- The paper introduces a unified Bayesian framework that enables sample-efficient performance estimation and proactive failure discovery for generative AI evaluation.
- It employs transfer learning with Gaussian Process priors and optimized acquisition strategies to drastically reduce model queries while maintaining high estimation accuracy.
- ProEval's hierarchical, topic-aware sampling method effectively uncovers diverse and critical failure modes, outperforming traditional red-teaming and random sampling methods.
Introduction and Problem Motivation
Evaluation of generative AI models, notably LLMs and multi-modal LMs, is impeded by increasing computational and annotation expense due to long inference times and costly human or LLM-based raters. The proliferation of both models and benchmarks has created an unsustainable status quo, where evaluation cycles are resource-inefficient and rarely illuminate rare but critical failure modes. Most contemporary strategies rely either on static test set downsampling—missing rare failures—or active test selection with weak or non-transferable surrogates.
ProEval Framework Overview
ProEval formalizes generative model evaluation as a dual Bayesian objective: sample-efficient performance estimation and proactive, diverse failure discovery, both grounded in probabilistic inference and transfer learning.
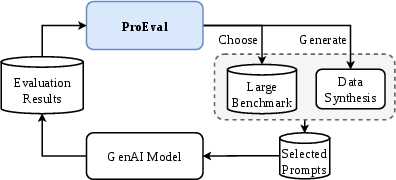
Figure 1: The ProEval framework adapts sampling to maximize informativeness using prior evaluation results and generative synthesis for failure discovery.
The score function f(x) mapping inputs to performance metrics (e.g., error severity, safety violation rate) is treated as a latent function. The framework exploits structural correlations across models and benchmarks, constructing informed GP priors from historical data (empirical score matrices or semantically aligned embeddings), enabling robust estimation and sample acquisition policies for two tasks:
- Performance Estimation: Formulated as Bayesian quadrature (BQ), targeting the aggregate expected value Ep(x)[f(x)], with acquisition driven by maximal reduction in posterior estimator variance.
- Failure Region Discovery: Cast as probabilistic superlevel set estimation, i.e., identifying x s.t. f(x)≥λ, with acquisition balancing exploitation (high failure likelihood) and exploration (epistemic uncertainty), both in static pools and via generative synthesis.
Bayesian GP Priors via Transfer Learning
ProEval’s crucial differentiator is its ability to leverage historical datasets for highly informative GP priors. For fixed benchmarks, empirical means and covariances across historical model outputs (score features) yield low-variance linear GPs. For novel benchmarks or inputs lacking direct precedent, prompt feature GPs are constructed via neural embeddings, with encoder and kernel parameters optimized to maximize marginal likelihood across existing datasets.
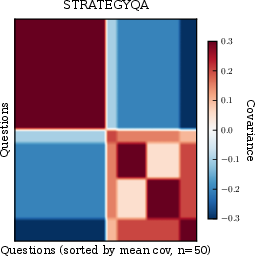
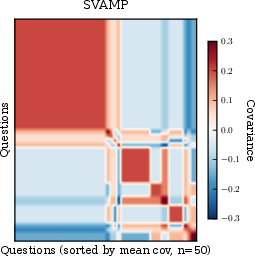
Figure 2: Sample covariance analysis in benchmarks demonstrates strong inter-model/inter-input correlations in question failures, justifying transfer learning.

Figure 3: Pre-trained embedding function with learnable parameters encodes input similarity for cross-benchmark/generalization scenarios.
Effective transfer is conditional on source–target alignment; negative transfer from misaligned source models is explicitly minimized via GMM clustering of model behavior profiles, with abstention policies where sufficient in-cluster data is absent.
Sample-Efficient Active Evaluation
The proposed BQ estimator maintains analytical unbiasedness and bounded error under empirical priors, with provable regret guarantees if the historical model set is sufficiently diverse and numerous. The acquisition strategy greedily selects queries maximizing expected reduction in estimator posterior variance, using efficient matrix operations enabled by linearized kernels.
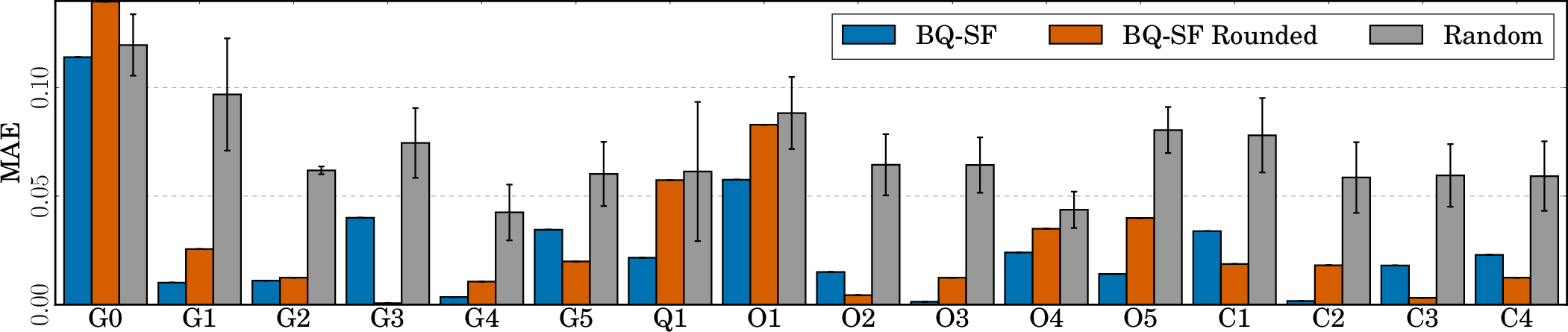
Figure 4: ProEval with BQ achieves uniformly lower MAE on StrategyQA with only a 1% sampling budget compared to random sampling and active baselines.
