- The paper re-evaluates LoRA mechanisms by integrating classical signal processing principles to enhance parameter-efficient fine-tuning for large language models.
- It introduces advanced adapter architectures, including SVD-based, tensorized, and rank-augmented designs, to boost the expressiveness of fine-tuning updates.
- The study demonstrates that symmetry-aware optimization and specialized initialization methods significantly accelerate convergence while addressing quantization and safety challenges.
Low-Rank Adaptation Redux for Large Models: Technical Assessment
Introduction and Signal Processing Foundation
Low-Rank Adaptation (LoRA) and its family of parameter-efficient fine-tuning (PEFT) methods have become the standard for adapting LLMs and foundation models. The paper "Low-Rank Adaptation Redux for Large Models" (2604.21905) systematically revisits the theoretical mechanisms, architectural designs, and optimization strategies underpinning LoRA, positioning them within the framework of classical signal processing (SP), low-rank matrix/tensor modeling, and inverse problems. The central motivation is to bring mathematical structure and analytic rigor from SP to the empirical advances in PEFT, and conversely, to inform SP with large-scale, non-convex regimes characteristic of modern DL.
Classical and Modern Low-Rank Modeling
The SP perspective treats LoRA-style fine-tuning as a modern instance of classical low-rank matrix sensing and subspace estimation. Established approaches such as Principal Component Analysis (PCA), nuclear-norm minimization, and non-convex factor modeling (Burer-Monteiro) directly inform how LoRA parameterizations achieve drastic reductions in computational and memory costs. The canonical LoRA update replaces a full parameter matrix by the sum of pre-trained weights and a trainable low-rank increment:
Xl,Ylminf({Wl+XlYl⊤}l;Dft)
This factorization enables adapting billion-parameter models by learning only ∼1–2% additional parameters per layer.
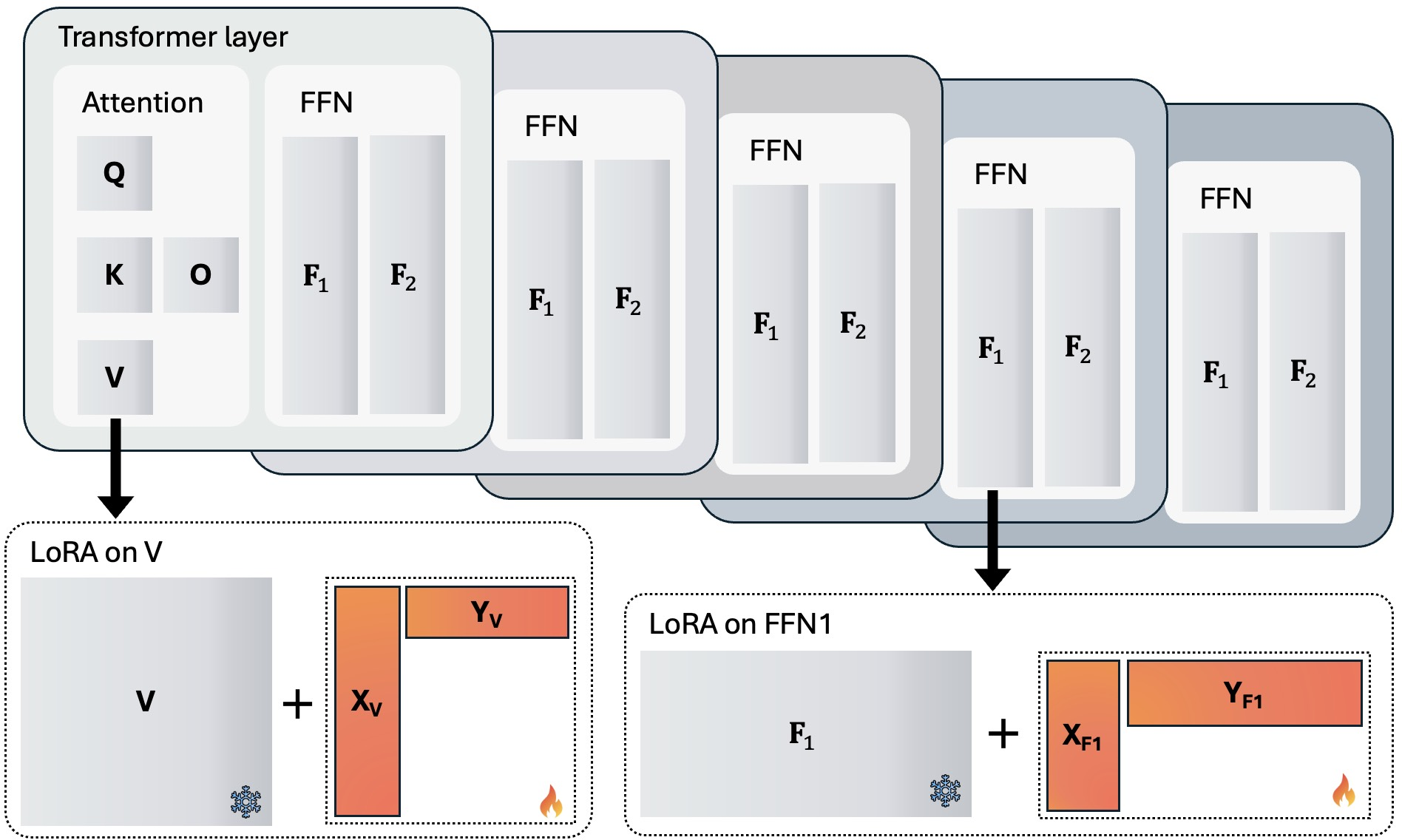
Figure 1: LoRA fine-tuning augments frozen GPT-3 linear weights (grey) with small trainable LoRA matrices (orange), yielding significant parameter savings.
