- The paper presents a three-layer trust framework mapping human, interaction, and technical criteria to address misaligned trust in mental health AI.
- It synthesizes multidisciplinary literature to reveal that subjective user trust diverges from objective system reliability, highlighting the risk of miscalibration.
- The framework advocates for trust calibration through human oversight and adaptive design, aligning regulatory, clinical, and technical perspectives.
Multi-Layer Stakeholder Alignment for Trust in Mental Health AI
Fragmentation and Disciplinary Divergence in Trust Frameworks
The construct of "trustworthy AI" in mental health support (MHS) is characterized by disciplinary fragmentation and conceptual ambiguity. The discipline network synthesized from 1,706 papers between 2021–2025 (Figure 1) reveals a landscape with strong disciplinary silos: technical work in NLP/AI focuses on algorithmic robustness, explainability, and safety, while practitioners and behavioral scientists emphasize clinical effectiveness, therapeutic alliance, and context-aware trust signals. Platform providers, regulators, and ethicists further complicate the scene with requirements for risk mitigation, transparency, and accountability.
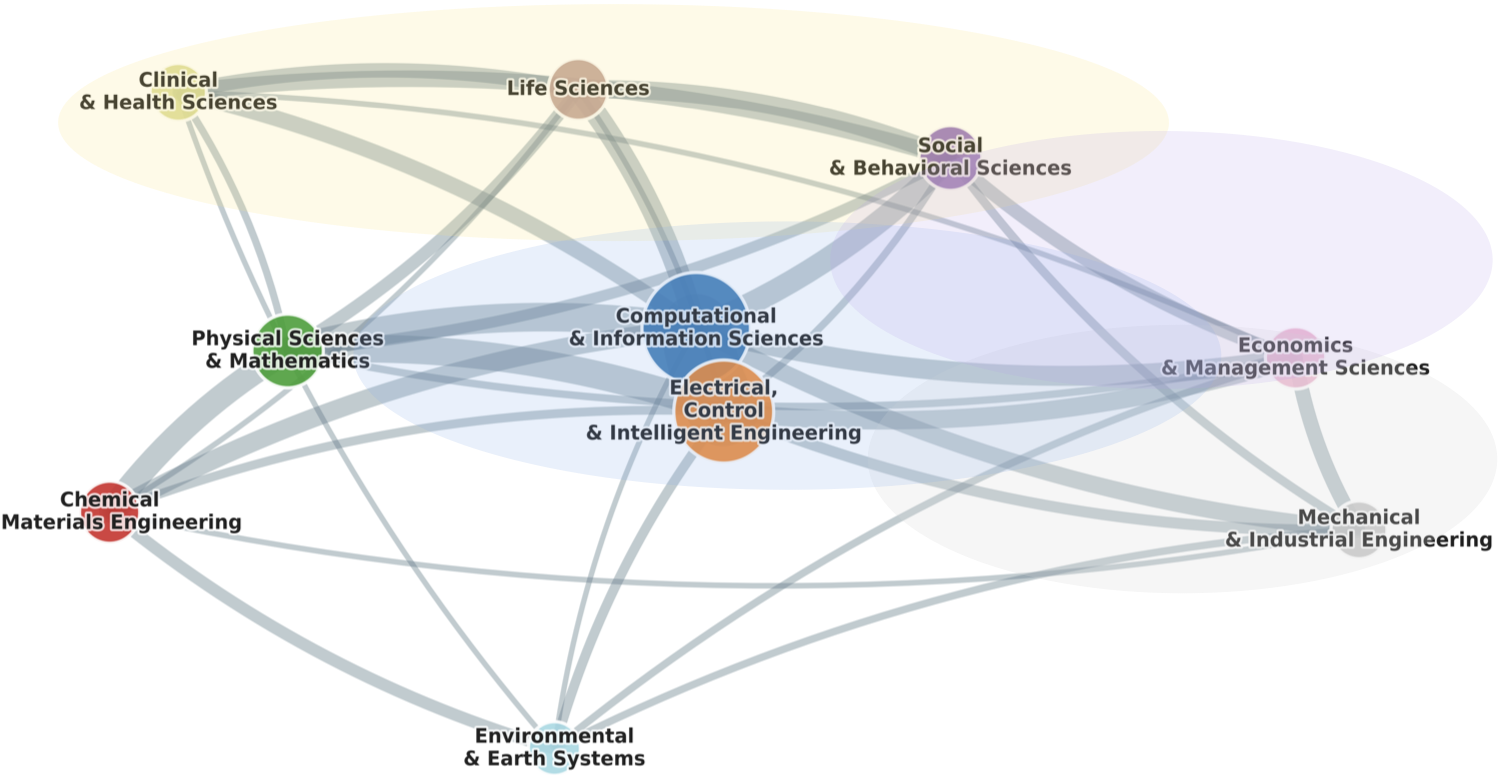
Figure 1: The discipline network of MHS-AI literature demonstrates high volume yet weak integration across disciplinary boundaries, underscoring the necessity for an integrative trust framework.
