- The paper shows that evaluator VLMs have pronounced insensitivity to valid perturbations, with failure rates exceeding 30% in some cases.
- The Focus benchmark leverages over 4,000 human-validated perturbations across I2T and T2I settings to assess model robustness.
- Pairwise comparison with axis-based prompting improves reliability, yet systematic blind spots remain in compositional and physical reasoning.
Uncovering Blind Spots in Evaluator Vision-LLMs: An Expert Analysis of "Seeing Isn't Believing" (2604.21523)
Introduction and Motivation
Evaluator Vision-LLMs (VLMs) are now a central mechanism for automated assessment across multimodal tasks including Visual Question Answering (VQA), image captioning, and text-to-image generation. Their roles extend from benchmarking generative model outputs to providing reward signals in reinforcement learning from human feedback (RLHF) pipelines. The reliability and failure modes of these evaluator models, however, have not been systematically characterized. This paper introduces Focus, a controlled meta-evaluation benchmark designed to probe evaluator VLM robustness, diagnostic sensitivity, and failure patterns via targeted perturbations in both image-to-text (I2T) and text-to-image (T2I) settings.
Figure 1: Focus is a meta-evaluation benchmark to evaluate robustness of Evaluator VLMs.
Benchmark Construction and Perturbation Taxonomy
Focus is built on a comprehensive, human-validated suite of over 4,000 perturbed instances encompassing 40 perturbation types. For I2T, perturbed textual outputs are generated (or edited) from gold answers via both automated and human-in-the-loop means; for T2I, input prompts are re-edited, and resulting images are validated by annotators. Perturbations are fine-grained, reflecting documented VLM failure axes:
- I2T: Visual grounding (entity/artifact substitutions, object hallucinations), semantic interpretation (cultural misalignment, contextual reduction), visual reasoning (numerical errors, procedural swaps), and long-form generation conflicts.
- T2I: Visual fidelity (object/attribute swaps, spatial/scale errors), scene coherence disruptions, physical implausibility (violations of causality, physics, transformations), and text rendering corruption.
Each instance admits both valid degradations (should change evaluation) and score-invariant edits (should be robust), enabling analysis of evaluator discriminatory power and over-sensitivity.
Experimental Paradigms and Evaluator Architectures
The evaluation covers four leading VLMs: Gemini-3.1-Pro, GPT-5.4, Claude-Opus-4.6, and Qwen3.5-397B-A17B, all tested in high-determinism settings. Three evaluation paradigms are included:
- Single-answer Scoring: The standard approach—score a single candidate relative to input.
- Pairwise Comparison: Select the superior output from gold/perturbed pairs.
- Reference-guided Scoring: Assign a score to a candidate in explicit comparison with a reference output.
Within each paradigm, varied prompting strategies (vanilla, rubric/rules, axis-based, and combined) are instantiated, mirroring best practice in recent literature. For axis-based strategies, scoring and/or verdicts are per-dimension (e.g., relevance, visual grounding for I2T; prompt adherence, alignment, image quality for T2I).
Main Findings: Systematic Blind Spots and Reliability Dissections
Paradigm and Strategy Reliability
Evaluator VLMs exhibit pronounced unreliability on detection of valid perturbations. Failure rates often exceed 30%—with certain T2I perturbations being missed >50% of the time, even by top-tier models. Pairwise comparison paradigms consistently outperform single-answer scoring and, contrary to text-only trends, also generally outperform reference-guided scoring on both I2T and T2I (see Figure 2).
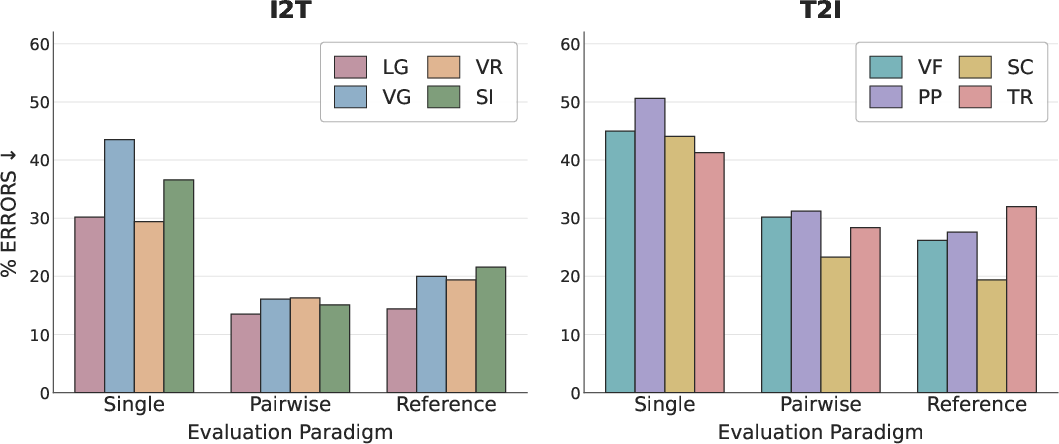
Figure 2: Comparison across evaluator paradigms and perturbation categories. Lower is better; pairwise is most reliable.