The link between LoRA and classical matrix/tensor factorization is not merely formal but practically relevant: LoRA’s BM factorization inherits many of the expressiveness and optimization properties of these well-studied low-rank models.
Architectural Advances: From BM to High-Rank and Tensorized LoRA
Adaptive and SVD-based Parameterizations
The survey provides an extensive taxonomy of LoRA variants along architectural complexity and expressiveness. SVD-based adapters (e.g., AdaLoRA, PoLAR, SteLLA) increase parameter efficiency by introducing orthogonality and explicit singular value modulation, facilitating layer-wise or dynamic rank allocation. Notably, enforcing or relaxing orthogonality allows explicit control over subspace directions, promoting optimal use of rank budget and supporting pruning/growth policies.
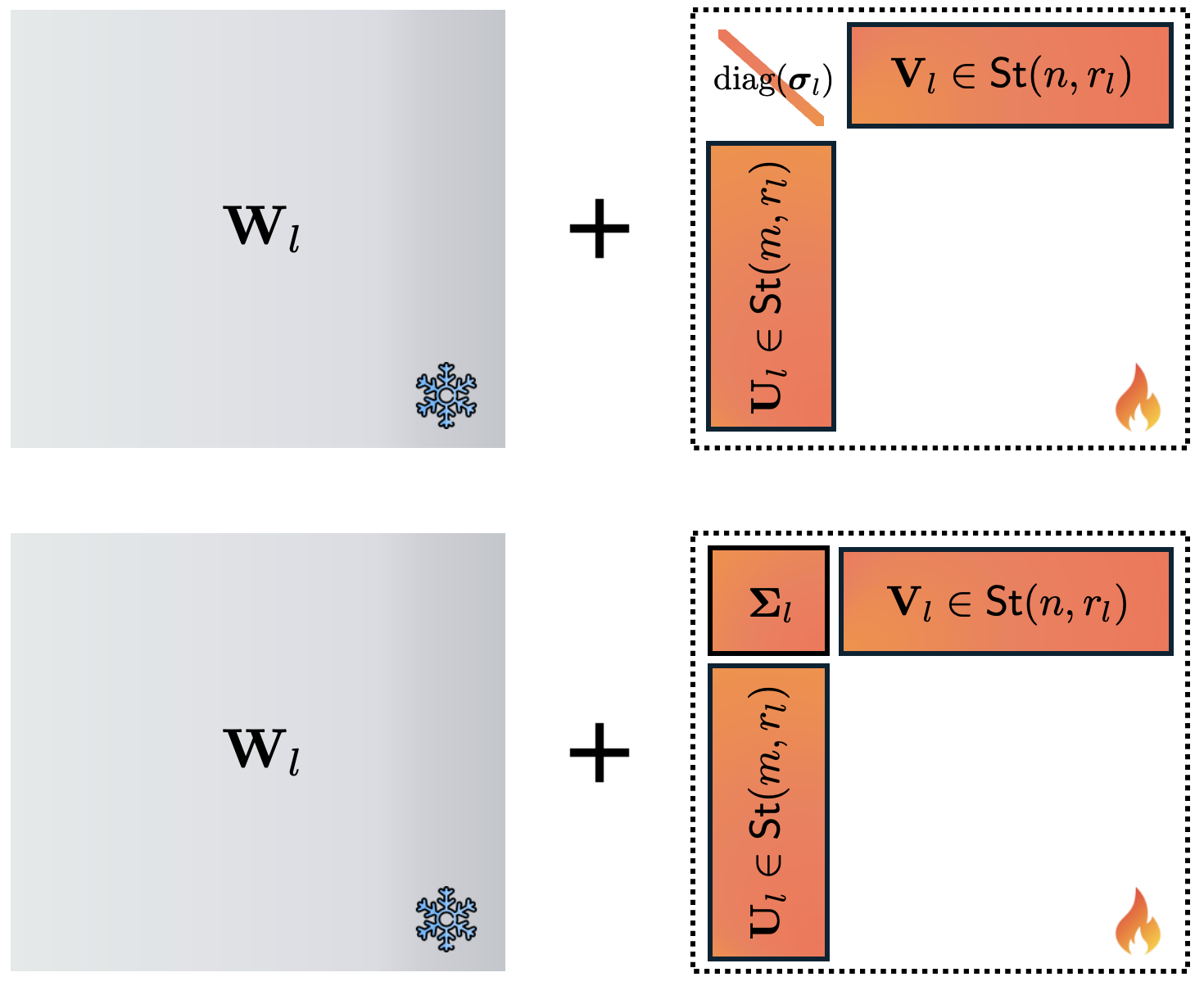
Figure 2: SVD-based factorization (AdaLoRA, PoLAR) introduces additional structure via orthogonal factors and singular value matrices.
