- The paper demonstrates how intelligent batching and expert co-placement reduce inter-node communication by up to 20% and improve runtime by 6%.
- It systematically characterizes expert activation patterns across SOTA MoE models, revealing domain-specific clustering and significant load imbalances.
- The proposed methods enhance both system efficiency and security by mitigating load imbalances and potential side-channel risks.
Scaling Multi-Node Mixture-of-Experts Inference Using Expert Activation Patterns
Introduction
The paper "Scaling Multi-Node Mixture-of-Experts Inference Using Expert Activation Patterns" (2604.23150) addresses a critical systems challenge in the deployment of state-of-the-art (SOTA) Mixture-of-Experts (MoE) models: efficient multi-node inference at hyperscale. While MoE architectures dramatically scale model capacity by activating only a sparse subset of experts per token—thus maintaining competitive inference FLOPs—distributed inference at scale is fundamentally bottlenecked by token-routing-induced load imbalances and inter-node communication overheads. This work systematically characterizes expert activation patterns across leading MoE models and leverages these insights to design novel, data-driven batching and expert placement strategies that achieve measurable throughput and latency improvements.
Challenges in Multi-Node MoE Inference
Disaggregated inference of large MoE models, as implemented in Llama 4 Maverick, DeepSeek V3, and Qwen3-235B, is hindered by a fundamental mismatch between gated token routing and the hardware locality of expert parameters. While standard dense model parallelism yields predictable workload-balancing and efficient hardware utilization, MoE inference is highly dynamic and input-dependent. Tokens addressed to remote, non-local experts initiate expensive all-to-all inter-node communication patterns. This effect is greatly amplified under conditions of expert load imbalance or domain-specific specialization within expert layers.
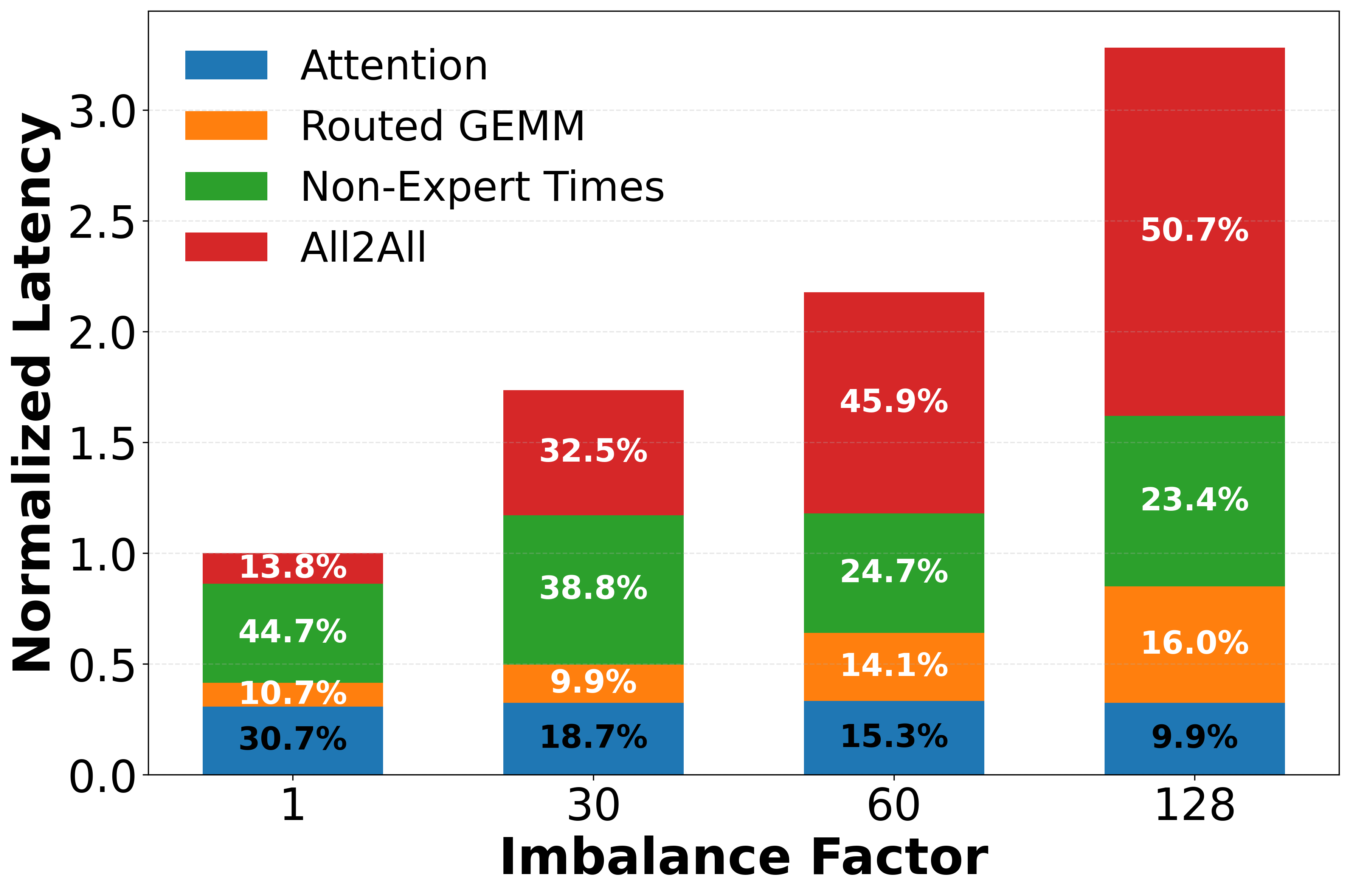
Figure 1: Multi-node Llama-Maverick decode latency breakdown reveals communication overheads dominate when expert parallelism is imbalanced.
