- The paper introduces a two-stage training pipeline combining supervised fine-tuning with agentic reinforcement learning to enable high performance on deep research tasks.
- It leverages rigorous data filtering and turn-aware resampling to enhance evidence integration and execution reliability at edge-scale.
- Dense turn-level rewards through IGPO allow the 4B model to rival larger systems by reliably performing long-horizon information-seeking tasks.
DR-Venus: Edge-Scale Deep Research Agents from Limited Open Data
Introduction
DR-Venus advances the development of agentic LLMs optimized for deep research tasks at edge-scale, utilizing a parameter budget of only 4B and trained strictly on open data. In the context of long-horizon information-seeking, DR-Venus addresses the dual challenges of maintaining strong agentic capabilities and execution reliability, under constraints of data scarcity and resource efficiency. The approach revolves around a two-stage training pipeline: supervised fine-tuning (SFT) augmented by rigorous data filtering and trajectory resampling, followed by agentic reinforcement learning (RL) employing dense turn-level rewards. The resultant agent exhibits competitive performance relative to 9B and even 30B-class models across diverse benchmarks, raising critical considerations regarding the importance of data quality and utilization vis-à-vis model scale.
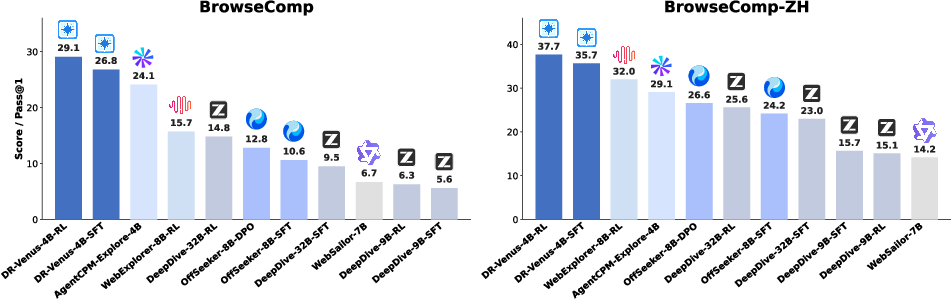
Figure 1: Performance comparison of DR-Venus-4B against other open-source models on BrowseComp and BrowseComp-ZH.
Training Pipeline and Methodological Innovations
Supervised Fine-Tuning (SFT)
The SFT stage leverages a curated subset of REDSearcher trajectories, subject to multi-stage filtering:
- Environment alignment: Ensures protocol-consistency between training and inference, focusing exclusively on search and browse tools.
- Structural pruning: Removes disallowed tool invocations and duplicate interactions, optimizing signal-to-noise ratio.
- Correctness filtering: Retains only trajectories with validated answers, employing LLM-based judges for reliable supervision.
- Turn-aware resampling: Upweights trajectories with greater interaction depth, redistributing supervision density toward long-horizon tasks.
This pipeline markedly enhances supervision quality and models basic interaction primitives—reasoning, evidence accumulation, and tool use—critical for deep research contexts.
Agentic Reinforcement Learning (RL) with IGPO
Following SFT, RL is applied via Information Gain-based Policy Optimization (IGPO), designed to maximize information acquisition per turn:
- Dense turn-level rewards: IGPO evaluates each interaction on information gain relative to the ground truth, providing granular credit assignment.
- Format-aware regularization: Penalizes malformed outputs at the turn-level, rather than the trajectory-level, increasing stability for long-horizon execution.
- Browse-aware reward assignment: Rewards are allocated primarily to browse actions and preceding search turns, reflecting the empirical importance of evidence inspection over shallow retrieval.
- Normalization and IG scaling: Improves reward balance, preventing over-reliance on sparse outcome signals in ultra-long-horizon settings.
- Discounted reward propagation: Model updates incorporate future reward implications, facilitating planning over extended horizons.
This methodology substantially improves execution reliability and tool-use calibration, outperforming more conventional trajectory-level RL variants (e.g., GRPO) in complex agentic settings.
Empirical Evaluation
Benchmarks and Baselines
DR-Venus is evaluated on six major agentic and deep research benchmarks—BrowseComp, BrowseComp-ZH, GAIA (Text-Only), xBench-DS variants, and DeepSearchQA—against baselines spanning foundational models, large trained agents (≥30B), and small agents (≤9B). Both SFT and RL variants of DR-Venus consistently outperform prior open-source models at similar scale, and in many cases approach or surpass larger systems.
Numerical Results and Claims
DR-Venus-4B-SFT establishes a strong baseline, exceeding prior 4B–9B models by substantial margins across BrowseComp (+2.7), BrowseComp-ZH (+6.6), GAIA (+1.5), and DeepSearchQA (+4.9). RL further improves results, e.g., BrowseComp (+2.3), BrowseComp-ZH (+2.0), and xBench-DS (+5.7), with gains closely correlated to improved formatting, tool-use stability, and correct answer generation. The claim that “strong deep research performance is not determined by model scale alone” is substantiated by DR-Venus-4B surpassing several larger agents and narrowing the gap to 30B-class systems.
Ablation and Boundary Analysis
Turn-aware resampling is shown to specifically enhance SFT performance (+4.0 on BrowseComp), validating the importance of focused supervision distribution. IGPO’s dense reward assignment renders RL effective in settings where conventional sparse RL algorithms fail to yield improvement.