This persistent misalignment, where technical and relational trust criteria are separately operationalized, creates critical gaps in evaluation and deployment. For instance, while AI benchmarks optimize for BLEU scores or adversarial risk, clinicians prioritize calibration to user needs and regulatory compliance, and HCI researchers focus on trust signaling via interaction design. This status quo limits the translation of AI advancements into clinically meaningful and safe MHS systems.
Three-Layer Trust Framework: Structure and Stakeholder Mapping
To address the disciplinary fragmentation, the paper introduces a structured three-layer trust framework, stratifying trust into human-oriented, interaction-oriented, and AI-oriented trustworthiness (Figure 2). Each layer is mapped to corresponding stakeholder domains and operationalized criteria:
- Human-oriented trust: User perceptions, including subjective feelings of trust, reliance behaviors, anthropomorphism, and explainability as experienced—not merely stated—by users.
- Interaction-oriented trustworthiness: Emergent properties of trust as negotiated through system interaction, focusing on aspects such as contextual competence, conversational safety, transparency, empathy, controllability, and feedback.
- AI-oriented trustworthiness: System-level criteria such as robustness, safety, privacy, fairness, explainability, and evaluation reliability, which are primarily specified, measured, and guaranteed at the algorithmic and infrastructural level.
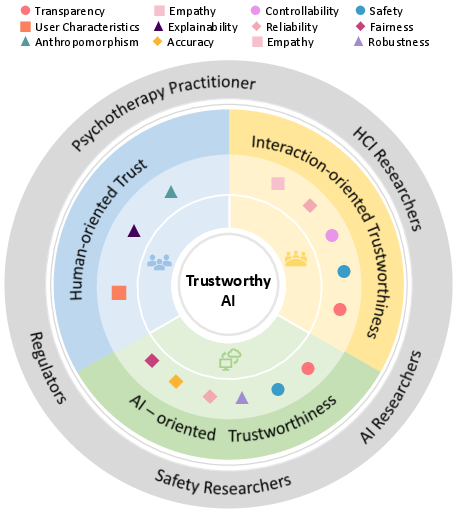
Figure 2: The three-layer trust framework combines five stakeholder perspectives, mapping each to specific criteria and methods at the human, interaction, and system layers.
This framework unifies disparate stakeholder priorities and grounds them in concrete evaluation protocols, facilitating a structured review of both existing literature and real-world evaluation practices.
Human-Oriented Trust: Subjective and Relational Dimensions
Human-oriented trust is anchored in multi-dimensional trust theories (e.g., ABI, MATCH), operationalized through a variety of validated scales and behavioral measures targeting perceived reliability, agency, competence, anthropomorphism, and user literacy. Empirical results show that perceived trust can strongly diverge from actual system trustworthiness—especially among users with low AI literacy, who are prone to over-reliance even when safety is not objectively verified.
Human-in-the-loop designs consistently increase user trust, reflecting the clinical demand for accountability and oversight. However, increasing anthropomorphism or explainability can lead to miscalibrated trust, particularly if not complemented with valid interaction and system-level safeguards.
