- The paper proposes unsupervised calibration by distilling self-consistency from single chain-of-thought outputs, using ridge and isotonic regression to map response embeddings to confidence scores.
- It demonstrates significant improvements in calibration metrics (ECE, Brier scores, and AUROC) across nine reasoning LLMs and multiple datasets compared to existing baselines.
- The method generalizes well under distribution shifts and enhances selective prediction, ensuring robust deployment in scenarios with resource, latency, and privacy constraints.
Unsupervised Calibration of Reasoning LLMs from a Single Generation
Problem Motivation and Deployment Constraints
Reliable calibration of confidence estimates from reasoning LLMs is central for their robust deployment in critical applications such as on-device tutoring, medical triage, and embedded assistants. However, real-world constraints—absence of labeled calibration data and infeasibility of repeated test-time sampling due to resource, latency, or privacy constraints—practically preclude established approaches based on post-hoc recalibration with labeled supervision or multi-sample inference. The work addresses this gap by proposing a method that learns to map a single chain-of-thought output to a calibrated confidence, using only offline access to unlabeled data and sampled generations for weak supervision.
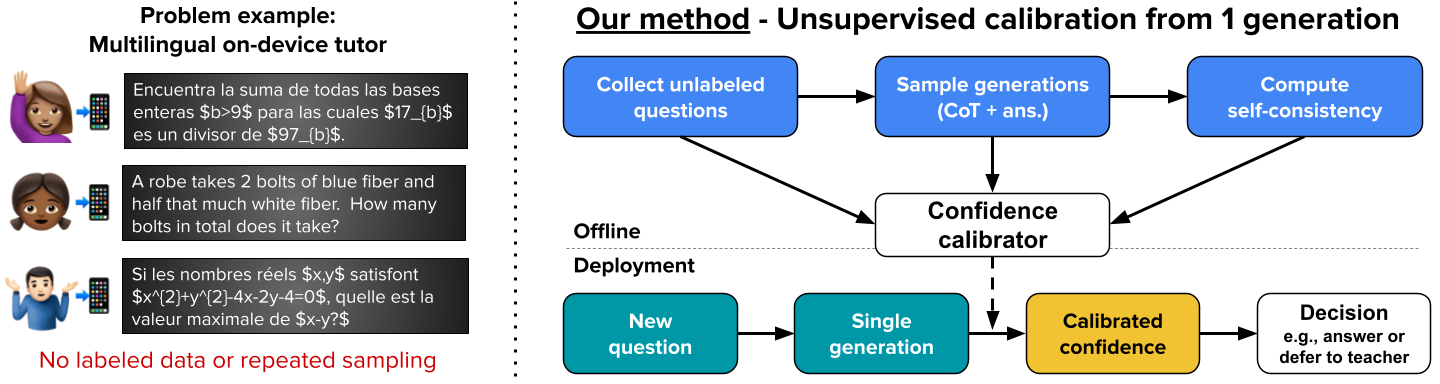
Figure 1: Overview of the deployment setting; unlabeled questions are used offline to train a calibrator mapping a single response to a calibrated confidence estimate for downstream decisions.
Methodology: Self-Consistency Distillation
The central methodological contribution is to amortize a high-quality, but expensive, signal—test-time self-consistency—into a lightweight confidence predictor. The theoretical premise is that answer self-consistency, i.e., the empirical frequency with which repeated model generations yield a particular answer, is statistically well-aligned with actual correctness for reasoning models. Offline, unlabeled calibration examples are used to sample k answers, computing for each a self-consistency proxy. A single sampled response and its self-consistency are paired for weak supervision, yielding {(xi,y~i,si)}. A simple two-stage predictor (ridge regression followed by isotonic regression) is then trained on response features (embeddings post-generation), mapping them to confidence scores approximating answer correctness probabilities.
At inference, only the generated response from the reasoning model is needed; the calibrator predicts a confidence estimate with no additional sampling, fully decoupling calibration from expensive deployment-time computation.
Experimental Results
Comprehensive experiments cover 9 reasoning LLMs (Qwen3, DeepSeek, Nemotron families) and 5 free-form math/QA datasets across 36 model-dataset pairs. Against widely-adopted baselines—token-level probabilities, answer-token probabilities, and verbalized confidence—this distilled self-consistency method achieves substantial improvements in both average and worst-case ECE, Brier scores, and AUROC, consistently closing much of the gap to label-supervised recalibration or full test-time self-consistency.
