- The paper presents the naila system, demonstrating that one-shot LLM feedback significantly predicts higher exam scores among over 900 SE students.
- It details a modular design with parameterizable prompt templates that enable scalable and GDPR-compliant feedback in multi-program SE courses.
- Empirical evaluation using TAM surveys and regression analysis reveals that iterative remedial feedback is less effective in promoting robust conceptual learning.
Autonomous LLM-Generated Feedback at Scale: The naila System in Introductory Software Engineering Education
Introduction and Contextual Challenges
The paper "Autonomous LLM-generated Feedback for Student Exercises in Introductory Software Engineering Courses" (2604.20803) addresses the growing scalability and pedagogical challenges in undergraduate software engineering (SE) courses precipitated by increasing enrollments, interdisciplinary student backgrounds, and the widespread use of GenAI solutions. At the University of Duisburg-Essen (UDE), the annual compound rate for enrollment in the introductory SE course reached 32.7%, expanding the class to encompass multiple degree programs—a significant pressure point for traditional feedback delivery mechanisms.
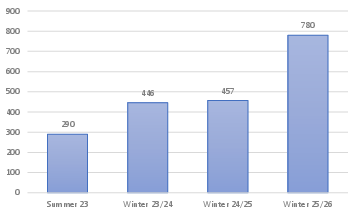
Figure 1: Annual participation growth in UDE's introductory SE course, indicating a 32.7% CAGR.
This heterogeneity extends beyond registration statistics; students from diverse academic programs participate (Figure 2), and approximately 89% self-report at least intermediate experience with GenAI tools (Figure 3), intensifying the need for automated, robust, and pedagogically aligned feedback systems in formative digital education contexts.
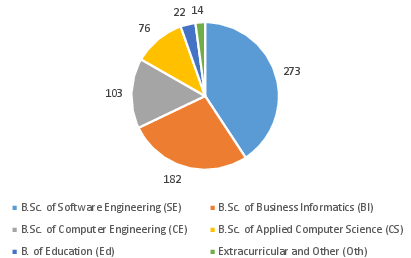
Figure 2: Degree program distribution among SE course participants (N=670).
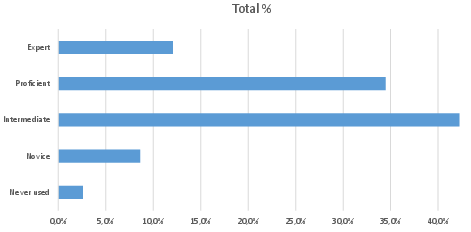
Figure 3: Distribution of students’ self-reported AI experience (N=116).
naila: System Architecture and Prompting Strategy
The naila system realizes an autonomous, LLM-driven feedback and grading pipeline for open-document-formatted exercises. The architecture ingests ODT files, extracts question regions marked by conventional hashtags for targeted answer placement and point allocation, then integrates both model answers and flexible prompt templates.
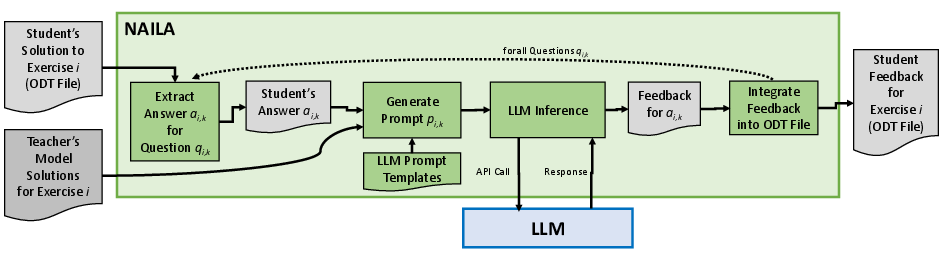
Figure 4: Data flow and modular structure of the naila feedback system.
Prompt templates are parameterizable: (1) “close match” (full alignment with model answers), (2) “partial match” (coverage of a subset of expected points), and (3) “flexible match” (allowing for semantically equivalent, well-argued alternatives). The actual LLM implementation utilizes Gemini 2.5 Flash, prioritizing low-latency inference with sufficient generative quality. System deployment leverages a containerized stack on Google Cloud, with identity management and pseudonymization for GDPR and AI Act compliance.
