- The paper introduces a systematic empirical analysis of LoRA placement in hybrid models, demonstrating that attention-only adaptation outperforms full-model tuning with significantly fewer parameters.
- It finds that the adaptation impact on the recurrent backbone is topology-dependent, with sequential hybrids suffering performance drops while parallel hybrids benefit.
- The study highlights that attention-only LoRA minimizes catastrophic forgetting and achieves notable efficiency gains in domain adaptation across tasks.
Component-Type LoRA Placement in Hybrid LLMs
Introduction
The paper "Where Should LoRA Go? Component-Type Placement in Hybrid LLMs" (2604.22127) introduces a systematic empirical analysis of LoRA (Low-Rank Adaptation) placement strategies across distinct architectural component types in hybrid LLMs. Rather than adhering to default Transformer-centric PEFT conventions—where LoRA adapters typically target attention projections—the authors examine whether the functionally distinct modules within hybrid models (e.g., attention, recurrent/state-space modules, MLPs) require differentiated adaptation protocols. They focus on two representative hybrid architectures: the sequential Qwen3.5-0.8B (GatedDeltaNet backbone interleaved with softmax attention) and the parallel Falcon-H1-0.5B (Mamba-2 SSM and attention in parallel), assessing domain adaptation dynamics and transfer asymmetries under various LoRA schema.
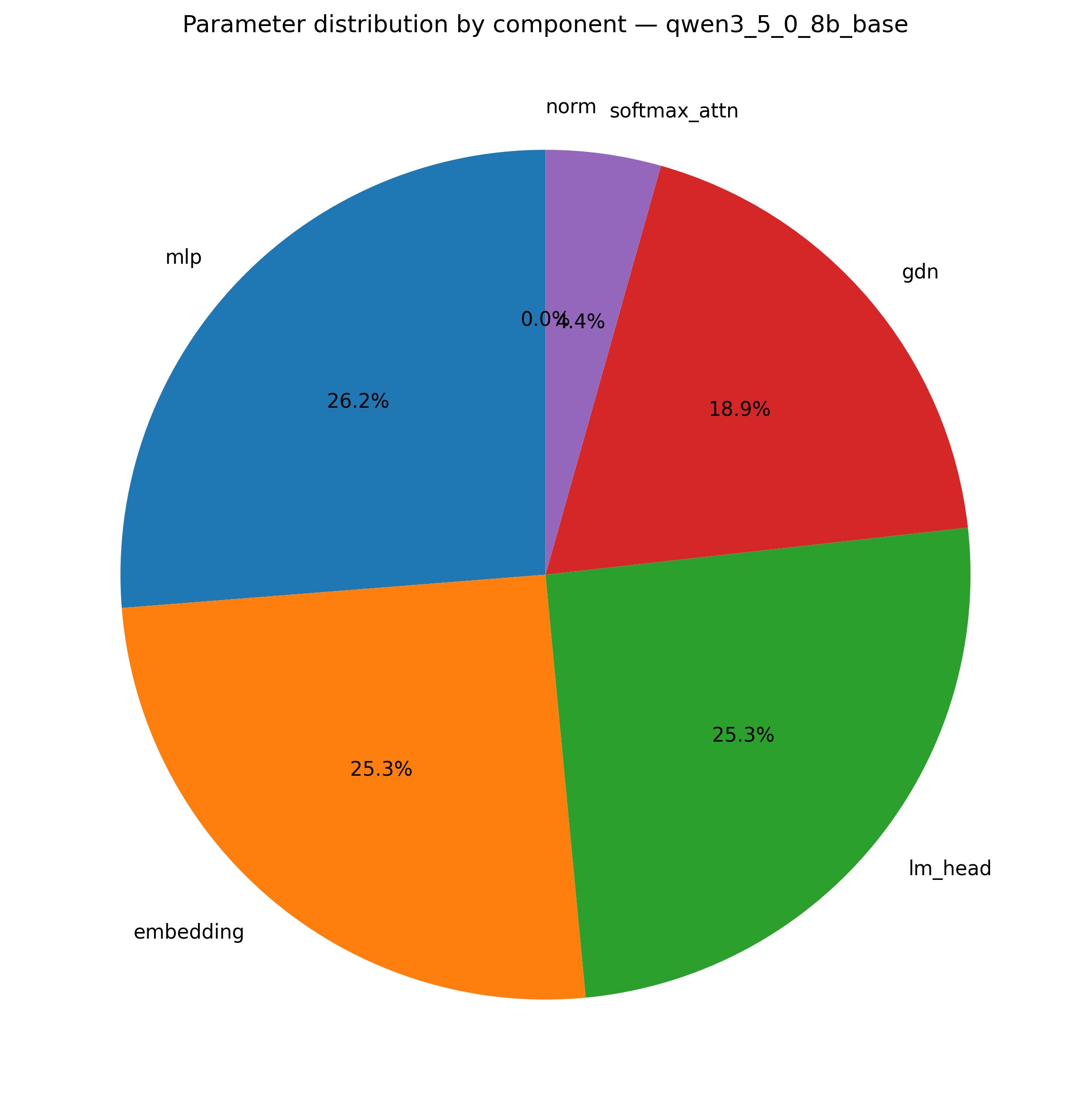
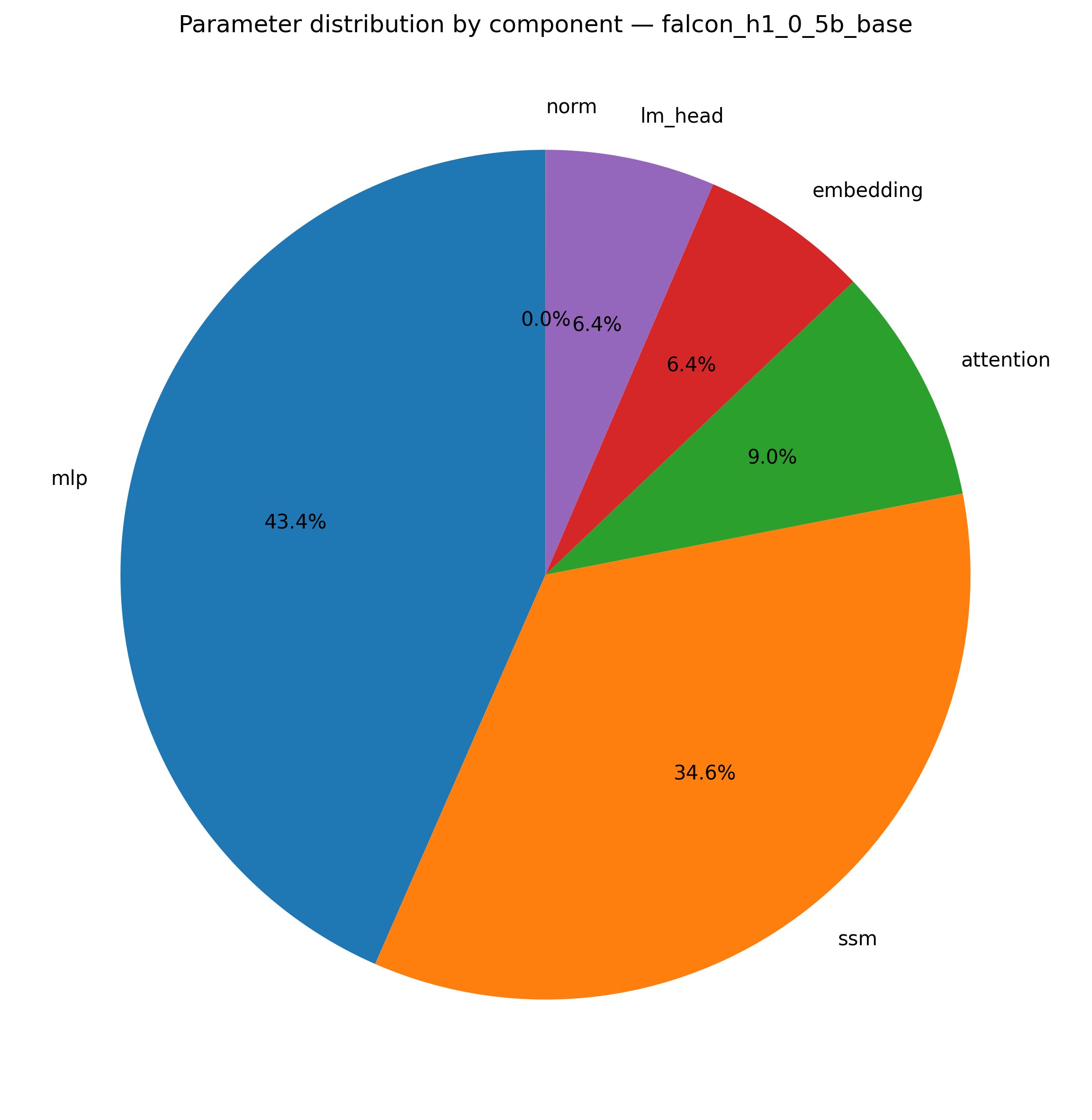
Figure 1: Parameter breakdown for Qwen3.5-0.8B, highlighting the dominance of recurrent and MLP over attention.
Experimental Design
The study isolates and combines LoRA placement across attention, recurrent, and MLP components. Six LoRA placement conditions are defined per architecture, and fine-tuning is conducted on three distinct domains: GSM8K (grade-school math), CodeAlpaca (code generation), and UltraChat (general instruction). For each domain, the resulting model variants are evaluated on MMLU, GSM8K, ARC-Challenge, HellaSwag, and HumanEval. All models are trained with consistent hyperparameters (LoRA rank r=16, fixed learning rates, identical hardware) to ensure meaningful comparisons. The evaluation explicitly addresses not only in-domain performance but also cross-task transfer and catastrophic forgetting.