Empirical findings indicate standard BM LoRA often utilizes only a rank-one or low-rank fraction of allotted expressivity, while SVD-based variants push up the "stable rank" (effective dimensionality), yielding better data utilization.
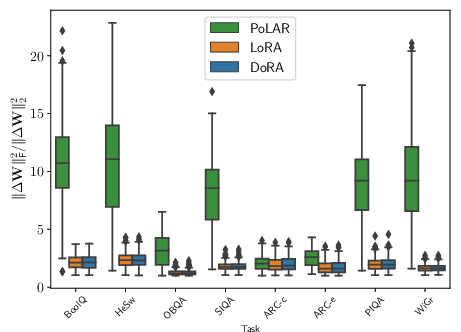
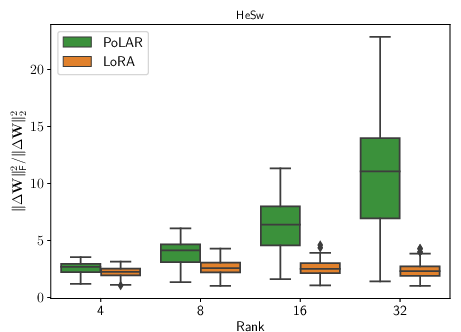
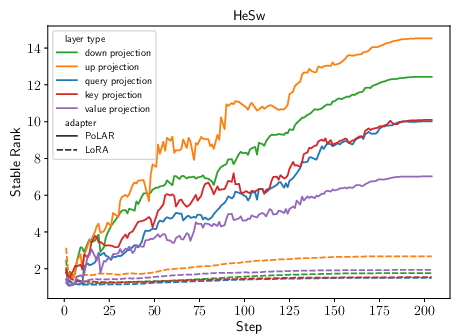
Figure 3: (a) PoLAR parameterization leads to higher effective stable rank versus BM. (b-c) Fine-tuning LLaMA2-7B on HellaSwag demonstrates the dynamics of stable vs. algebraic rank.
Rank-Augmented and Structured Adapters
To transcend the expressiveness limitations of low-rank adapters, Hadamard (Hadamard product LoRA, FedPara), Kronecker (KronA), and sparse-plus-low-rank (RoSA) parameterizations are developed. These schemes can represent higher-rank increments with similar or marginally increased parameter count, benefiting from the submultiplicative and multiplicative properties of the Hadamard and Kronecker products.