Characterization of Expert Activation Patterns
Through instrumentation and large-scale profiling (over 100,000 requests) of SOTA MoE models on diverse datasets, the paper identifies consistent and critical behaviors in expert activation:
- Expert load imbalance is pronounced and highly dataset/model-dependent, frequently resulting in certain experts being overloaded by factors exceeding 80× relative to optimal load, particularly for specialized tasks such as mathematical or coding queries.
- Domain-specific clustering is observed, where datasets from similar modalities (e.g., MATH and GSM8K, or MBPP and HumanEval) provoke correlated activation of particular experts.
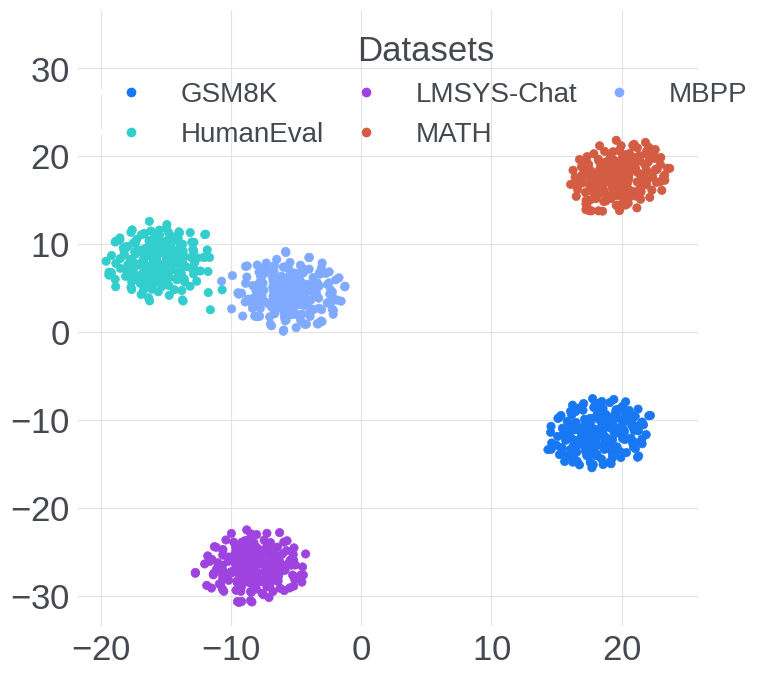
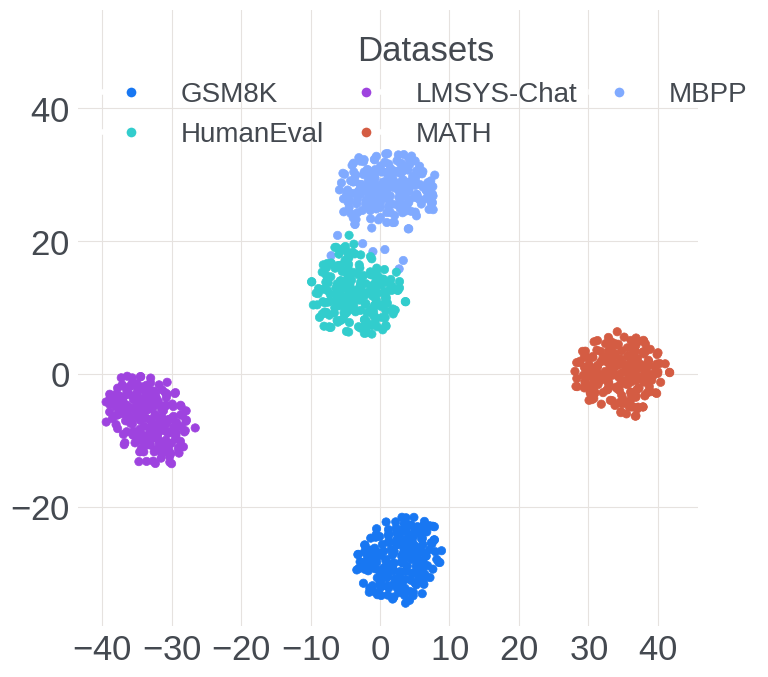
Figure 2: Visualization of dataset-wise expert activation patterns during decode, showing specialization and domain-aware clustering.