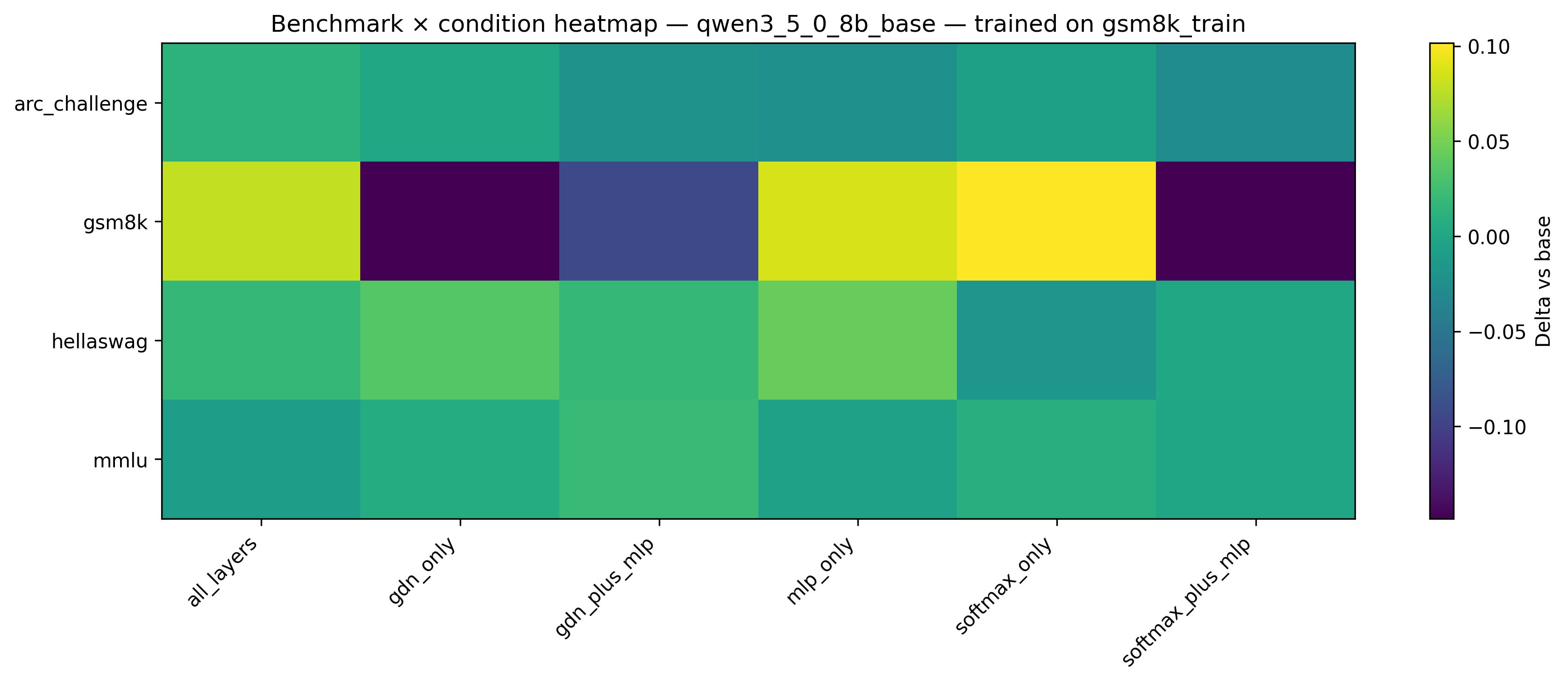
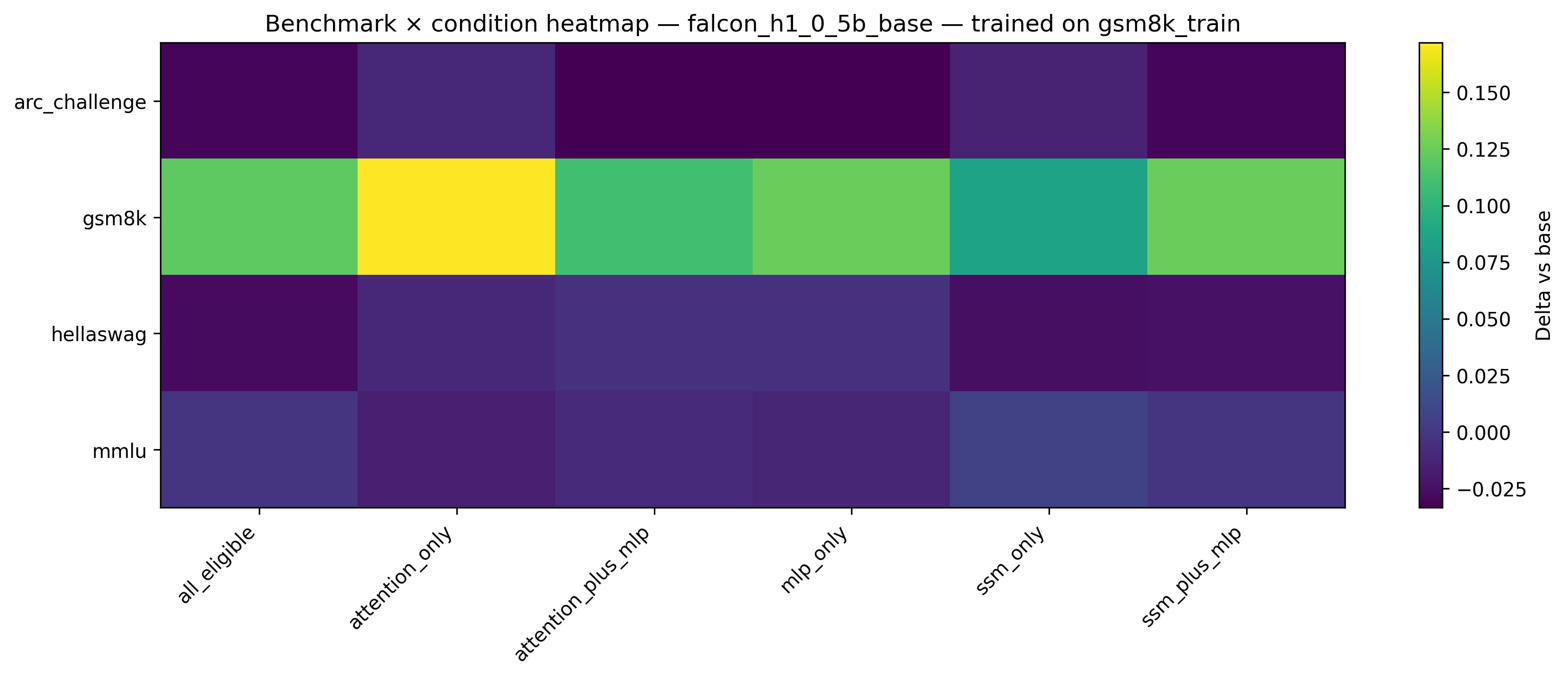
Figure 2: GSM8K accuracy heatmap for Qwen3.5-0.8B under various LoRA placement conditions.