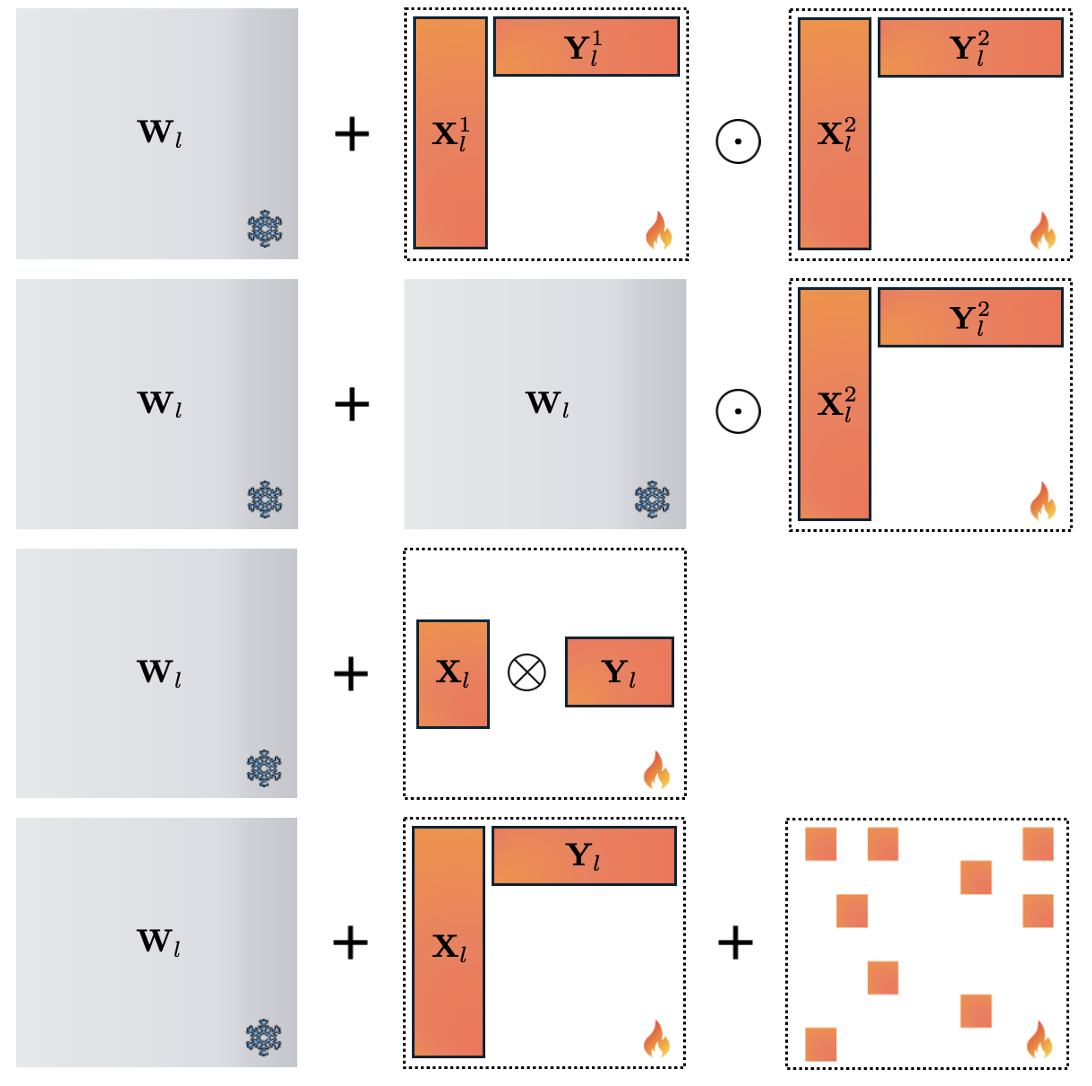
Figure 4: FedPara, HiRA, KronA, and RoSA demonstrate different parameterization strategies that increase expressive capacity beyond standard LoRA.
However, these more expressive designs introduce additional symmetries and non-convexities, complicating optimization and often requiring specialized solvers.
Cross-layer and Tensorized LoRA
Recent empirical studies reveal significant correlation and redundancy across weights of adjacent layers in LLMs (see Llama 3.1-8B-Instruct analysis).
