability for efficient RL in other discrete and hybrid settings. Future generalizations include multimodal/video diffusion and multi-reward settings, extending UDM-GRPO’s application domain.
Conclusion
UDM-GRPO defines a robust, sample-efficient RL optimization framework for Uniform Discrete Diffusion Models. By globally aligning actions and trajectories to the clean-data manifold and exploiting group-normalized policy optimization, it avoids prior RL-induced instabilities. Empirical results validate its superiority in text-to-image compositionality, user preference alignment, and text rendering tasks. The framework’s inherent scalability, efficiency, and stability highlight its potential as a foundation for subsequent research in discrete generative RL.
(2604.18518)