Key Findings
Attention as an Adaptation Hotspot
A core and statistically robust result is that, across both sequential and parallel hybrid architectures, LoRA adapters applied solely to the attention pathway match or exceed the performance of full-model adaptation despite utilizing only 5–10× fewer trainable parameters. For Qwen3.5-0.8B, the softmax-attention-only LoRA attains a +10.2 target-domain improvement (GSM8K), outperforming all-layers adaptation by a substantial margin. For Falcon-H1-0.5B, attention-only LoRA yields an even more pronounced enhancement (+17.2 on GSM8K).
Topology-Dependent Adaptation Asymmetry
The response to LoRA placement on the recurrent backbone diverges fundamentally according to model topology. For Qwen3.5-0.8B (sequential), LoRA on GatedDeltaNet is strongly destructive (–14.8 GSM8K) whereas for Falcon-H1-0.5B (parallel), LoRA on the SSM backbone is constructive (+8.6). This finding underscores that the interconnection pattern of recurrent and attention modules determines their adaptation fragility or robustness.
Cross-Task Transfer and Forgetting
Cross-domain evaluation reveals an additional pronounced asymmetry. Sequential hybrids (Qwen3.5-0.8B) are highly susceptible to catastrophic forgetting under LoRA adaptation—UltraChat training results in up to −16.0 GSM8K accuracy loss. Conversely, parallel hybrids (Falcon-H1-0.5B) exhibit positive transfer, observing accuracy gains on untrained tasks after instruction tuning. Notably, attention-only LoRA placement offers the best robustness across cross-task transfer scenarios, consistently minimizing forgetting.