- Cross-dataset and stage-wise correlation demonstrates predictability in expert usage: the experts activated during prefill stages are highly indicative of those required during decode, providing a mechanism for request pre-grouping.
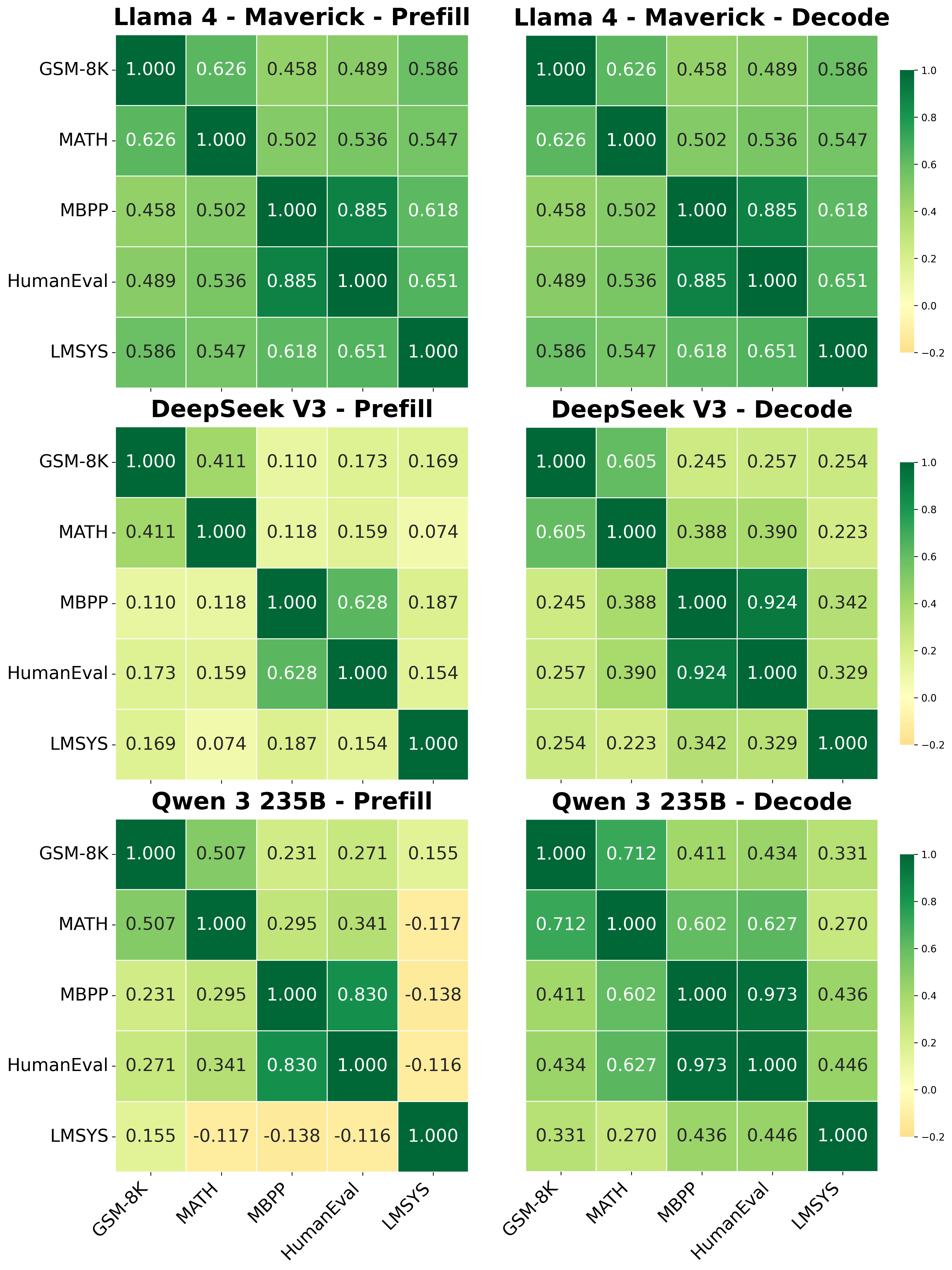
Figure 3: Expert activation correlation heatmaps show high intra-domain correlation and clear clustering between related datasets.
