- The paper presents a novel method, TabSCM, that employs structural causal models for realistic tabular data synthesis.
- It uses a hybrid approach combining score-based diffusion for continuous variables and gradient-boosted trees for categorical variables.
- Empirical evaluations demonstrate superior fidelity, utility, fairness, and fast runtime efficiency across diverse datasets.
TabSCM: A Causally-Coherent and Efficient Framework for Realistic Tabular Data Generation
Introduction
The paper "TabSCM: A practical Framework for Generating Realistic Tabular Data" (2604.22337) introduces TabSCM, a structural causal model-based method for the synthesis of high-quality, mixed-type tabular data. It directly addresses the core limitations prevailing in current state-of-the-art tabular data generators—including diffusion models, GANs, and LLM-based approaches—by providing strong causal fidelity, mechanism-level interpretability, competitive utility/faithfulness, and efficient sampling. The method models and preserves explicit causal dependencies among variables, which is critical for applications in regulated domains (e.g., finance, healthcare) where valid counterfactual reasoning, fairness, and rule adherence are required. TabSCM leverages a completed partially directed acyclic graph (CPDAG) derived from causal discovery algorithms to orient the functional relationships, and then fits conditional assignments using a hybrid of conditional diffusion models and gradient-boosted trees depending on variable type.
TabSCM employs a structured SCM formalism grounded in a DAG inferred from real observed data. The pipeline involves four canonical steps: causal discovery, graph refinement, per-variable model fitting (structural assignments), and counterfactual intervention support. Edge orientation in the CPDAG ensures compatibility with a valid topological order. For root nodes, marginal distributions are estimated nonparametrically (via KDE or categorical frequencies). For each non-root node, TabSCM fits its conditional using score-based diffusion models (for continuous children) or gradient-boosted classifiers (for categorical children), thereby achieving hybridization for arbitrarily mixed-type tables.
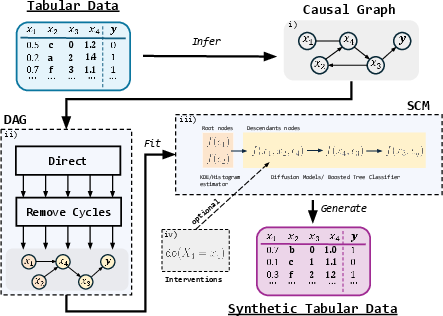
Figure 1: Conceptual framework showing causal discovery, graph refinement, assignment learning, and counterfactual modeling in TabSCM.
The generative process involves ancestral sampling along the topological order, ensuring semantic and structural validity. Counterfactual queries are natively supported; interventions set variables to fixed values, regenerating descendants accordingly using perturbed SCMs.
Empirical Evaluation
Experiments span seven public datasets capturing both classification and regression tasks, with scales ranging from small to large and diverse domains (health, finance, housing, environment). A rigorous evaluation protocol assesses statistical fidelity (marginal density error, correlation error), downstream utility (AUC/RMSE of models trained on synthetic, tested on real data), privacy (distance to closest record, DCR), imperceptibility (C2ST), and higher-order faithfulness (α-precision/β-recall).
TabSCM demonstrates SoTA or competitive results across all major axes:
- Statistical fidelity: TabSCM achieves low error in both marginal distributions and correlation structures. It frequently matches or outperforms pure diffusion and deep generative models, and exhibits strong generalizability across domains.