Axis-based prompting further boosts robustness within each paradigm, confirming that fine-grained evaluation dimensions help mitigate—but do not eliminate—blind spots.
Substantial performance gaps persist between models. Gemini-3.1-Pro achieves the lowest perturbation-insensitivity rates across paradigms; Claude-Opus frequently underperforms despite strong leaderboard standing on other tasks. This demonstrates that aggregate model strength is not predictive of evaluator sensitivity to subtle or compositional errors.
Perturbation Category Hardness
Certain perturbation categories are chronically problematic. For I2T, evaluators are most vulnerable to visual grounding and semantic interpretation modifications. For T2I, physical plausibility violations (e.g., impossible shadows, causal errors) and text rendering corruptions are least likely to be caught (see Figure 3).
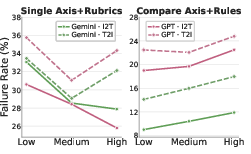
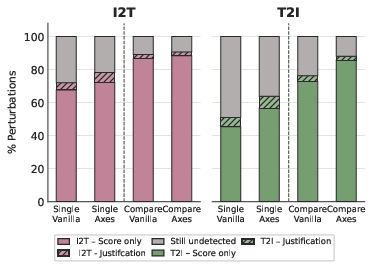
Figure 3: Effect of reasoning budget on evaluator performance across paradigms and error types.
Reasoning Budget, Reference Style, and Justification Gaps
- Increasing model "reasoning budget" has a non-monotonic effect; maximal reasoning often degrades sensitivity, particularly in T2I comparative evaluations. This suggests overthinking or drift can be detrimental (Figure 3 above).
- Reference style affects reference-guided scoring: textual evaluators exhibit increased brittleness (favoring superficial similarity), while image-based evaluators may be aided by visual diversity.
- Model-generated justifications seldom correct for missed detections in final scores/verdicts—in single-answer scenarios, many errors are flagged in explanations yet ignored in scalar outputs.
Robustness to Score-Invariant Edits
On score-invariant perturbations, single-answer scoring is most robust. Pairwise comparison often inappropriately prefers one alternative over the other, even when both should be equally accepted—revealing a susceptibility to forced choice bias.
Practical Recommendations
The analysis supports several clear recommendations for the use of VLMs as evaluators:
- Favor pairwise comparison with axis-based or combined strategies for highest reliability.
- Do not extrapolate from general-purpose model rankings to evaluator efficacy—validate sensitivity directly.
- Avoid maximizing model reasoning depth indiscriminately.
- For tasks involving fine-grained visual reasoning, compositionality, or physical world knowledge, human review or domain-specific diagnostics should augment VLM-based pipelines.
- Use caution when leveraging VLMs as reward models for RLHF or architecture search—blind spot propagation risks reinforcing non-robust behaviors in downstream generative models.
Implications and Future Directions
The demonstrated insensitivity of current VLM evaluators to subtle, compositional, or physical errors challenges their adoption as sole automated judges, particularly where accurate reward or comparative signals are critical. As research pivots toward increasingly autonomous and scalable multimodal system evaluation, the community must address these limitations. Promising directions include adversarially-trained evaluators, multi-agent debate/meta-evaluation protocols, and hybrid human-in-the-loop solutions.
The Focus benchmark and methodology provide a foundation for such work, and should be routinely employed in evaluator benchmarking and development. Future research should probe deeper into model internal interpretability—why are errors sometimes flagged in explanations yet ignored in decisions—and harness targeted test sets for RLHF reward robustness.
Conclusion
This study delivers a rigorous, fine-grained dissection of evaluator VLM blind spots via the Focus meta-benchmark. Evaluator VLMs are frequently unreliable, often failing core error sensitivity thresholds across both image-to-text and text-to-image domains. Pairwise comparison with structured prompting is most robust, but substantial gaps and systematic errors persist, especially in categories requiring compositional reasoning or real-world grounding. Caution and hybrid validation strategies remain necessary for credible evaluation and alignment of modern multimodal generative models (2604.21523).