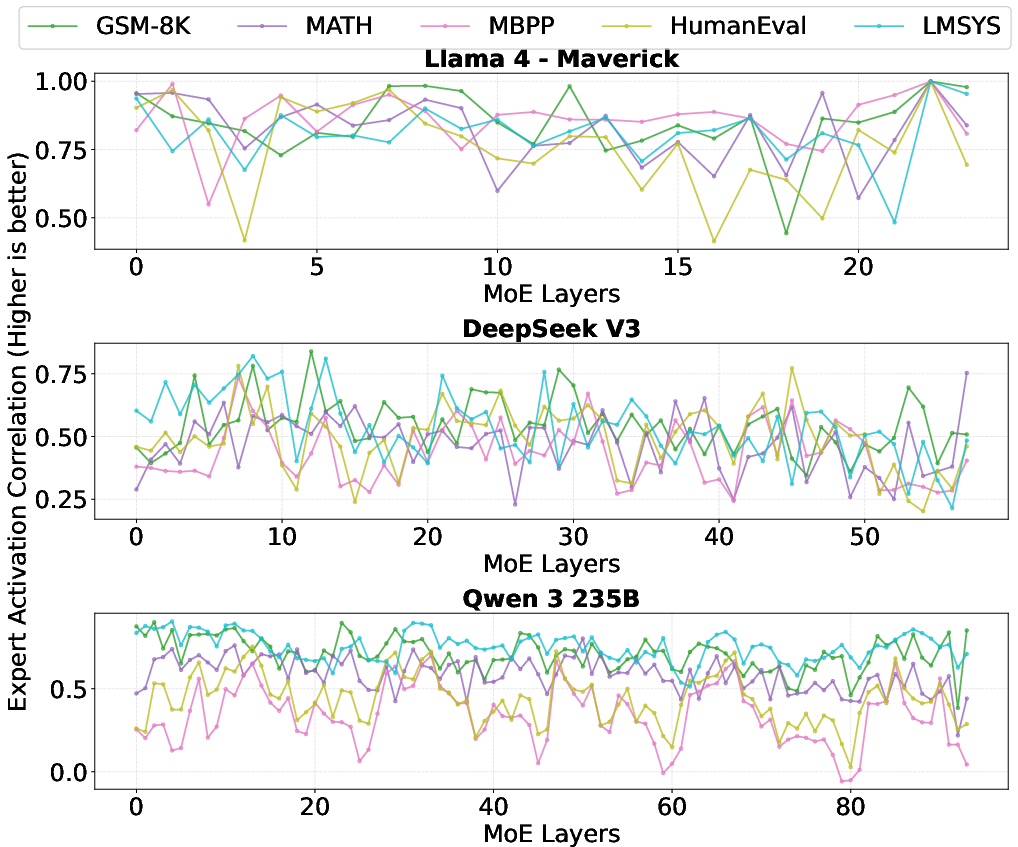
Figure 4: Prefill and decode stages exhibit strong expert activation correlation across most MoE layers in SOTA models.
- Request-level clustering and request type inference: t-SNE visualization and logistic regression analysis reveal expert activation patterns strongly encode dataset membership and request type.
