- The paper introduces the TSAG framework that integrates LLM agents with external quantitative tools to overcome limitations in numerical precision and temporal reasoning.
- It details a four-layer architecture and benchmark evaluation, demonstrating perfect tool selection and reduced hallucination rates in high-capacity agents.
- The study highlights practical trade-offs for real-time financial AI applications, emphasizing improved reliability through tool-augmentation.
Time Series Augmented Generation for Reliable Financial AI
Introduction and Motivation
The adoption of LLMs for financial quantitative analysis is constrained by their inherent limitations in performing precise numerical computations, reliable temporal reasoning, and robust grounding over high-frequency, volatile time series data. Existing RAG systems, while effective for text-based retrieval tasks, lack the mechanisms to perform verifiable, contextually relevant numerical operations required for sophisticated financial question answering. This paper introduces the Time Series Augmented Generation (TSAG) framework, which operationalizes a Tool-Augmented RAG paradigm, enabling LLM agents to delegate computations to external, curated quantitative tools. This approach directly targets the gap in rigorous evaluation methodologies for agentic reasoning in financial Q&A by isolating the contribution of LLMs from that of underlying analytical tools.
TSAG Framework Architecture and Workflow
The TSAG architecture is stratified into four primary layers: the User Layer (interface, e.g. chatbots), LLM Agent Layer, Tools Layer (Python-based function library), and Time Series Database Layer. The LLM agent is tasked with parsing natural language queries, extracting parameters (using documented defaults for incomplete specifications), selecting the appropriate analytical tool, invoking the tool, and synthesizing the result into an NLR. A deliberate methodological choice during evaluation is to abstract tool execution via stubs returning deterministic outputs, emphasizing assessment of the agent's reasoning independent of live data noise or tool implementation fidelity. The tool library covers essential classes of financial analysis: seasonality/pattern detection, price/volatility metrics, prediction, correlation analysis, and metadata retrieval.
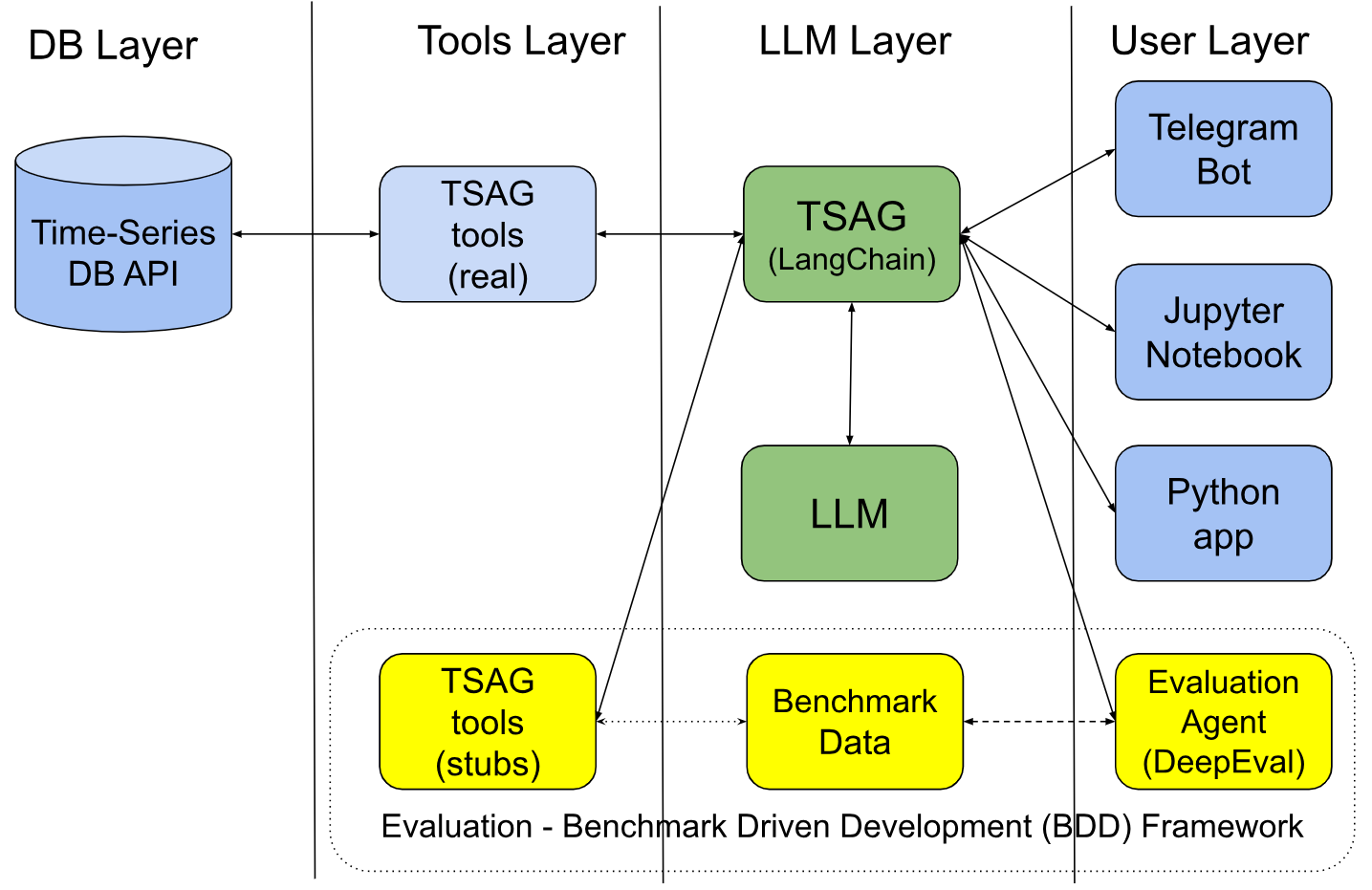