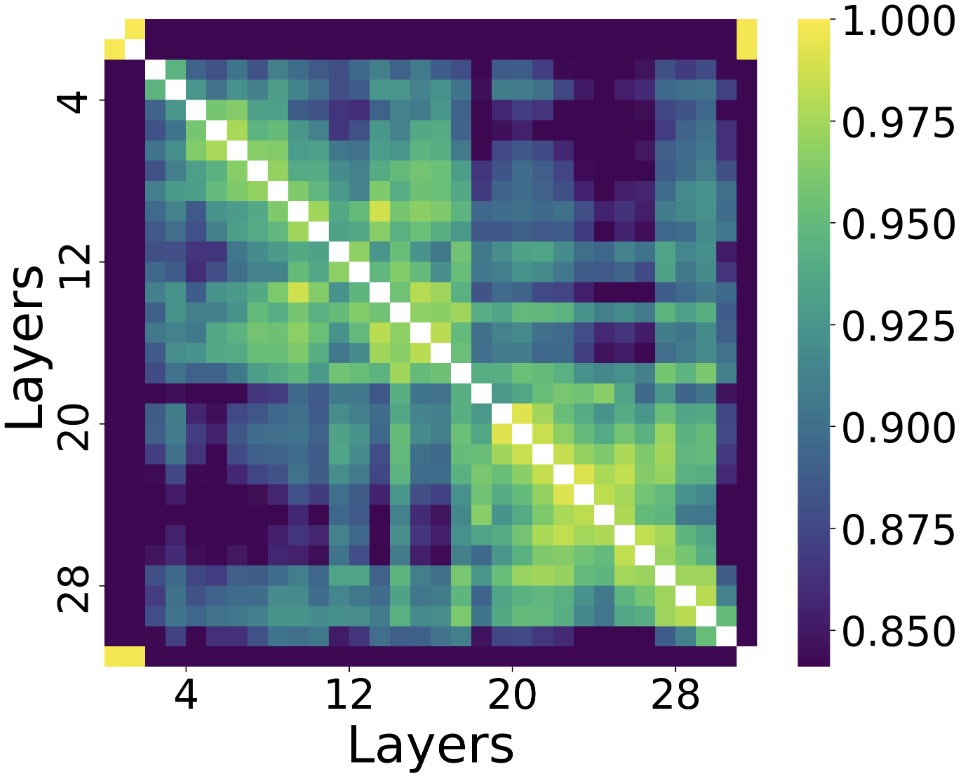
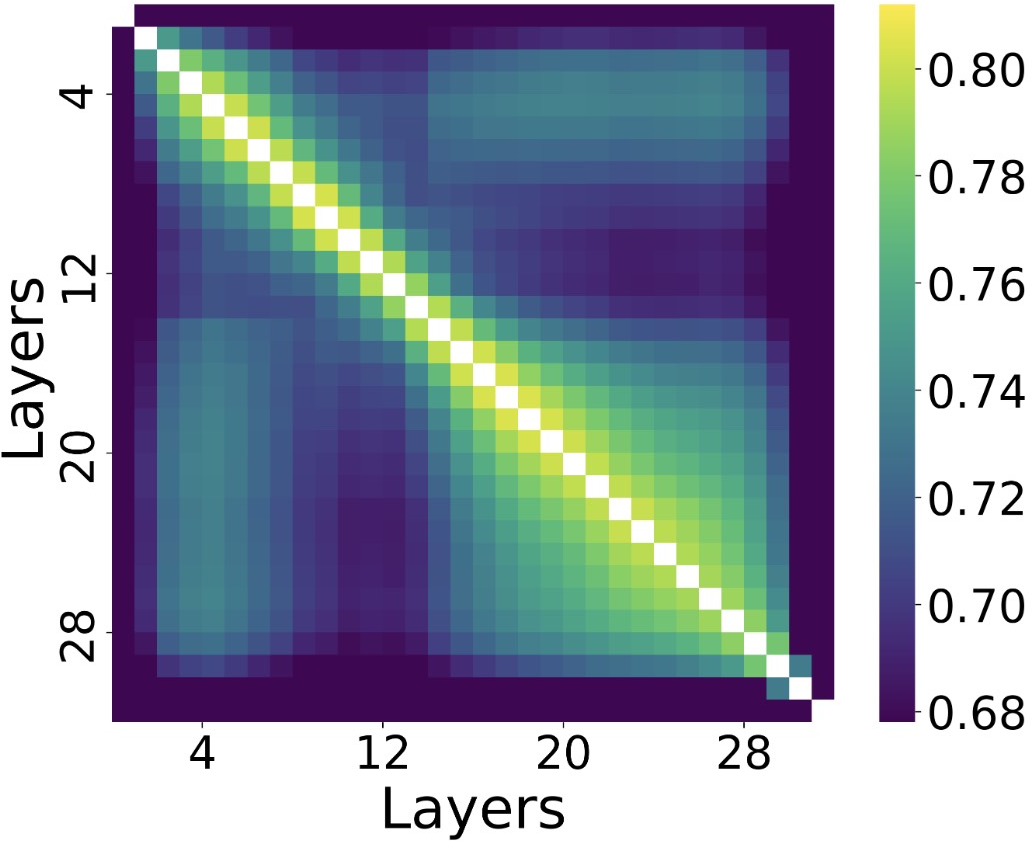
Figure 5: Strong inter-layer correlations revealed via CKA call for exploiting cross-layer parameter sharing and tensorization.
Tensorized adapters (e.g., CP, Tucker, TT) treat the stack of updates as a higher-order tensor, factorizing across both layer and intra-layer structure. This approach leads to even more compact representations and parameter-sharing schemes.