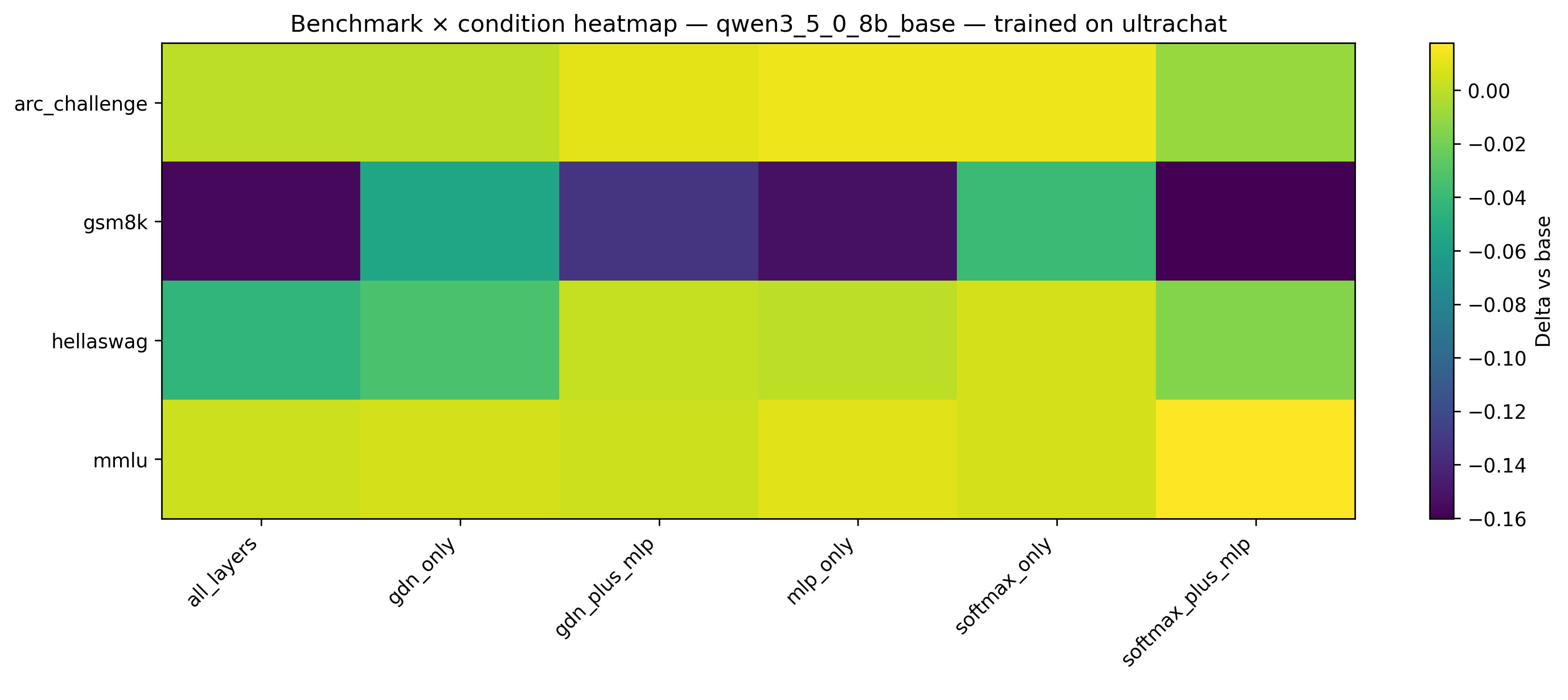
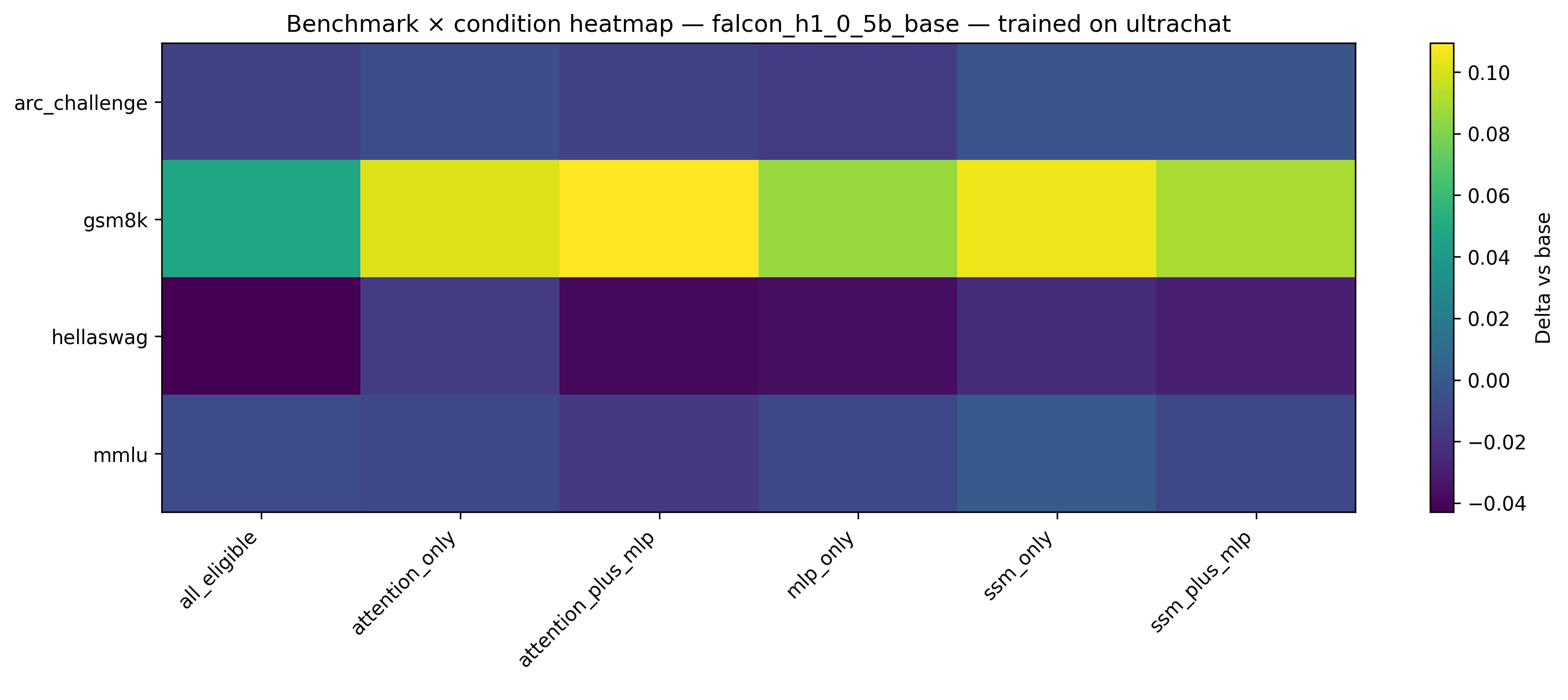
Figure 3: Cross-task accuracy impact heatmap after UltraChat training for Qwen3.5-0.8B, indicating severe catastrophic forgetting on GSM8K.
Analysis and Theoretical Implications
The observed effectiveness of attention-only adaptation, despite attention representing a parameter minority (4.4–6.4% of model parameters), aligns with the functional specialization hypothesis: the recurrent backbone encodes the core sequence dynamics and is finely optimized (and thus fragile to perturbation), whereas attention modules perform task-adaptable refinement. This rigidity/plasticity dichotomy is substantiated by prior functional ablation evidence showing that loss of recurrent modules produces orders-of-magnitude larger degradation than loss of attention (Borobia et al., 23 Mar 2026).
The destructive effect of simultaneous LoRA on attention and MLP in sequential hybrids (e.g., a collapse in GSM8K performance for Qwen3.5-0.8B) suggests optimization conflicts may emerge when both adaptation pathways are modified without backbone plasticity. The parallel hybrid’s independence of branches affords it resilience to such interference.