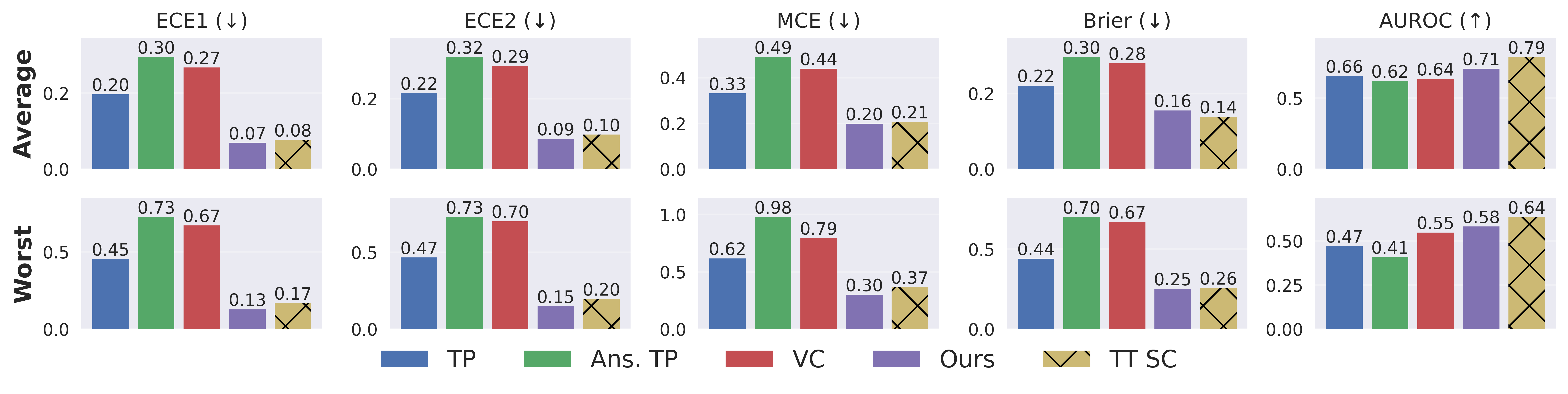
Figure 2: Average and worst-case calibration performance for all models; the proposed scheme is consistently superior to unsupervised baselines and competitive with test-time self-consistency.
Reliability diagrams further demonstrate that the method yields confidence outputs well-aligned to empirical correctness rates across the full confidence range, in contrast to baselines whose output scales are often misaligned or degenerate due to long reasoning chains or context exposure.
Figure 3: Reliability diagrams contrasting the proposed method and unsupervised baselines—only the proposed calibrator consistently places the confidence-accuracy curve near x=y and produces a meaningful distribution of output scores.
Robustness to Distribution Shift and Model Structure
Analysis under distribution shift (cross-language, cross-task, cross-domain) demonstrates that the calibrator generalizes, with only modest degradation, across substantial domain and linguistic changes. In all settings, it remains the strongest unsupervised approach. Notably, the method is robust to replacing internal model embeddings with those from external models—enabling deployment as a fully black-box API wrapper without access to proprietary model internals.
Selective Prediction and Downstream Use
The method's utility for selective prediction is established: confidence-based abstention using the calibrator brings higher accuracy gains over the retained set compared to baselines as the abstention fraction increases. The confidence estimates also reflect the actual difference in accuracy between abstained and accepted examples, ensuring the score distribution remains meaningful.