Empirical Evaluation: Methodology and Survey Design
The empirical assessment focused on four research questions: (RQ1) usage motivations and barriers, (RQ2) self-reported learning experience (Technology Acceptance Model—TAM), (RQ3) behavioral engagement patterns, and (RQ4) correlation with academic outcomes.
Survey & Usage Data Collection Paradigm
Analysis drew from a cohort of over 900 active course participants, with naila adoption being optional (n = 314). Self-reported and behavioral data were synthesized via voluntary TAM-based questionnaires and in-situ system usage logs.
Results
User Motivation and Barriers
Exam preparation was the dominant driver for uptake (reported by 60.9% of naila users), followed by “deep understanding” and perceived efficiency gains. Non-use drivers bifurcated into disengagement (non-participation in exercises: 17.8%) and explicit preference for human instructor feedback (17.8%), despite high AI literacy rates.
TAM-Based User Experience Assessment
Students rated naila highly on all TAM-derived dimensions: Perceived Ease of Use (PEOU = 4.1/5), Perceived Usefulness (PU = 4.1/5), and Perceived Learning (PL = 4.0/5), where 4 corresponds to “agree” (Figure 5). However, perceived usefulness approached but did not surpass human-generated feedback (question PU-5), indicating nuanced boundaries in subjective replacement of instructor expertise.
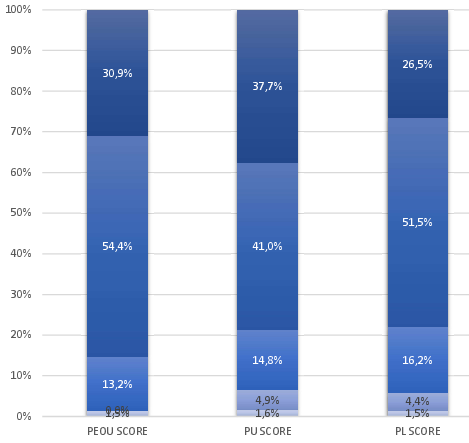

Figure 5: Aggregated TAM scores visualizing ease-of-use, usefulness, and perceived learning.
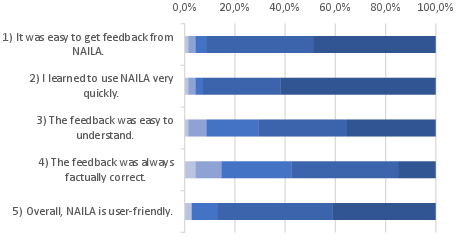
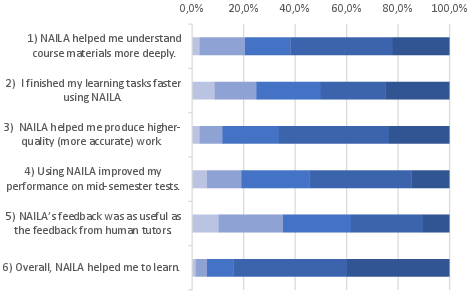
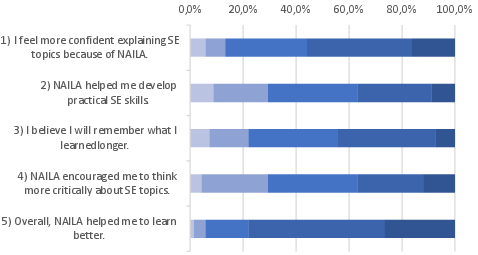
Figure 6: Likert distribution for Perceived Ease of Use (PEOU).
Engagement Patterns
Utilization patterns revealed strategic divergence: 44% used naila solely for one-shot (“confirmatory”) feedback (NUC), 6% exclusively used iterative (“remedial”) feedback (NUR), with the remainder employing both modalities. Histogram analysis of the NUC group indicated predominance of high first-attempt scores, suggesting substantive pre-existing mastery or effective self-regulation.
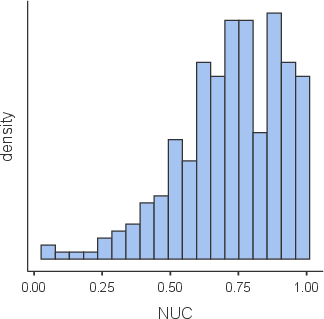
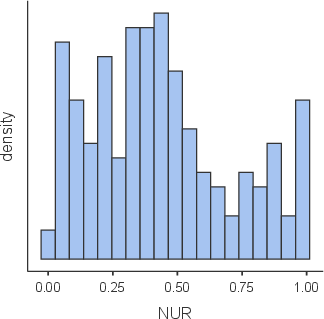
Figure 7: Usage pattern histograms for ‘confirmatory’ and ‘remedial’ interaction modes.