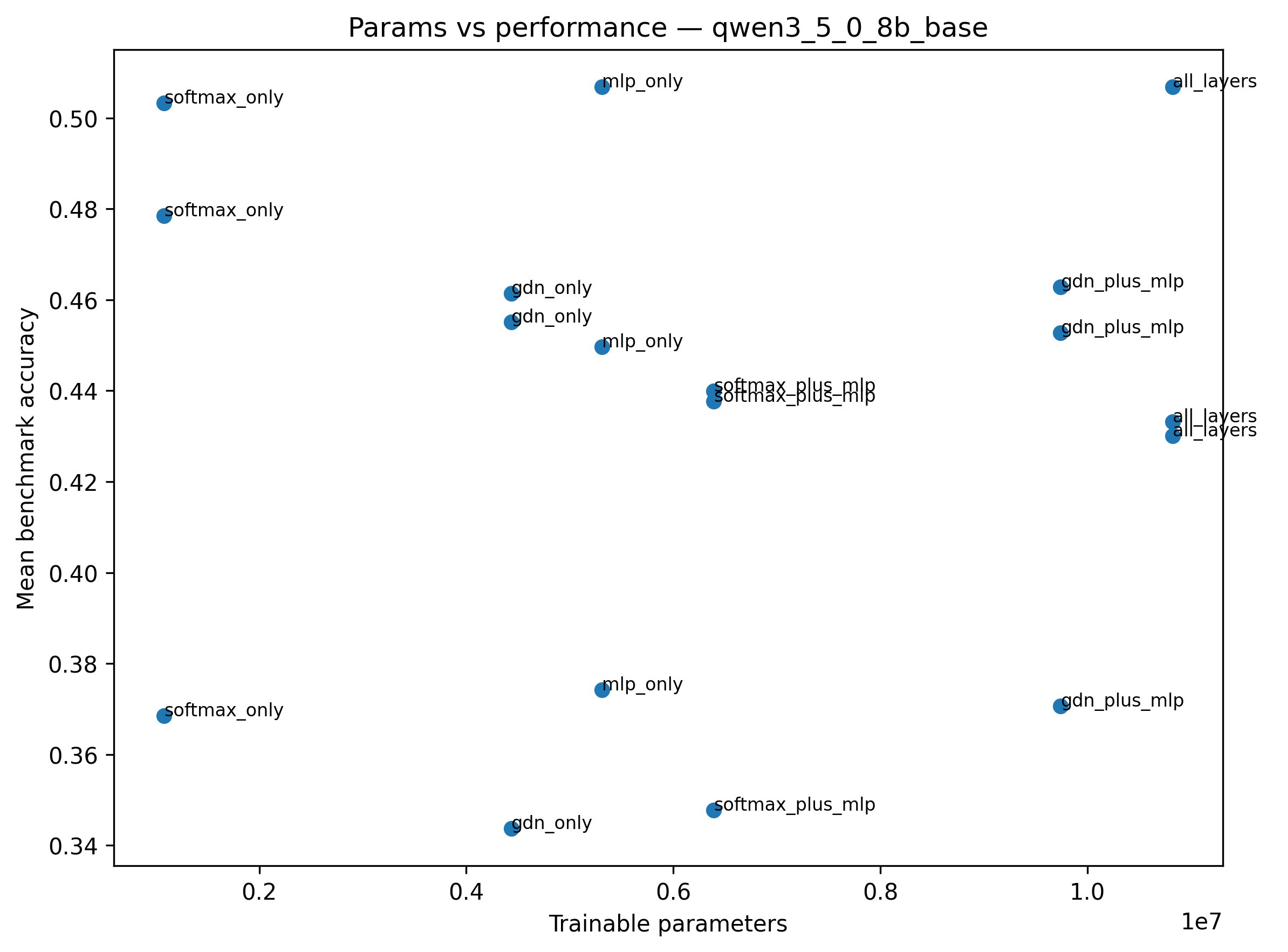
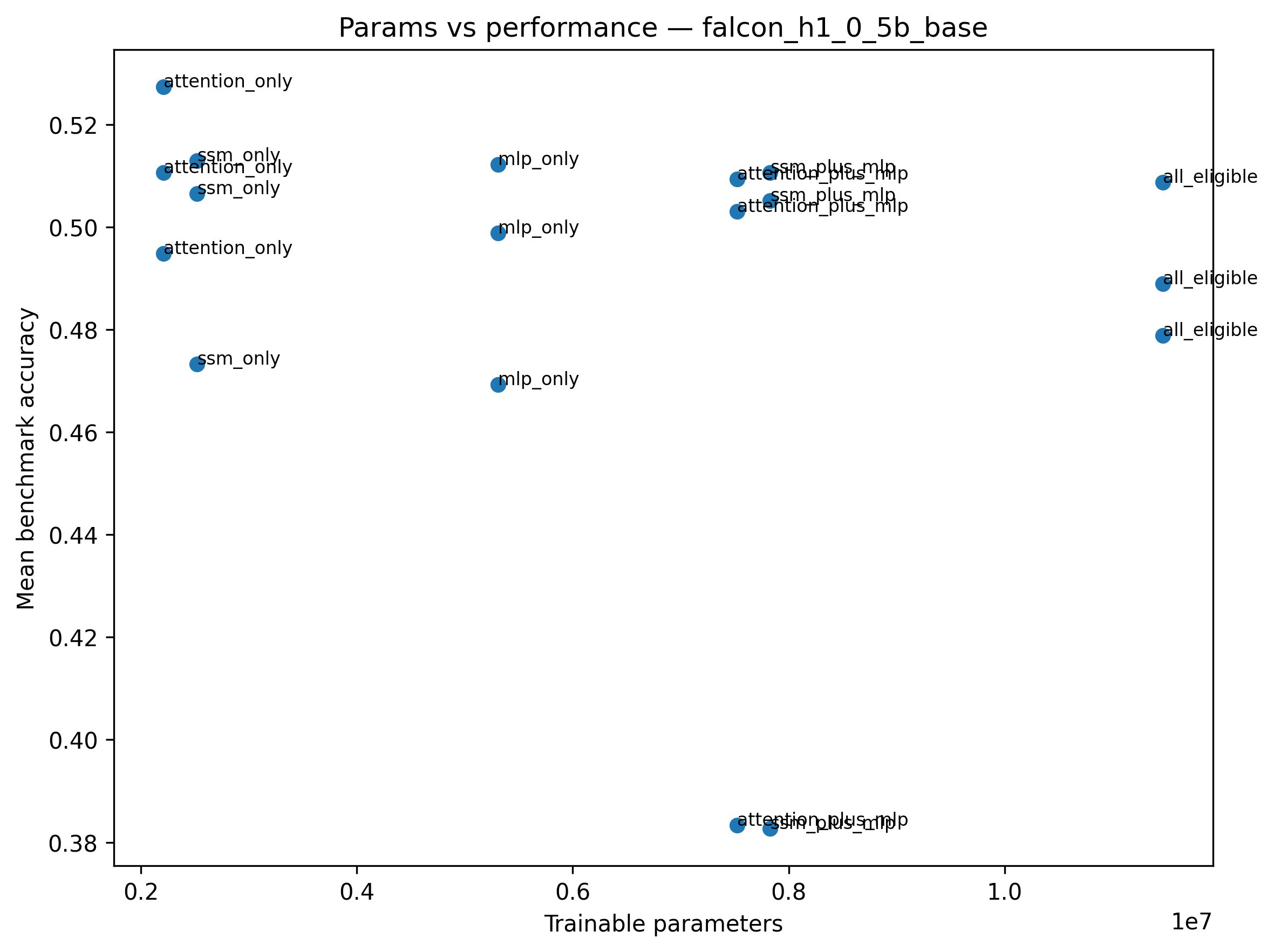
Figure 4: Pareto efficiency plot for Qwen3.5-0.8B, with attention-only LoRA on the dominant frontier (max accuracy per parameter).
Practical Recommendations
The results yield clear actionable guidelines:
- For sequential hybrids, restrict LoRA placement to attention modules; avoid the recurrent backbone.
- For parallel hybrids, attention-only LoRA is both maximally efficient and robust, but backbone adaptation is also safe.
- For all hybrids, attention-only LoRA provides minimal-parameter adaptation with low risk of catastrophic forgetting.