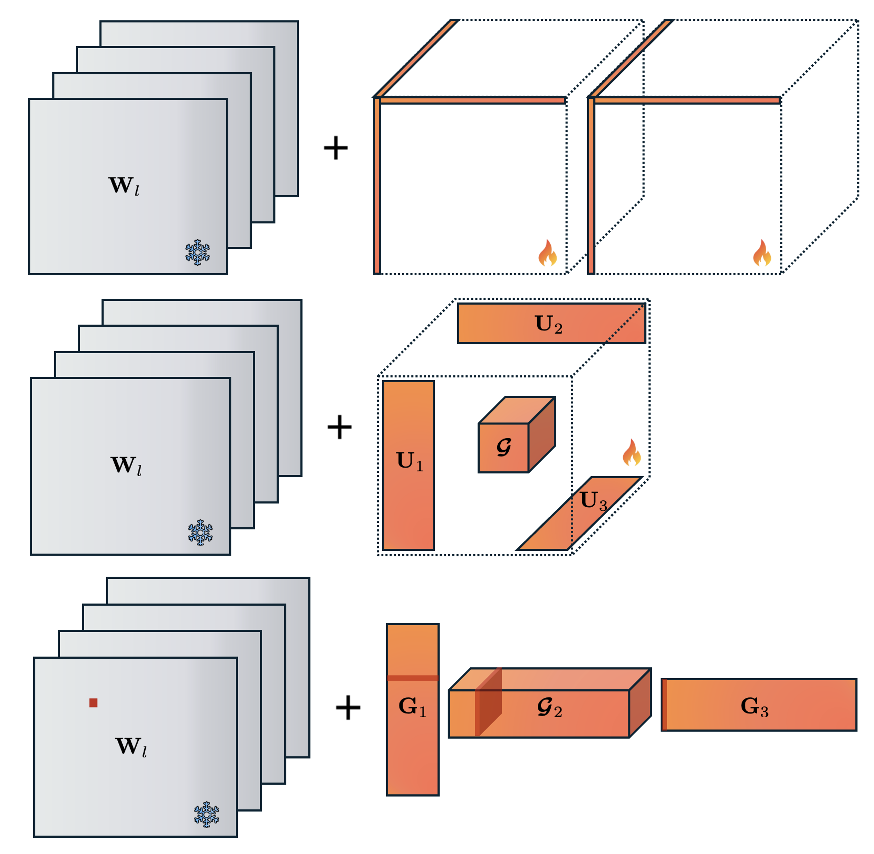
Figure 6: Tensorized LoRA (LoRTA, Fact, LoRETTA) compresses multiple adapter matrices into structured factors, spanning layers and projections.
Efficient Optimization in the Presence of Symmetries
A key insight of the paper is that LoRA optimization landscapes, induced by bilinear BM factorization, are globally non-convex and non-smooth but possess advantageous geometric properties:
- All local minima correspond to global minima (in the idealized setting)
- Rich symmetry/gauge invariance: many parameterizations of (X,Y) yield the same adapter XY⊤
- Optimization is sensitive to initialization, symmetry navigation, and implementation of constraints
Standard gradient descent is often suboptimal in such landscapes. The survey details how manifold optimization, alternating solvers, and "gauge-invariant" Riemannian approaches (e.g., ScaledGD, RefLoRA, LoRA-Pro) can exploit LoRA structure for dramatically accelerated convergence, especially with Nystrom- or subspace-aligned initializations relative to naive random starts.
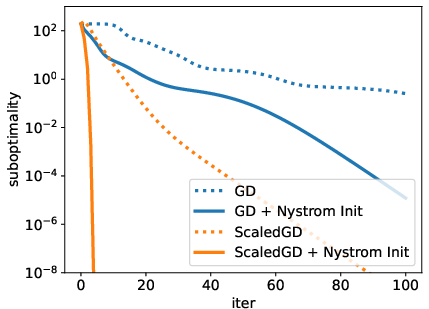
Figure 7: Initialization choice (random Gaussian vs. Nystrom) yields exponential difference in convergence rate on prototypical low-rank matrix factorization.
Recent methods (RefLoRA) achieve the steepest descent within the space of equivalent parameterizations by explicitly projecting out vertical (gauge) components, yielding stronger per-iteration progress.
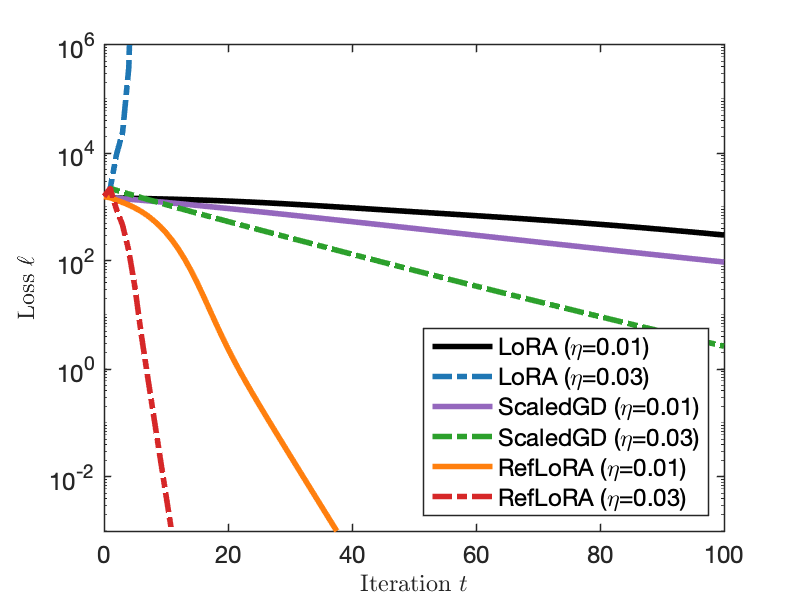
Figure 8: Gauge-invariant optimization (RefLoRA) improves per-iteration convergence compared to standard LoRA or ScaledGD.