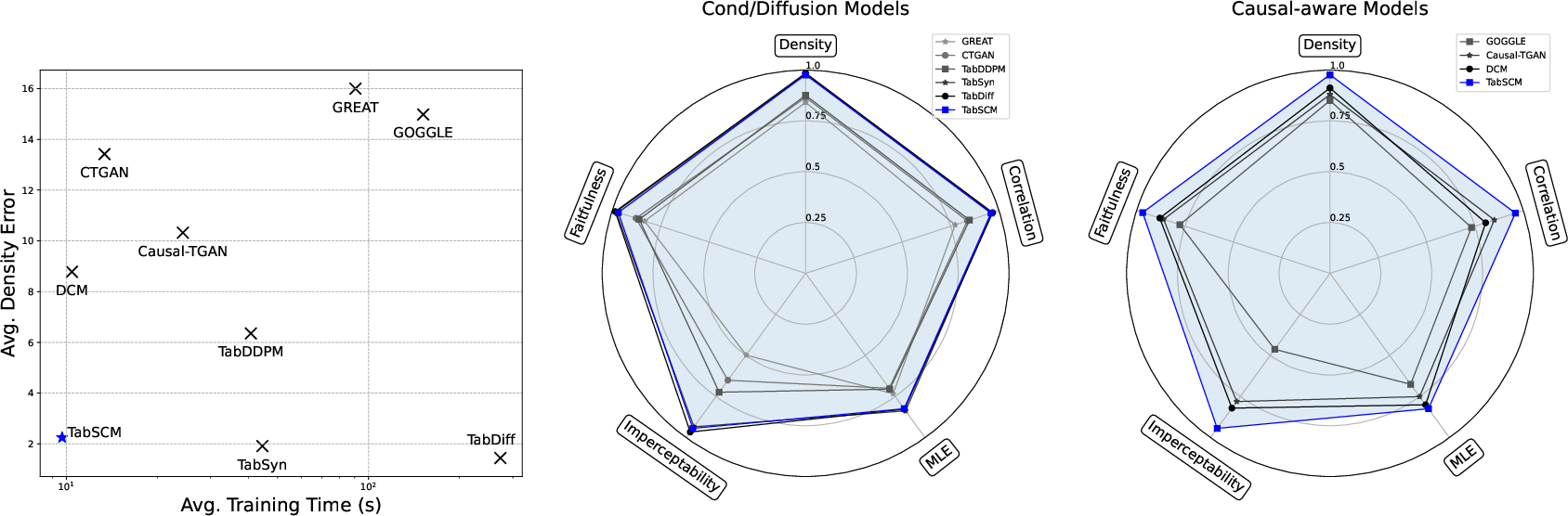
Figure 2: Average density error and training runtime across seven real datasets for TabSCM and baselines.
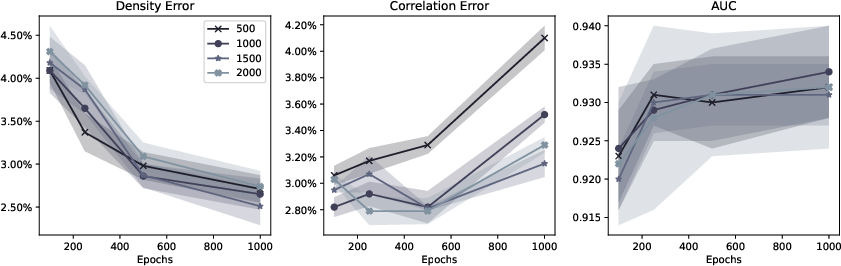
Figure 3: Mean density error, correlation error, and AUC as a function of diffusion steps and training epochs.
- Utility: Models trained on TabSCM-sampled data perform comparably to those trained on real data, as evidenced by high AUC or low RMSE, even under settings with severe class imbalance.
- Privacy: TabSCM maintains higher DCR than many deep generative baselines, indicating a lower risk of synthetic data inversion or memorization.
- Runtime: Due to the per-variable modeling and the modularization of stochastic conditionals, TabSCM is up to 583× faster than diffusion-only baselines, with scalable applicability to large datasets.
- Constraint satisfaction: TabSCM shows low domain rule violation rates, outperforming both deep and transformer-based generators on constraint-based validity checks.
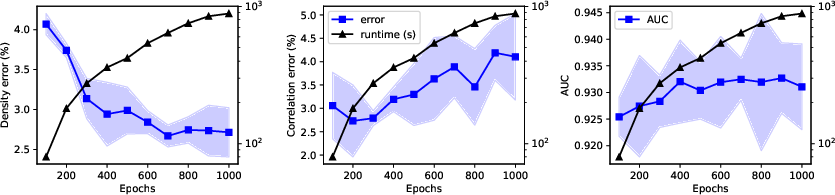
Figure 4: Epoch/running time trade-offs for density/correlation error and downstream AUC.