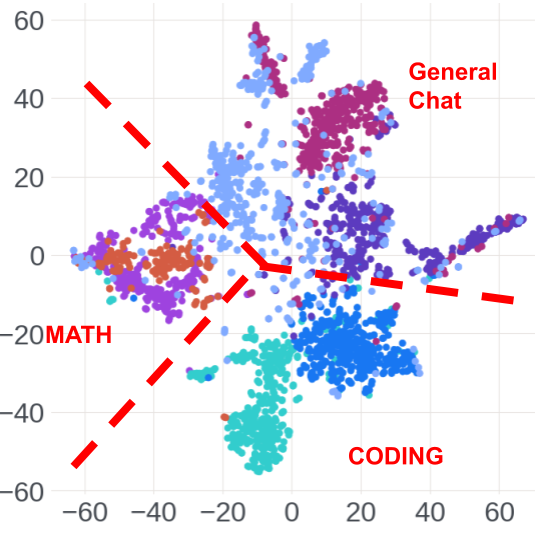
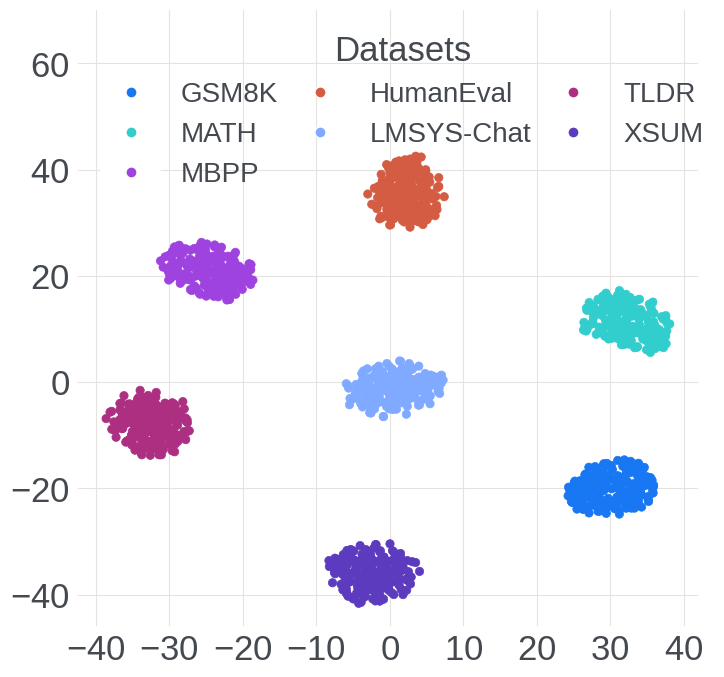
Figure 5: t-SNE visualization of Layer 17 expert activations in Llama-Maverick shows tight clustering by dataset.
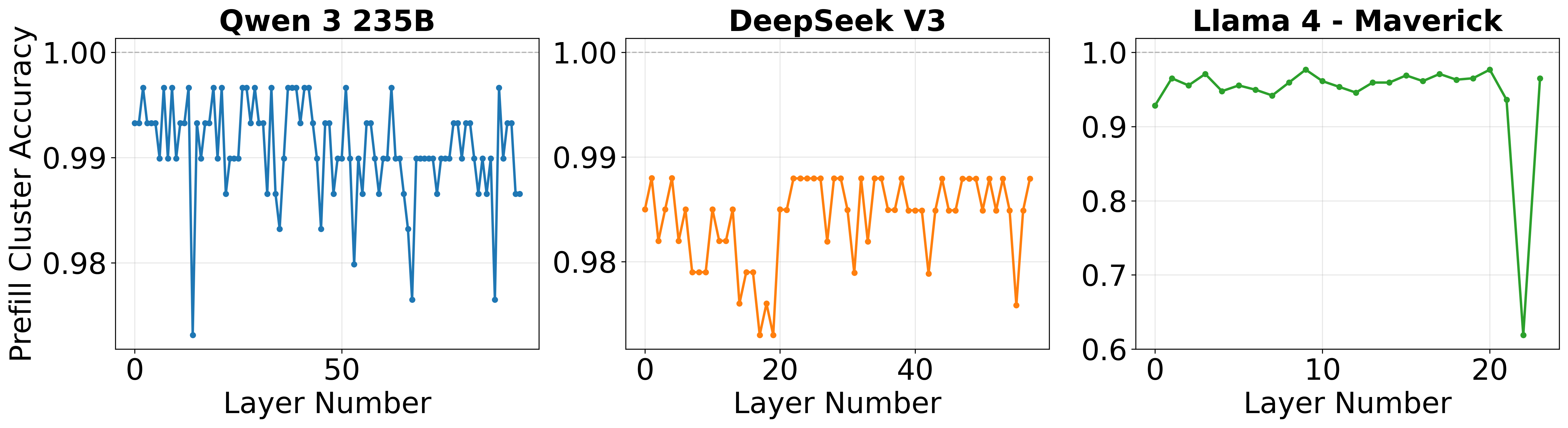
Figure 6: High classification accuracy (>98%) for request type based purely on prefill expert activation patterns.
Importantly, these activation patterns also create a side-channel that can potentially leak information about input type or user intent, even without access to raw token content.
Workload-Aware Batching and Expert Placement
Motivated by the above findings, the paper proposes two synergistic system-level optimizations:
- Workload-aware micro-batch grouping: After the prefill stage, inference requests are clustered—using normalized expert activation vectors—so that requests likely to activate similar sets of experts are co-batched. This maximizes intra-node reuse of local experts and rationalizes batch-level hardware resource allocation.