Beyond Standard Fine-Tuning: Quantization, RL, and Serving
LoRA extensions now pervade the entire foundation-model pipeline, including quantization-aware adaptation (QLoRA, QA-LoRA) for single and multi-bit inference, merging with pre-training and sparse updates, and parameter sharing for efficient multi-domain/tenant serving.
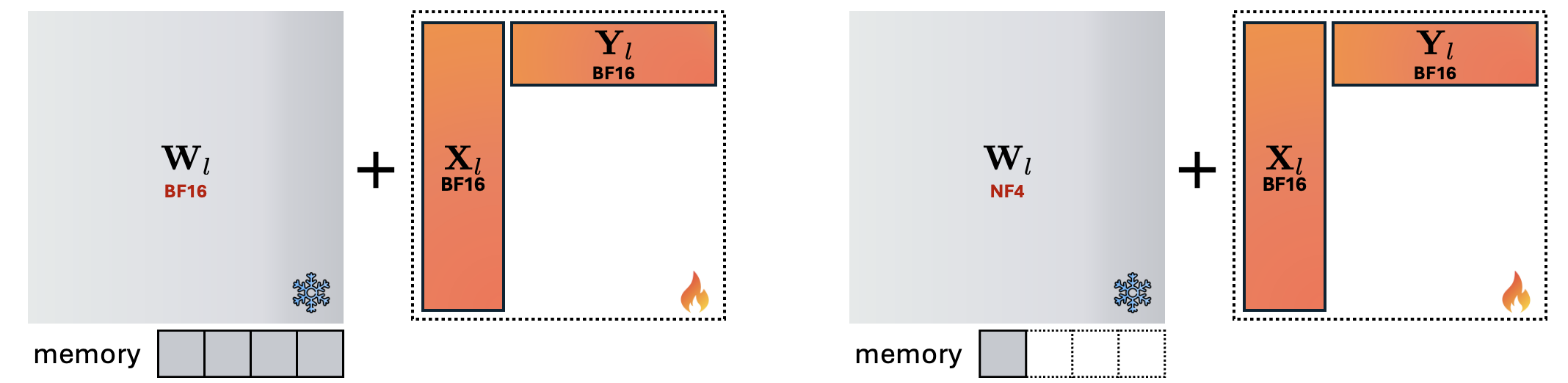
Figure 9: QLoRA extends LoRA to quantized backbone models, offering memory-efficient fine-tuning with minimal loss.
LoRA modules are also deployed for RL-based alignment and preference optimization. Notably, LoRA-based RLHF achieves performance on par with full-parameter training for LLMs, challenging claims that additional capacity is needed at this phase.
The combinatorics—linear, contrastive, and MoE-style—of multi-concept LoRA adapters are applied for semantic and stylistic composition, particularly in diffusion and multi-modal domains.

Figure 10: Layer-wise mixing of multiple concept LoRAs enables compositional diffusion and personalized text-to-image generation.