Imbalanced Learning, Faithfulness, and Counterfactuals
TabSCM demonstrates robust performance in minority-class upsampling and imbalanced learning scenarios. By leveraging causal conditionals and sampling from generative mechanisms conditioned on parent sets, TabSCM restores fairness (low FNR/FPR) and recovers trust metrics comparable to those on balanced data, significantly outperforming heuristic oversampling (e.g., SMOTE, ADASYN) and other baselines.
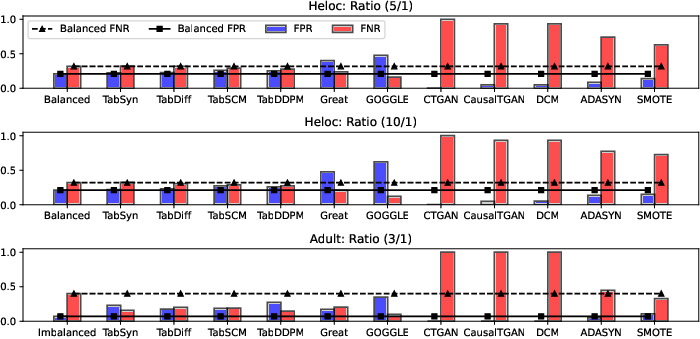
Figure 5: False Negative/Positive Rate for synthetic upsampling; TabSCM restores fairness in highly imbalanced regimes.
In higher-order structure preservation, TabSCM achieves near-diffusion-model-level performance in α-precision and β-recall, indicating that its causal decomposition does not sacrifice joint distribution fidelity. It also demonstrates top-level indistinguishability to trained C2ST detectors.
Interpretability and Mechanism-Auditing
The explicit factorization of the joint distribution allows forensic inspection, mechanism-level explanation, and stress testing. Comparison of SHAP attributions for the same real/test set, when training on either real or TabSCM-synthesized data, confirms strong alignment, highlighting the preservation of feature importances and real-world mechanisms.
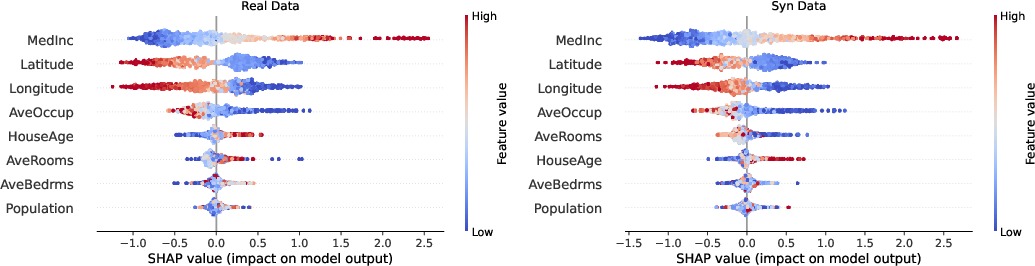
Figure 6: SHAP value agreement between models trained on real versus TabSCM-generated synthetic data.
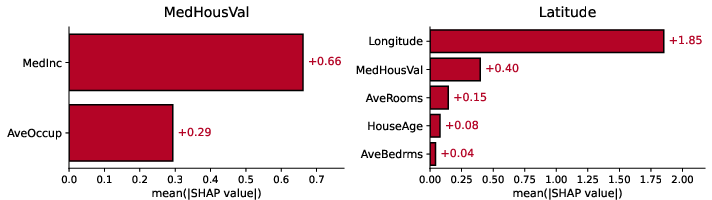
Figure 7: Mean absolute SHAP values for learned structural assignments show TabSCM recovers domain-consistent mechanisms.
Structural assignments can be independently interpreted and directly intervened upon, supporting counterfactual analysis and policy simulation at fine granularity. TabSCM generates plausible counterfactual examples with realistic attribute distributions, in contrast to predictor-driven recourse algorithms that may produce less plausible or semantically nonsensical counterfactuals under constraints.