Figure 1: The TSAG Tool-Augmented RAG architecture, mapping natural language queries through an LLM agent to verifiable tool executions and result synthesis.
Evaluation Methodology and Benchmark
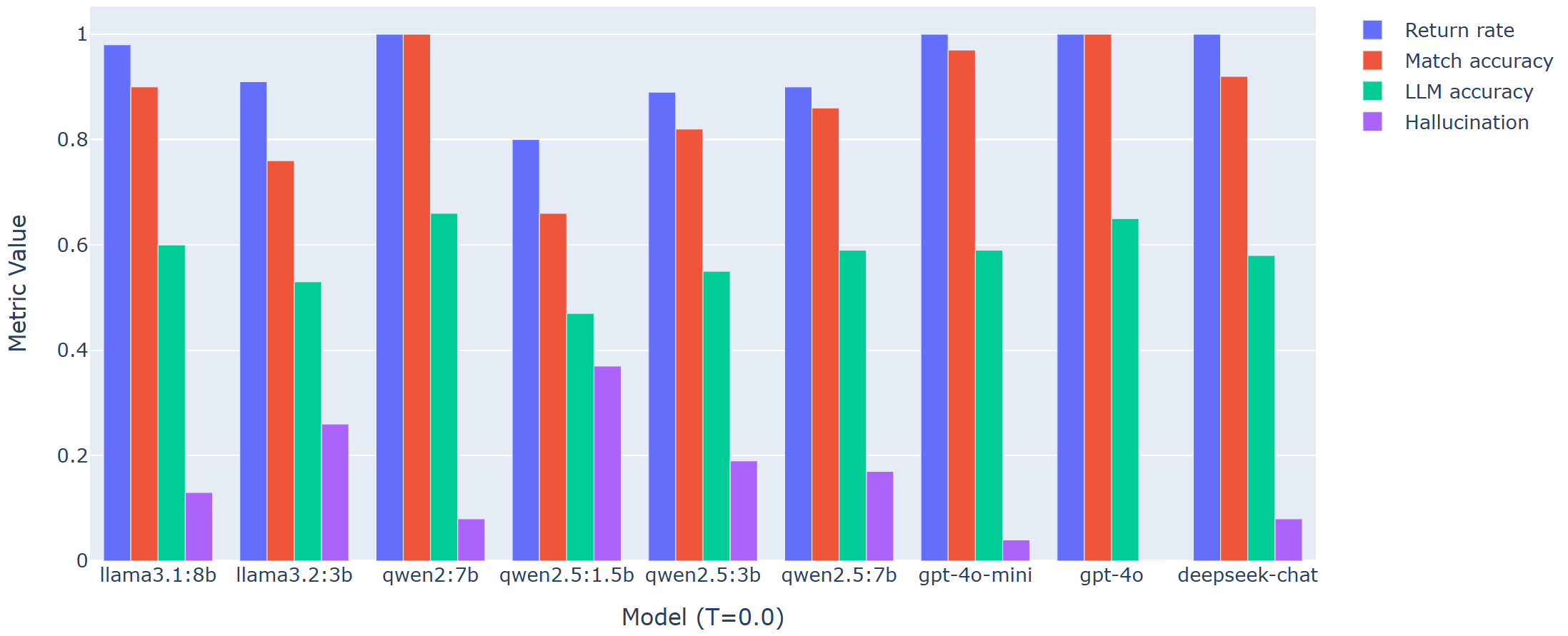
To rigorously quantify the agentic reasoning required for reliable financial Q&A, the authors constructed a benchmark of 100 natural language questions, spanning varying granularity, task complexity, and brevity. Metrics are drawn from both programmatic and subjective axes: Return Rate (RR), Match Accuracy (MA—strict evaluation of tool and parameter selection), LLM-Assessed Accuracy (LA—using DeepEval as an evaluation agent), Hallucination Rate (HR), and Seconds per Query (SPQ). Notably, a strong claim is established: raw LLM baseline models without tool augmentation universally achieve zero Match Accuracy and negligible LA, with correspondingly high HR, highlighting the necessity of explicit tool grounding within the TSAG paradigm.
Empirical Results: Agent Analysis
Comprehensive evaluation is performed using a variety of LLM agents, including Llama 3.x, Qwen2 (multiple scales), GPT-4o, DeepSeek-V3, and others, hosted both locally and via APIs. The primary empirical findings are:
Supplementary analysis at higher temperature regimes reveals increased run-to-run variability for smaller models but maintains performance consistency for agents with sufficient instruction-following and contextualization capacity.
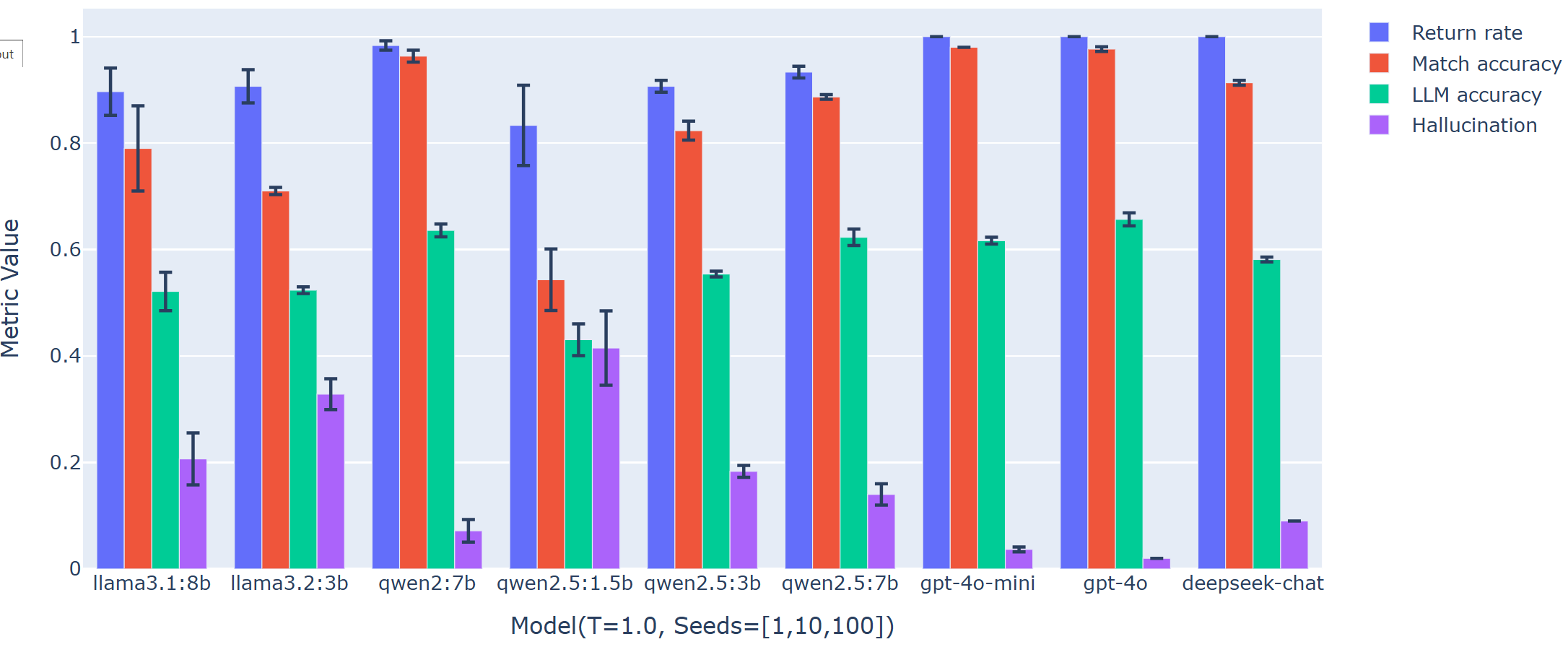
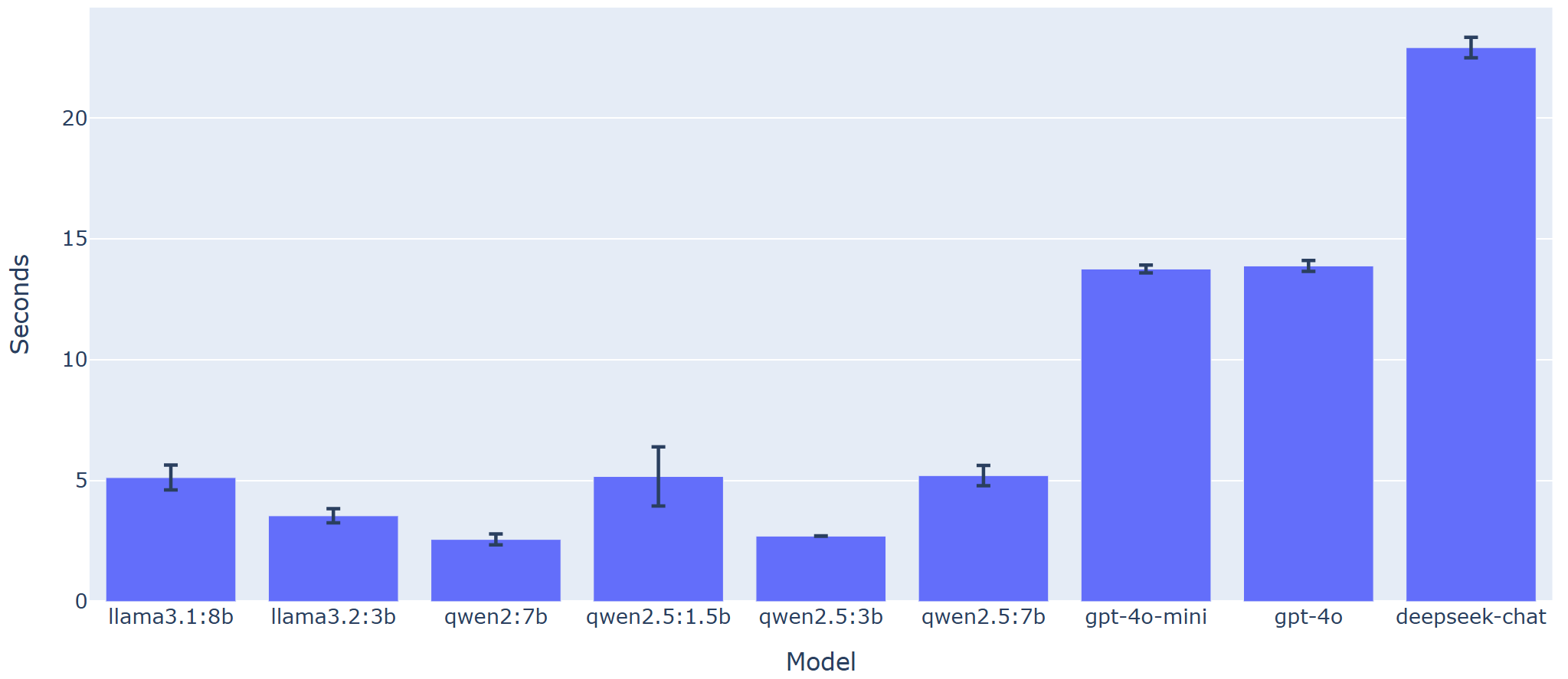
Figure 3: Average metrics over multiple stochastic runs (Temperature=1.0), capturing the mean and error bars for run variability, reaffirming the reliability of high-capacity agents.
Latency measurements demonstrate a decisive trade-off: locally hosted models (Qwen2 7B at 2.2s per query) offer competitive performance at lower response delays relative to API-based solutions (e.g. DeepSeek-V3 at 14s). This is critical for real-time financial applications.
Qualitative Assessment and Application
A front-end deployment as a Telegram chatbot highlights correct tool selection and parameter extraction in diverse query contexts, with failures traceable to either ambiguous phrasing or insufficient tool coverage.
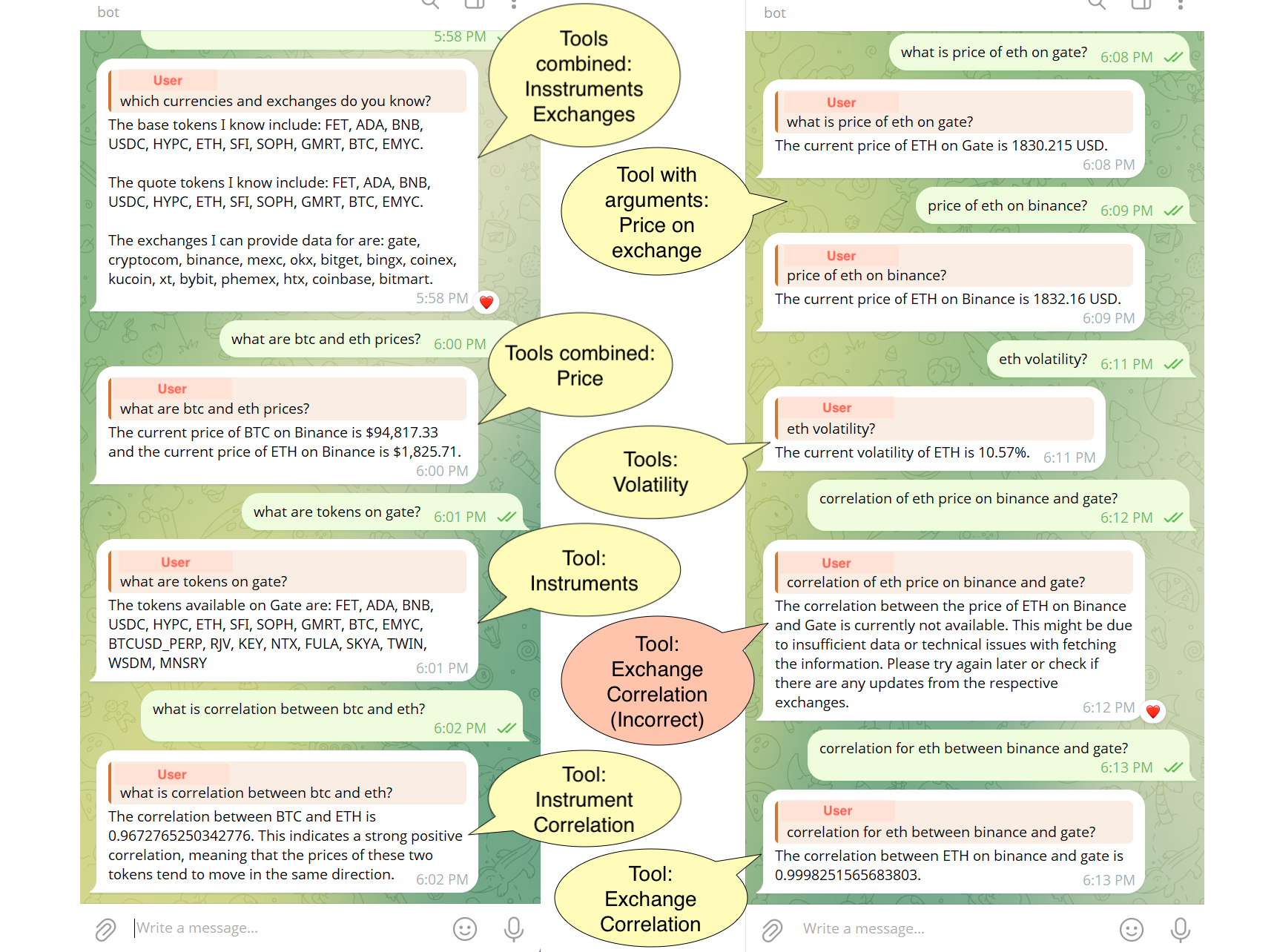
Figure 4: Telegram chatbot interface for TSAG, illustrating both successful multi-tool query resolution and an instance of incorrect tool assignment.