Figure 5: Efficiency is robust across the entire model suite; BQ consistently requires minimal samples to meet 1% MAE threshold.
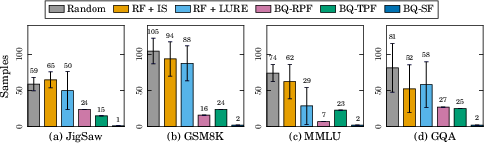
Figure 6: BQ achieves up to 65× lower sample complexity to 1% MAE than baselines on Gemini 2.5 Flash across multiple benchmarks.
In ablation, negative transfer (from source–target misalignment) degrades MAE by over an order of magnitude, confirming the vital role of statistical model alignment and the need for robust behavioral clustering in source selection.
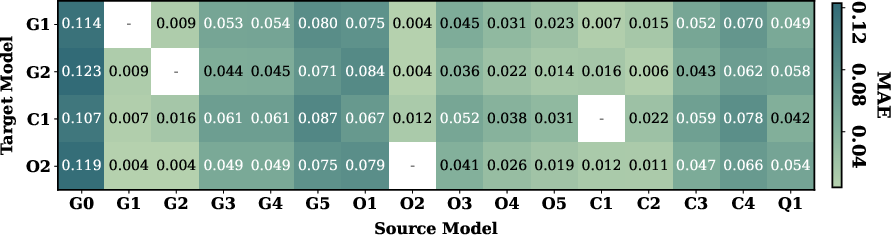
Figure 7: Inclusion of OOD source models in transfer leads to substantial estimator error escalation, demonstrating the necessity of source filtering.
Proactive Failure Discovery: Black-Box Red Teaming
Failure region discovery couples superlevel set exploration in static pools with LLM-driven query synthesis anchored on identified hard examples. ProEval introduces a hierarchical topic-aware sampling policy (TSS), decomposing the search over high-level semantic clusters with multi-armed bandit algorithms and generative guidance to avoid failure mode collapse and achieve diverse coverage.
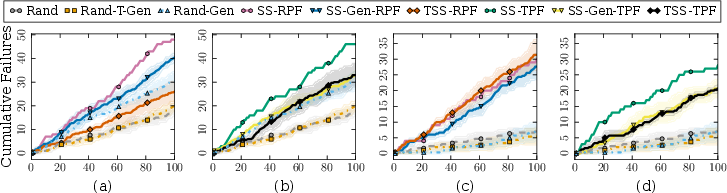
Figure 8: Across both implicit reasoning and math, SS-Gen and TSS strategies discover failures at substantially higher rates and with greater diversity compared to random or anchor-agnostic generation.
Diversity is measured by log-determinant (feature space), topic entropy, and composite scores. TSS and SS-Gen dominate in both failure rate and diversity, especially on challenging reasoning tasks, and show robust performance across a spectrum of target models and generators.
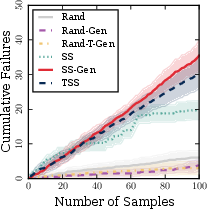
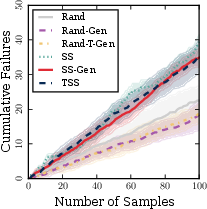
Figure 9: Cumulative failures discovered by generative synthesis—ProEval’s TSS and SS-Gen strategies retain near-linear discovery rates, while random-generation baselines rapidly saturate.
Quantitative Results and Empirical Insights
- Sample Efficiency: ProEval requires only 1–27 model queries to achieve 1% MAE on aggregate estimation across benchmarks and models, a reduction of 8–65× compared to active and random baselines.
- Failure Discovery: For generative evaluation, SS-Gen and TSS strategies produce 2–5× higher failure detection rates and substantially greater diversity than LLM- or human-red-teaming baselines. Maximum topic entropy and embedding diversity are achieved with TSS, indicating robust exploration.
- Ablations: Estimation accuracy is strongly correlated with embedding model quality for prompt-feature GPs; inclusion of Chain-of-Thought traces further reduces MAE on reasoning tasks. Negative transfer is quantitatively catastrophic, reinforcing the need for model alignment and abstention.
Practical and Theoretical Implications
Practically, ProEval accelerates GenAI model iteration by minimizing required queries and rater effort for both core metric estimation and robustness analysis. Theoretically, the framework unifies Bayesian quadrature and superlevel set estimation in a transfer-aware context, extending BQ techniques to population metrics over high-dimensional, semantically-embedded input spaces. The construct of abstention via Gaussianity-based model selection introduces a principled, non-myopic criterion for reliable evaluation.
The implication is that high-fidelity evaluation—critical for safety, fairness, and deployment—is possible with minimal resource allocation, provided adequate historical evaluation structure is leveraged. This enables rapid model selection, targeted benchmarking, and dynamic dataset construction, both for production GenAI deployments and open-ended research.
Conclusion
ProEval advances the state of generative model evaluation by unifying sample-efficient estimation and proactive, diverse failure discovery under a rigorous Bayesian transfer learning framework. Empirically, it achieves a multi-order-of-magnitude reduction in evaluation cost and a commensurate increase in capability for detecting model vulnerabilities. This enables faster, more reliable deployment and opens avenues for acquisition-driven dataset construction, scalable agentic evaluation, and automated model siting for a spectrum of modalities and use-cases (2604.23099).