- Data-driven expert placement: A two-phase expert assignment algorithm seeks to colocate strongly co-activated experts on the same node. By aggregating usage statistics from workload clusters, experts are mapped to hardware groups so as to minimize the fraction of routed tokens requiring off-node all-to-all transfers.
The method rigorously accounts for the constraints of redundancy (for expert coverage and fault-tolerance), balanced memory usage, and maximal specialist coverage per batch.
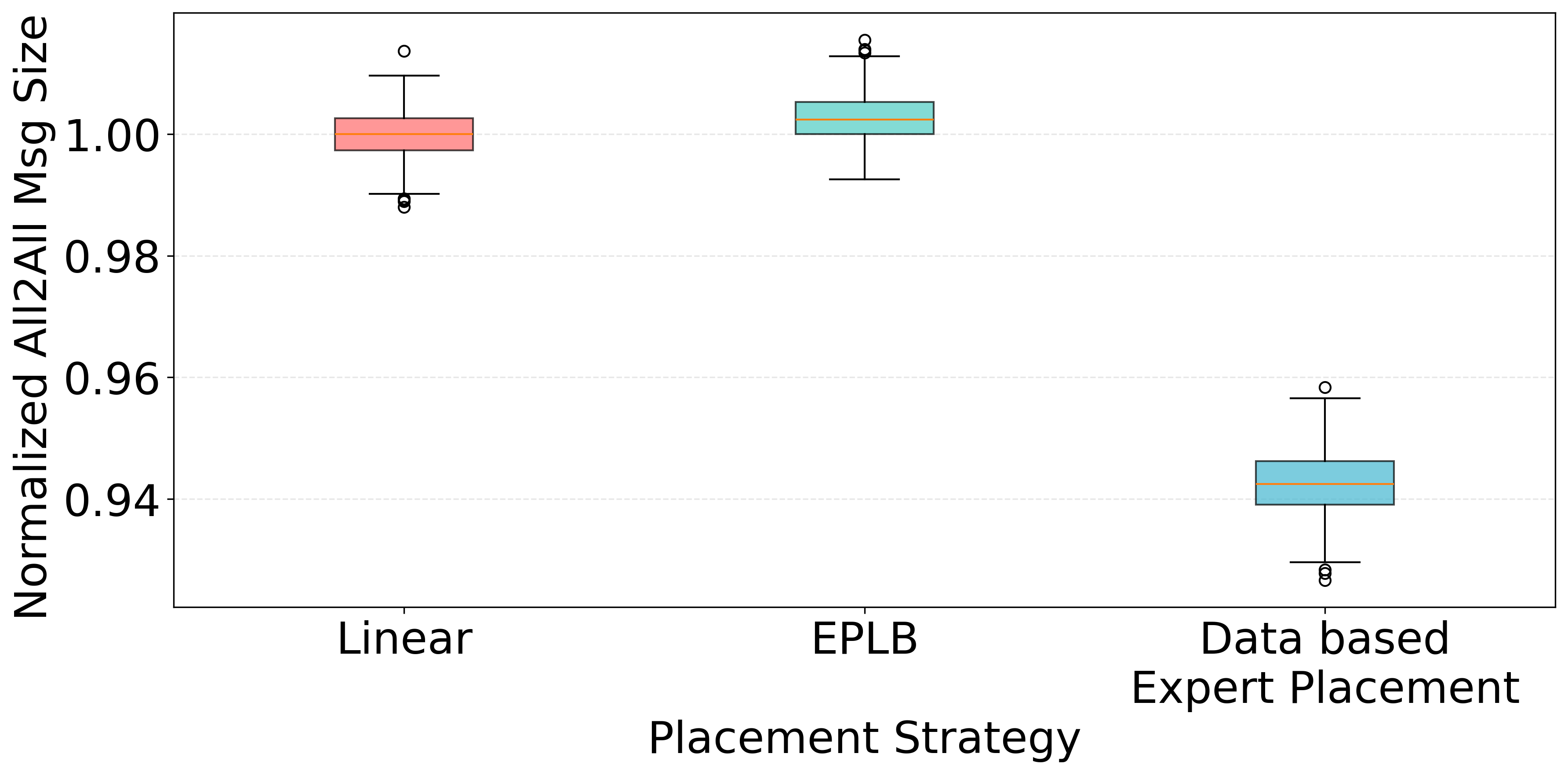
Figure 7: Data-based expert placement significantly reduces normalized all-to-all communication size for DeepSeek-V3.