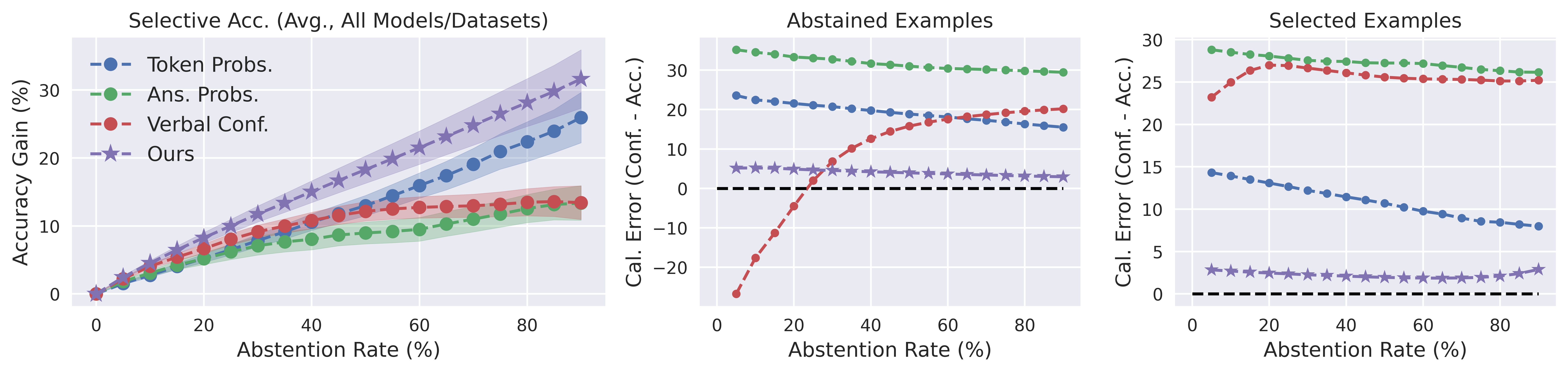
Figure 4: Selective prediction performance—confidence abstention yields steeper accuracy improvements, and average confidence aligns closely with realized accuracy on selected/rejected sets.
Decision utility is assessed in a simulated "linguistic calibration" regime where an external powerful LLM (GPT-4o-mini) is provided with responses and confidence scores from a less-capable LLM (Qwen3). Calibrated confidences from the method yield better downstream decisions and lower calibration error than those from token-probabilities or verbalized confidences, indicating the values are interpretable/useful to other models.

Figure 5: Linguistic calibration—confidence estimates from the proposed calibrator drive the strongest improvements in downstream model calibration.
Positioning in the Calibration and Uncertainty Literature
This work is distinguished from recent unsupervised LLM calibration approaches relying on "base model" token-probabilities (Luo et al., 22 May 2025, Tan et al., 6 Jan 2026) by focusing on reasoning models with long chain-of-thought outputs, where such signals fail due to distribution shift and context complexity. Unlike recent proposals using verbalization or linguistic means (Band et al., 2024), which are computationally more demanding and shown here to be unreliable, the distilled self-consistency predictor offers cost-efficiency and consistent outperformance. The results corroborate findings from [(Wang et al., 2022), 2025] that self-consistency is statistically trustworthy, and extend them by showing that such signals can be successfully distilled for deployment in settings prohibitively constrained for sampling or supervised recalibration.
Limitations and Future Directions
The main limitation is reliance on moderate offline sampling to establish calibration; the empirical ablation study demonstrates robust performance with only 5–10 samples, retaining competitiveness. However, the method cannot correct failures where self-consistency is uninformative (i.e., the model is confidently wrong across samples), as it inherits limitations of model expressivity and ambiguity patterns.
Theoretical advances could explore more expressive or adaptive proxy signals, possibly integrating internal-state-based uncertainty (Chen et al., 2024) or combining with conformal calibration for additional risk guarantees (Zollo et al., 2023). Practically, this line of work indicates that reliable uncertainty quantification for reasoning LLMs can become a default feature in mainstream deployments, including those where compute, privacy, or IP concerns preclude both multi-sample inference and direct access to model parameters.
Conclusion
The paper provides a compelling unsupervised framework for calibrating confidence estimates in free-form reasoning LLMs, leveraging self-consistency as an approximate but robust signal. By amortizing this signal into a deployable calibrator requiring only a single response at inference, the approach overcomes practical barriers faced by established calibration methods. Strong empirical performance, cross-distribution robustness, and downstream decision value position this method as a practical option for widespread deployment in reliability-critical NLP systems.
References:
- Luo & al., "Your Pre-trained LLM is Secretly an Unsupervised Confidence Calibrator" (Luo et al., 22 May 2025)
- Tan & al., "BaseCal: Unsupervised Confidence Calibration via Base Model Signals" (Tan et al., 6 Jan 2026)
- Xiong & al., "Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs" (Xiong et al., 2023)
- Lyu & al., "Calibrating LLMs with sample consistency" [2025]
- Wang & al., "Self-Consistency Improves Chain of Thought Reasoning in LLMs" (Wang et al., 2022)