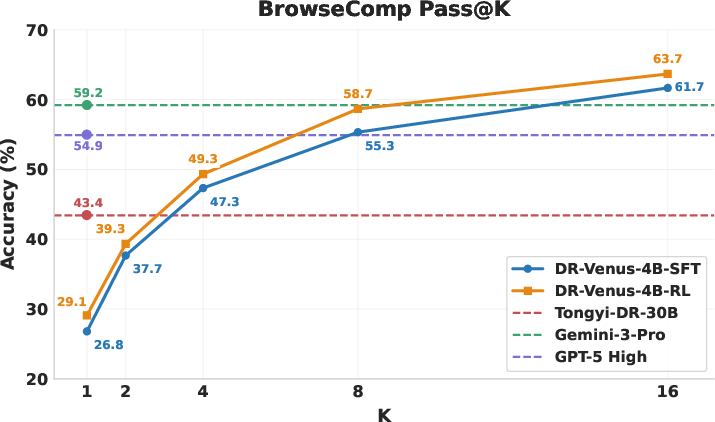
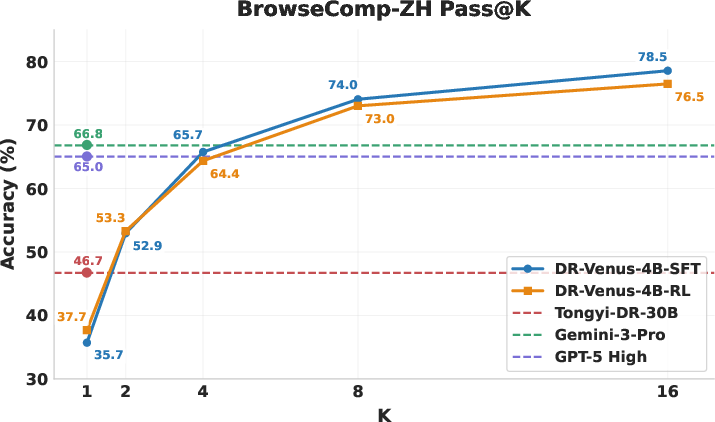
Figure 2: Pass@K performance of DR-Venus on BrowseComp (left) and BrowseComp-ZH (right), highlighting the reliability and latent capability boost conferred by RL.
Pass@K analysis demonstrates that the capability ceiling of small agents is markedly underestimated at low sampling budgets; with adequate sampling (high K), DR-Venus-4B achieves performance rivaling or exceeding proprietary or much larger models. RL optimizes reliability, especially in low-K settings, enhancing practical deployment characteristics at edge-scale.
Browse ratio measurements reveal that correct trajectories consistently employ browsing actions more than incorrect ones, a pattern intensified by RL. The browse-to-search shift is indicative of successful evidence integration, rather than reliance on cursory search snippets.
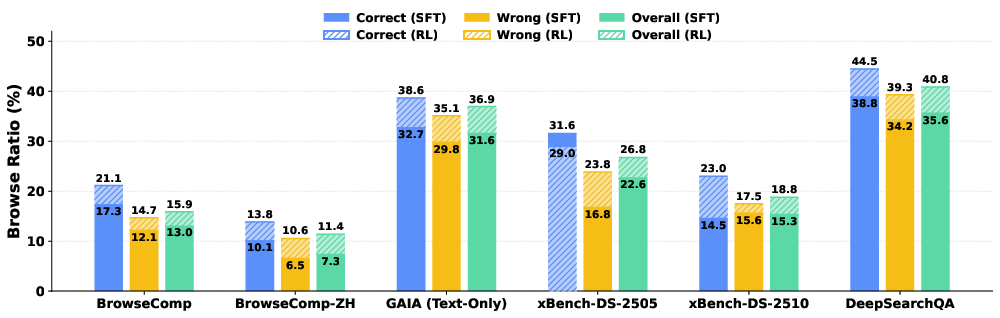
Figure 3: Browse ratio distribution across correct, wrong, and total trajectories for SFT and RL, evidencing RL-induced calibration toward effective evidence acquisition.
RL not only increases overall browsing frequency but also aligns tool-use patterns with task success, steering the agent toward deeper evidence aggregation—a decisive competency in long-horizon research tasks.
Implications and Future Directions
The implications are multifold:
- Edge deployment: 4B-scale agents trained on open data offer viable performance for privacy-sensitive, latency-critical applications, challenging the paradigm that scale is a prerequisite for strong agentic reasoning.
- Data-centric optimization: Performance gains are attributable to improvements in data quality and utilization, reinforcing the value of data-centric model development, especially under resource constraints.
- RL refinement: Dense, information-gain-driven rewards and turn-level credit assignment are essential for robust agentic RL at small scale, suggesting future RL research should prioritize granular reward design and behavioral stabilization.
- Test-time scaling: High Pass@K scores suggest that test-time sampling and context scaling strategies could further amplify small model capabilities, with implications for generalized reasoning assistants.
Further studies should investigate cross-lingual RL data integration, tool expansion beyond search/browse, and adaptive context management for open-ended research scenarios.
Conclusion
DR-Venus establishes a competitive new baseline for edge-scale deep research agents with only 10K open-source trajectories. The two-stage pipeline—curated SFT followed by IGPO RL—demonstrates that systematic data curation and utilization strategy are pivotal for maximizing agentic competence in small models. The efficacy of dense turn-level RL, in tandem with browse-aware reward allocation and format regularization, points toward robust future directions for agentic model training under open data constraints. DR-Venus contributes practical recipes, released resources, and empirical evidence, forming a foundation for subsequent research into cost-effective, high-reliability agentic systems.