Manual review corroborates the quantitative metrics: successful responses feature correct mapping of natural language to tool invocation and accurate incorporation of computed values into natural language outputs. Failure cases predominantly arise from the selection of an incorrect tool or incomplete parameterization.
Implications, Limitations, and Future Directions
The empirical results strongly confirm the utility of the TSAG approach—by abstracting complex quantitative reasoning into a curated, verifiable set of functions, it overcomes the factuality deficiency of ungrounded LLM outputs on financial Q&A tasks. The framework demonstrates that robust instruction following and compositional reasoning for tool selection and parameter extraction are emergent capabilities of larger models, raising the practical bar for model selection in production settings.
The limitations are primarily rooted in the finite scope of pre-defined tools, absence of dynamic code generation for handling truly out-of-distribution queries, brittleness to input paraphrasing, and a current focus on crypto-finance use cases. The lack of multi-step compositional reasoning restricts the answer space to single-tool queries. Baselines are limited to generic LLMs; future work could examine competitive performance from finance-specialized LLMs not utilizing tool augmentation.
Potential future research avenues include:
- Extension of tool coverage to encompass more sophisticated analytic and forecasting models
- Incorporation of agentic planning frameworks (e.g., ReAct) and Chain-of-Thought augmentation for multi-step compositionality and explainability
- Benchmarking under paraphrased and adversarial query regimes to investigate robustness and linguistic generalization
- Integration of uncertainty quantification and bias audits for responsible financial AI
Conclusion
The TSAG framework offers a methodologically rigorous and empirically validated solution to the challenge of reliable, explainable financial Q&A with LLM agents. The public release of a benchmark and evaluation pipeline sets a precedent for standardized assessment in this domain. These findings reinforce tool-augmentation as a pragmatic, scalable strategy for enabling LLMs to deliver factually grounded, high-stakes analysis in financial applications, conditional on model capacity and tool library adequacy. The approach constitutes a robust foundation for further work on compositional, agentic, and domain-specialized financial AI.