This layer operationalizes trust through dialogue behaviors: competence, reliable application of therapeutic protocols, safety filtering during crisis interaction, and transparent communication of capability and limitations. The literature demonstrates a spectrum of implementations: script-adherence for protocol alignment, modular escalation for crisis management, and structured explainability for user comprehension.
Systems with high interaction quality (empathetic, engaging conversational strategies) can artificially boost perceived trust absent real safety, while rigid safety interventions can reduce user engagement and alliance. The evidence suggests the necessity of adaptive, context-aware mediation that dynamically balances safety with therapeutic engagement. Protocol-based evaluation, user interviews, and expert scoring dominate as metrics, but there is a lack of standardized practices linking these interactional measures to robust system-level performance indicators.
AI-Oriented Trustworthiness: Technical Foundations and Evaluation Gaps
AI-oriented trustworthiness encompasses technical assurances of reliability and safety including adversarial robustness, privacy guarantees (differential privacy, federated learning), explainability (RAG, chain-of-thought, multi-agent workflows), and demographic fairness. Notably, the literature documents significant output variability and instability in LLMs under both in-distribution and adversarial settings. Bias audits and group fairness assessments reveal uneven performance, with empirical disparities in support provided to marginalized or vulnerable populations.
There is also a prominent risk of over-reliance on automatic metrics (e.g., LLM-as-a-judge), as these can introduce systematic evaluation biases, amplifying mis-calibration between perceived and real trustworthiness.
Regulatory and Safety Constraints
The framework incorporates regulatory standards and ethical guidelines (e.g., FDA, NIST AI RMF, EU AI Act, APA, Pillay 2025), which converge on autonomy, informed consent, beneficence, privacy, justice, and accountability. These frameworks formalize essential constraints: transparent disclosure of AI use, strict privacy and security, risk mitigation, bias auditing, and the necessity of human oversight—conditioning technical progress with enforceable minima.
From Trust Maximization to Trust Calibration: Research and Practical Implications
The paper's critical position is an explicit advocacy for "trust calibration" over "trust maximization." The empirical literature demonstrates that maximizing interaction cues (anthropomorphism, empathic language) may elevate subjective trust without a corresponding increase in safety or competency—a disconnect that is especially hazardous in MHS. The transition to trust calibration implies that system design, evaluation, and deployment should prioritize the alignment of user trust with true system reliability, risk management, and capability—rather than comfort or perceived human-likeness alone.
- At the human layer: Trust measurement should be multidimensional, focusing on detection of over-reliance and expectation mismatch rather than aggregate trust levels.
- At the interaction layer: Trust signals (e.g., anthropomorphism, transparency) should function as regulatory cues, actively moderating user expectations and signaling the boundaries of system competence.
- At the AI layer: Technical criteria must be made observable and interpretable in the interaction, with robust evaluation (including adversarial auditing and human oversight) as a precondition for clinical or high-stakes deployment.
This calibration paradigm calls for integrated, multi-layered benchmarks, standardization of cross-layer evaluation, and rigorous socio-technical alignment across development, governance, and deployment.
Conclusions
The paper provides an overview and reorganization of the trust landscape for mental health AI, bridging disciplinary perspectives through a three-layer, stakeholder-aware framework. The central argument—that trust failures are not isolated at the system or interface level but are emergent from socio-technical misalignment—has both regulatory and methodological implications. Effective trustworthy AI for MHS will depend on (1) explicit multi-stakeholder collaboration across all layers, (2) calibrated trust signaling, and (3) the prioritization of socio-technical evaluation over siloed technical or subjective metrics.
The proposed framework thus serves as both a diagnostic and prescriptive guide for research, evaluation, and policy in trustworthy mental health AI, providing a structural path toward responsible alignment and real-world safe adoption.
References
- "Aligning Human-AI-Interaction Trust for Mental Health Support: Survey and Position for Multi-Stakeholders" (2604.20166)