- Practitioners should prefer parallel hybrid architectures when substantial domain adaptation or cross-task robustness is required.
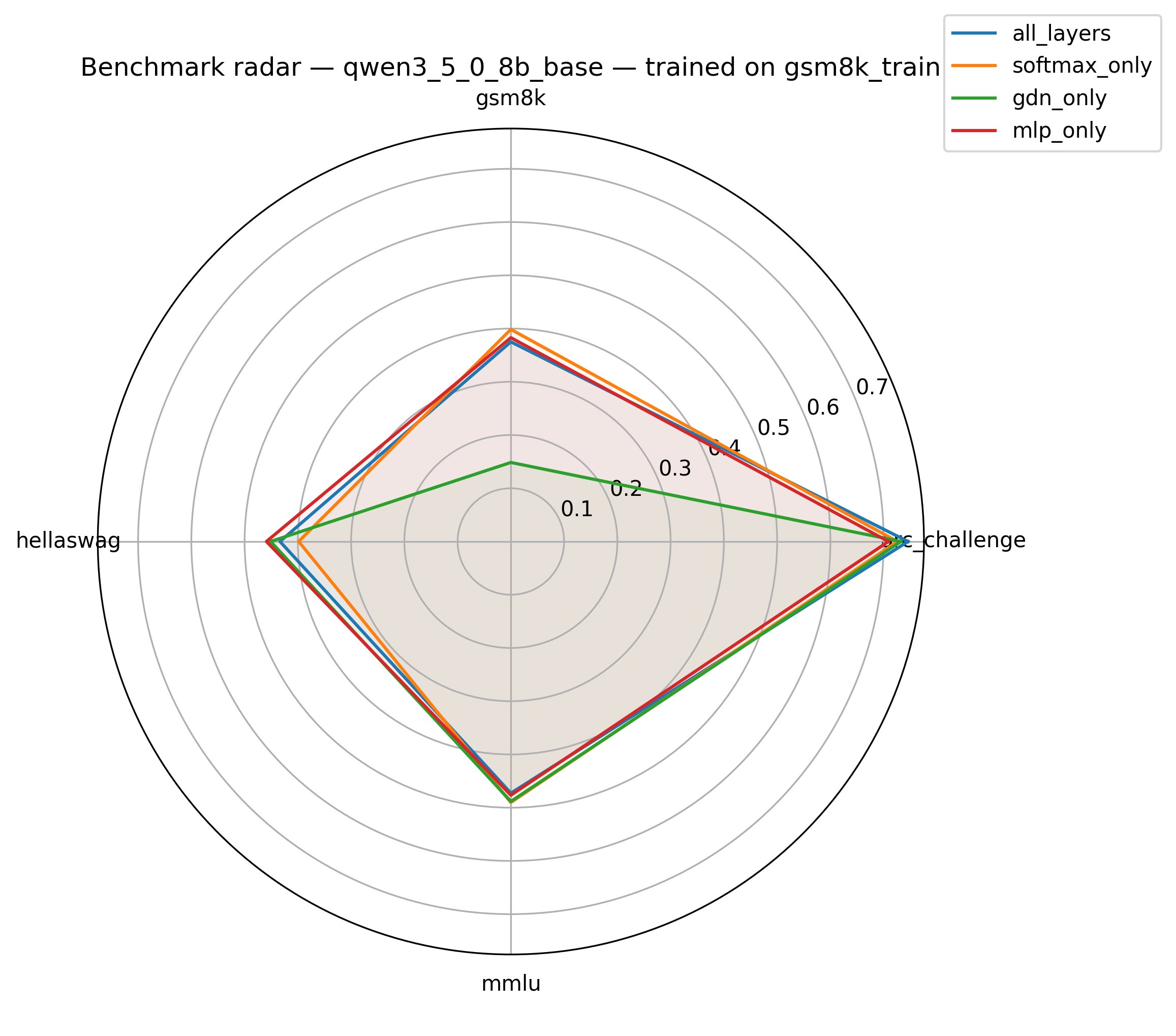
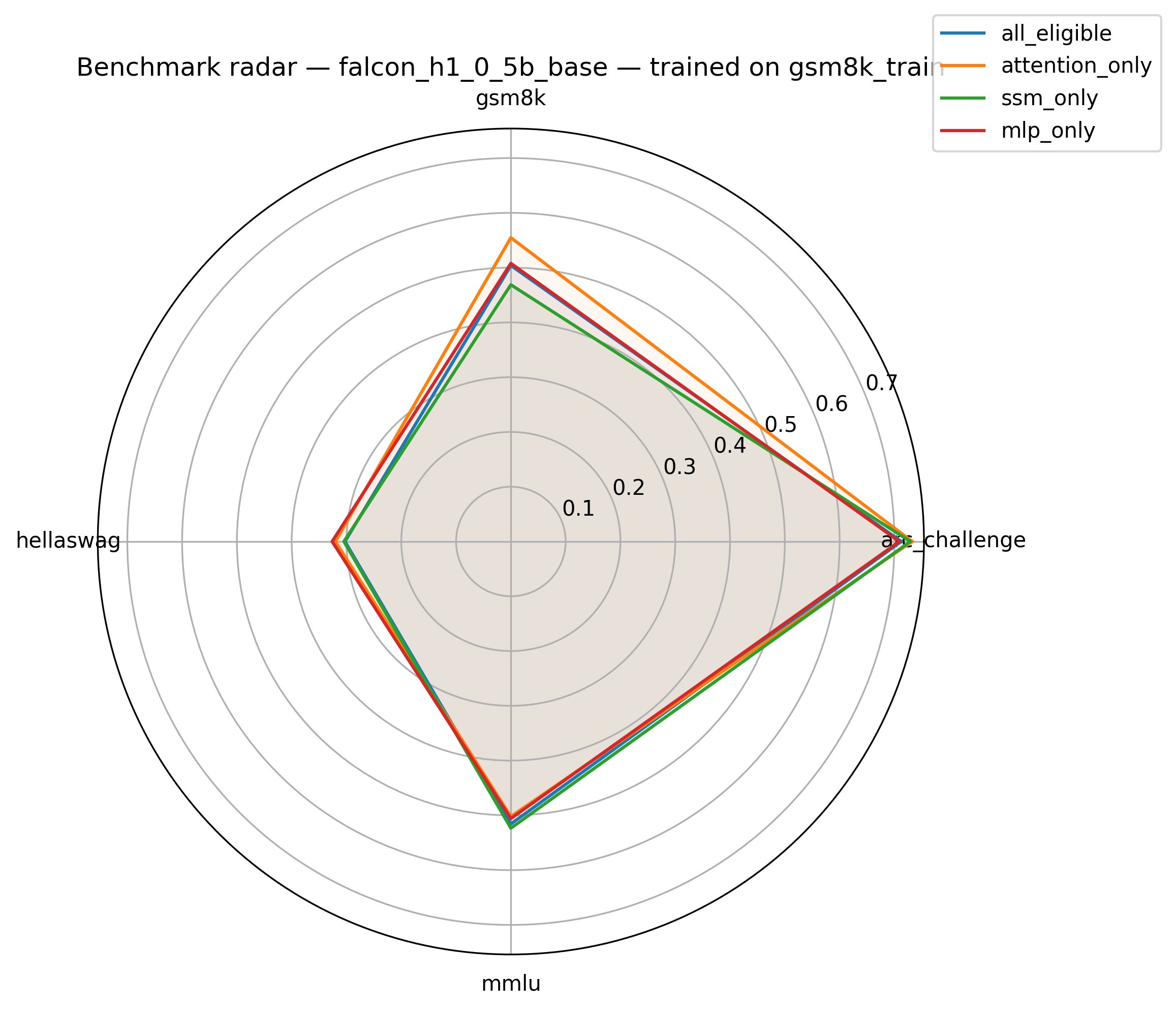
Figure 5: GSM8K-trained Qwen3.5-0.8B accuracy as a function of placement condition: attention-adapted variants outperform alternatives with fewer parameters.
Directions for Future Work
The paper identifies several limitations and future research trajectories:
- Larger models (>1B, e.g., 7B or 70B) may exhibit different component sensitivities.
- Multi-seed experiments are necessary to fully quantify statistical effects.
- Component-type sensitivity under alternative PEFT methods (e.g., IA3, prefix tuning) remains unexplored.
- Extension to other hybrid typologies (e.g., interleaved or deeper SSM-attention stacks) could reveal further adaptation regularities.
Conclusion
This systematic study demonstrates that LoRA placement in hybrid LLMs should be explicitly guided by architectural component type and topology. Attention-only adaptation is distinctly advantageous (parameter efficiency, robustness), while the recurrent backbone’s adaptability is highly topology-dependent. These findings establish component-type targeting as a core dimension of PEFT design for hybrid architectures and motivate both architecture and adaptation method refinements for future large-scale LLMs.