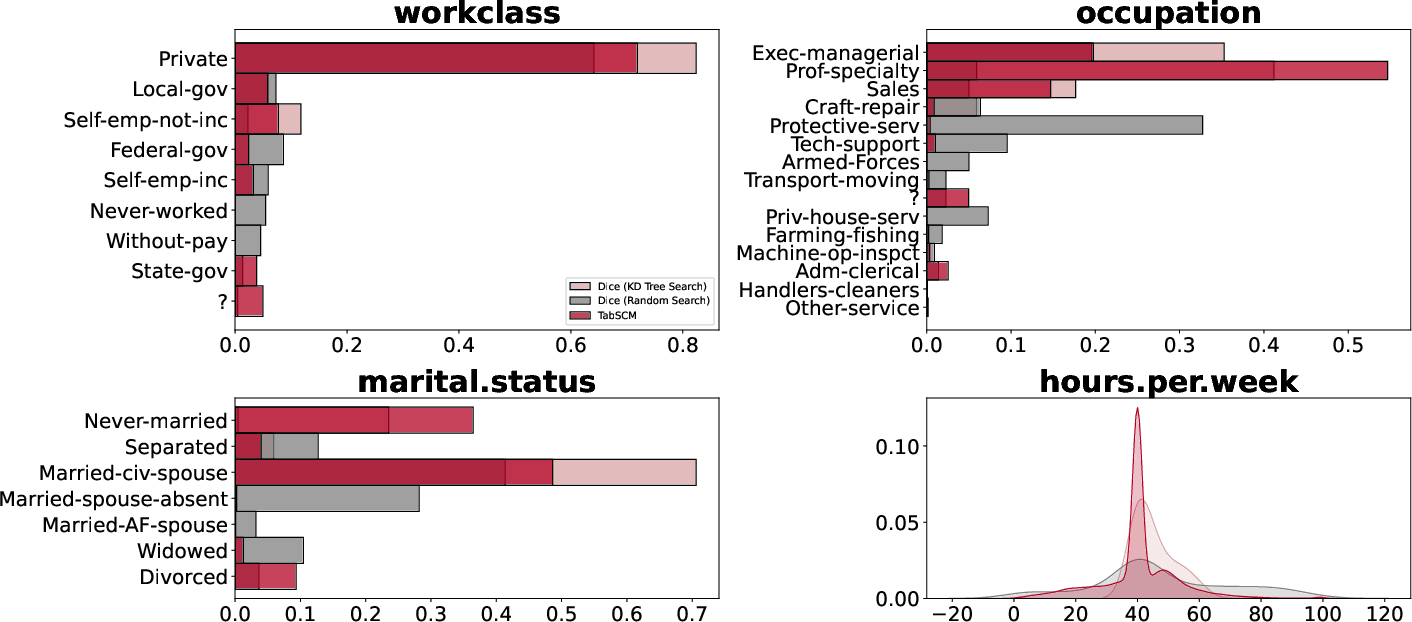
Figure 8: Marginal distributions for free attributes in counterfactual examples generated by DiCE (model-agnostic) and TabSCM (mechanism-based).
Practical and Theoretical Implications
Integrating SCMs into tabular data synthesis marks a substantive methodological advancement by merging the transparency and modularity of classical structural modeling with the expressivity and flexibility of modern score-based diffusion and ensemble methods. Practically, TabSCM addresses regulatory, auditing, and fairness requirements in sensitive application domains by providing inspection-ready, interpretable data generation, native support for interventions, and facilitation of robust policy scenario analysis. Its modular design enables efficient resource scaling and rapid iteration over heterogeneous data types. Theoretically, this work demonstrates that explicit causal factorization can yield competitive or superior fidelity and utility, and can be computationally advantageous compared to monolithic deep neural synthesis.
TabSCM's explicit mechanisms unlock extensions in fairness-aware data generation, transparent data debugging, and simulation-based counterfactual explainability. The framework is immediately extensible to more sophisticated causal discovery and refitting approaches (e.g., inclusion of latent confounders, time-dependent or hierarchical models). Furthermore, as regulatory frameworks (such as the EU AI Act) begin to require explainable synthetic data for high-stakes applications, TabSCM provides an actionable architecture template.
Conclusion
TabSCM establishes a new practical standard for causally-sound, statistically faithful, and auditable tabular synthetic data generation. It shows that hybrid diffusion-ensemble conditional assignments within an SCM framework enable strong utility, low privacy risk, rapid sample generation, and robust fair counterfactual modeling. By making the data-generating process transparent, modular, and intervention-ready, TabSCM is positioned as a foundational architecture for future practical and responsible synthetic data workflows.