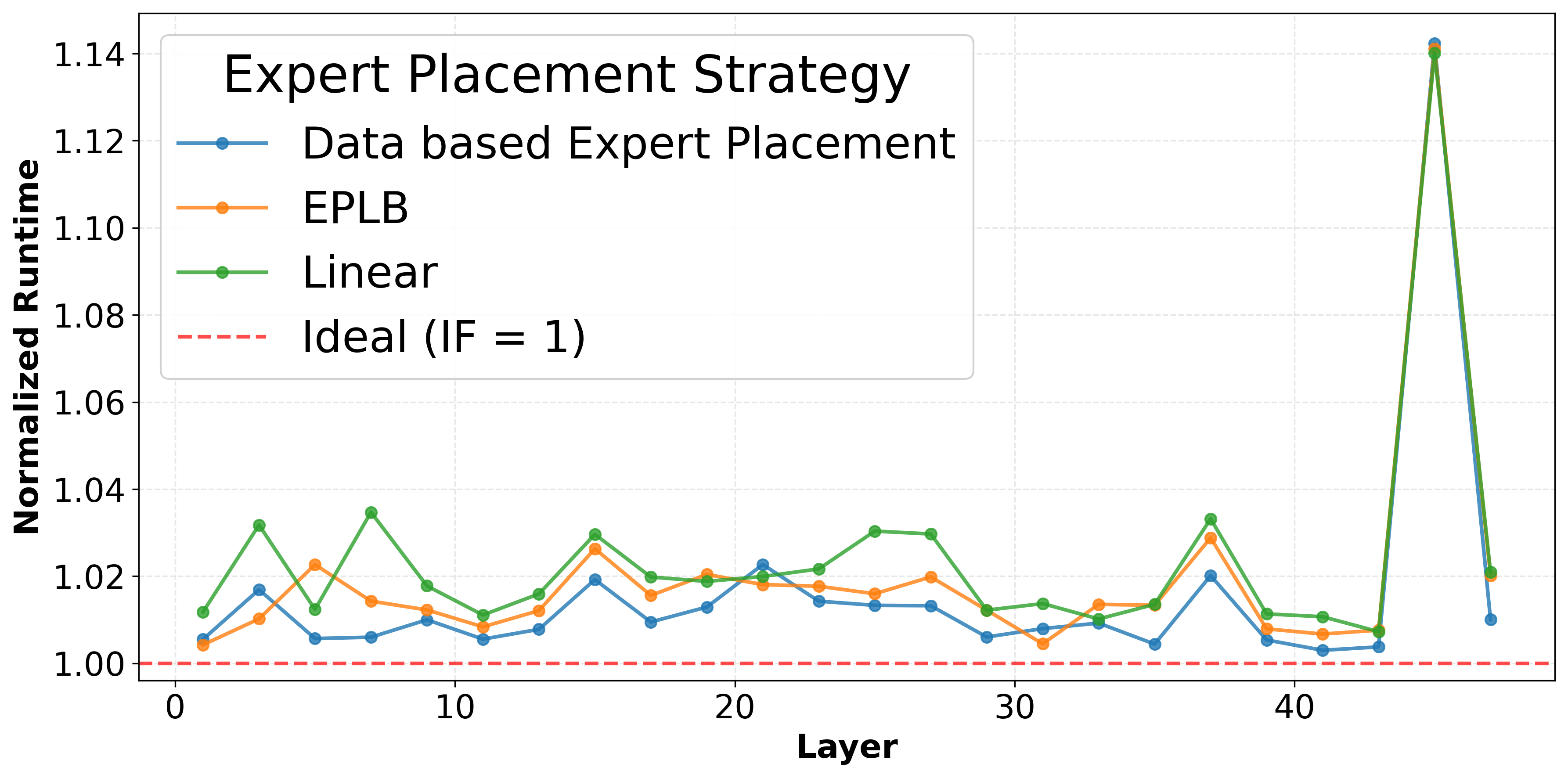
Figure 8: MoE layer runtime for Llama-Maverick showcases runtime improvement of data-based placement over standard strategies.