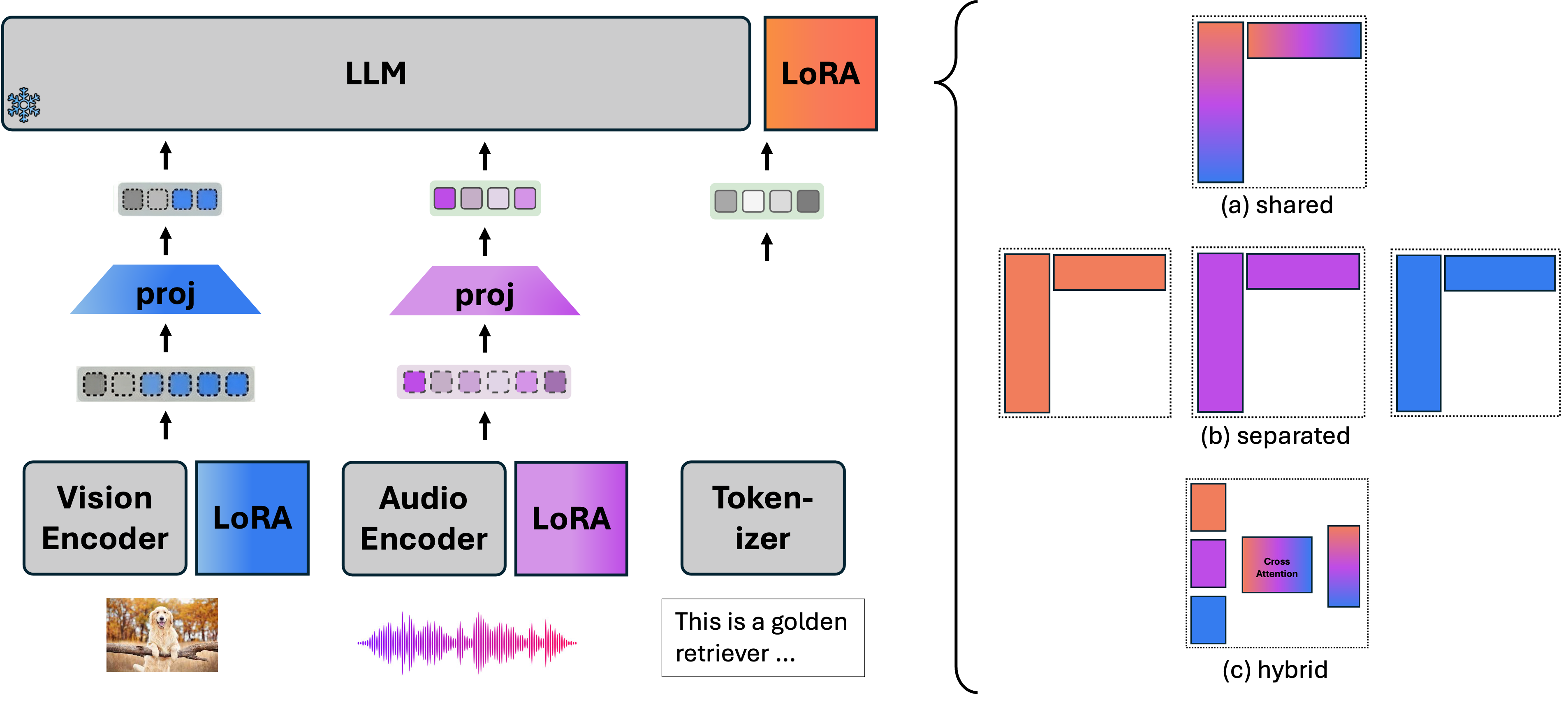
Figure 11: LoRA-based multi-modal fine-tuning enables efficient adaptation in audio-visual-text settings.
The paper synthesizes results on responsible fine-tuning. Bayesian and Laplacian extensions (Laplace-LoRA, BLoB, C-LoRA) and safety-aligned PEFT strategies (Safe LoRA, Salora) address uncertainty estimation and alignment integrity. Differential privacy–aware LoRA variants and architecture-level mitigations for privacy attacks are reviewed, highlighting that LoRA's structure does not guarantee inherent privacy, motivating DP-optimized adapters and noise-injection calibrated to LoRA symmetries.
Implications, Limitations, and Future Directions
- LoRA-style fine-tuning is justified as a modern realization of decades-old low-rank signal modeling. The convergence of modular DL and SP best practices suggests a unified analytic foundation for the next generation of LLM adaptation.
- Despite algorithmic and theoretical progress—especially in initialization and symmetry-aware optimization—many high-rank and tensorized LoRA schemes lack both practical toolchains and convergence theory. Optimization of adapters with additional symmetries (e.g., Kronecker, Hadamard, sparse support) is non-trivial.
- Statistical–computational tradeoffs for tensorized adapters and sparsity patterns are largely unexplored. Empirical results indicate meaningful efficiency gains, but the possibility of implicit underfitting/overfitting or non-convex statistical barriers remains.
- As LoRA modularity increases, so does the risk of attack surfaces relevant for privacy and safety; ongoing work is required to rigorously bound the impact of composition and merging on alignment robustness.
- The cross-fertilization between SP and DL is nontrivial and bidirectional: advances in LoRA/PEFT already inform new algorithms for classical matrix/tensor-sensing problems. Conversely, future improvements in PEFT will likely require importing even more advanced optimization and structure-exploiting schemes from SP.
Conclusion
"Low-Rank Adaptation Redux for Large Models" (2604.21905) delivers an expert-level synthesis of the mathematical and empirical literature on LoRA and PEFT for LLMs, grounding contemporary practice in a rigorous SP framework. The work details how LoRA owes its effectiveness to the interplay of classic low-rank model properties, adapter design, and symmetry-aware optimization. It also enumerates a range of promising directions, from tensorized and hybrid-adapter architectures to cross-modal, privacy-safe, and composition-aware fine-tuning. The thorough treatment positions PEFT as both a driver of accessible AI and a source of open theoretical challenges at the frontier of scalable deep learning and signal processing.