Statistical learning outcome analysis (n = 670) utilized multivariate linear regression, controlling for baseline ability (BA, assessed at semester start), written exercise completion, and face-to-face exercise participation. The mean final exam score centered at 70%, with no significant dependency on degree program (Kruskal-Wallis p=0.08299).
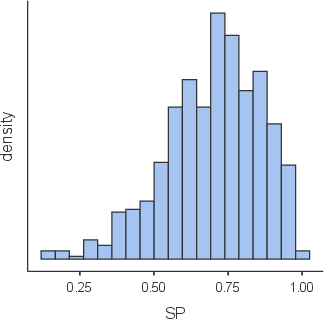
Figure 8: Histogram of student exam performance (N=670,SPˉ≈70%).
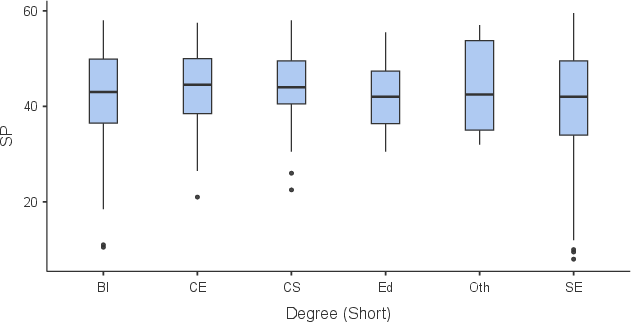
Figure 9: Exam performance boxplots by degree program (N=760).
The regression model revealed:
- Baseline Ability (β=6.98, p≪0.01) and Volume of Written Exercises (β=6.58, p≪0.01) were the two largest predictors of exam success.
- One-shot naila confirmation usage (NUC) was a positive, statistically significant predictor of higher final exam performance (β=3.59, N=1160).
- Iterative remedial usage (NUR) exhibited no significant impact (N=1161, N=1162).
- Physical exercise meeting attendance had only a marginal, non-significant effect.
Key Contradictory Finding: While positive engagement with AI feedback for mastery confirmation predicts performance, frequent remedial attempts as measured by NUR did not. This strongly suggests that LLM-driven iterative remediation practices may support surface learning behaviors (i.e., answer adjustment by trial-and-error) rather than robust conceptual internalization.
Interpretation, Limitations, and Forward Directions
This work provides nuanced evidence that maximizing the educational benefit of LLM-driven feedback is contingent on system alignment with self-regulatory learning mechanisms and careful mitigation of misuse as a mere “answer checker.” Survey-driven self-efficacy enhancements do not necessarily track with objective outcome gains—highlighting the need to integrate behavioral and outcome analyses.
Potential limitations include the voluntary, non-randomized usage paradigm (introducing selection bias) and reliance on self-reported engagement levels. The model did attempt to control for effort and engagement proxies, but unobserved confounders may persist.
Practical, Regulatory, and Pedagogical Implications
- AI-driven feedback systems like naila are operationally scalable and legally deployable in high-enrollment, multiprogram settings, provided that GDPR, copyright, and EU AI Act requirements are met via explicit consent, anonymization, and model prompt engineering.
- Pedagogical alignment of feedback must be shifted from a “summative grader” to a formative coaching paradigm, e.g., by integrating Socratic questioning or limiting the ability for rapid, consequence-free resubmission.
- Human-centric feedback still holds distinct perceived value, justifying continued hybrid approaches for those segments of the student population.
Conclusion
The naila system validates the technical and empirical viability of deploying LLM-generated autonomous feedback at scale in introductory SE education. Empirical findings highlight a statistically significant positive association between confirmatory use of AI feedback and academic performance, but identify critical limitations around remedial, iteration-driven engagement. These results underscore the necessity for feedback systems to promote deep, self-regulated learning rather than enabling algorithmically optimized “score hacking.” Future iterations should tune prompt strategies and conversational structure towards formative, strategic, and explainable support, advancing naila and similar systems to meaningfully augment human instruction without eroding educational integrity.