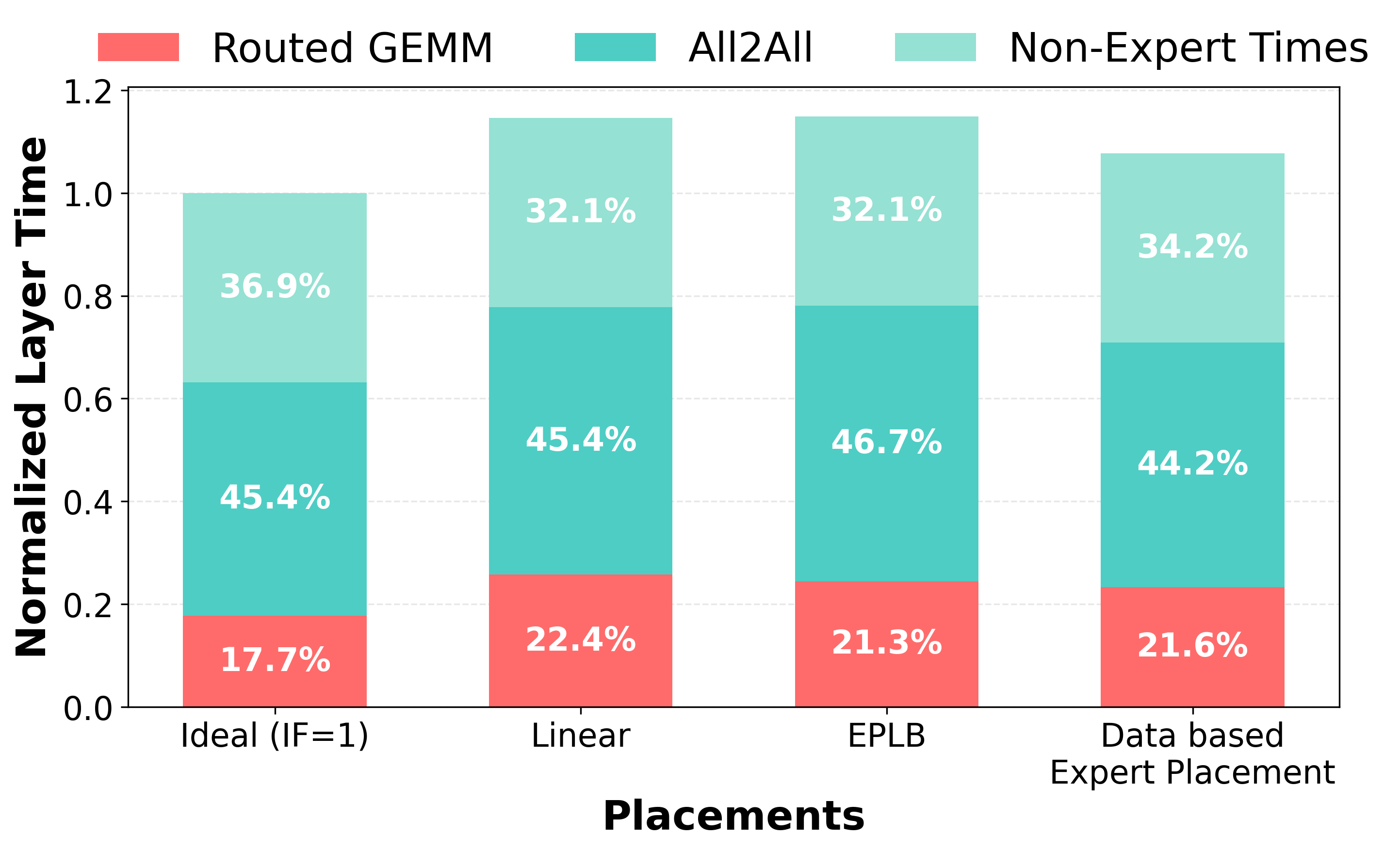
Figure 9: Qwen3-235B-A22B runtime breakdown confirms the runtime and communication efficiency of optimized expert placement.
Evaluation
Across 100,000+ requests and three flagship MoE models over multiple domains, the paper delivers several strong empirical results:
- Up to 20% reduction in inter-node all-to-all communication volume using data-driven expert placement relative to current linear or load-balance-only baselines.
- MoE layer runtime reductions of up to 6% in production-scale multi-node clusters, with the improvement magnitude bounded by current all-to-all kernel implementation and communication padding overhead.
- Prefill-to-decode clustering supports near-perfect request classification, with >98% accuracy, enabling robust batching strategies with minimal misallocation.
- The predicted clustering not only improves hardware utilization and throughput, but establishes a foundation for further system-level acceleration techniques and potential hardware/OS stack co-optimization.
Implications for MoE System Design and Security
The findings have both practical and theoretical consequences for AI inference:
- Systems: Workload-aware batching and expert co-placement is now a practical baseline for any hyperscale MoE inference stack, whether for model serving, routing, or batching strategies in datacenter environments.
- Security: The strong correlation between activation patterns and request type introduces non-trivial privacy risks. Observability of expert routing logs may enable adversarial user intent inference, even in the absence of token access.
- Future optimizations: The efficacy of the proposed approach suggests that system software for distributed MoE inference should natively support adaptive expert migration, cluster-aware scheduling, and improved collective communication primitives (e.g., unpadded all-to-all, topology-aware reduced collectives).
Conclusion
This work makes a substantive step toward the realization of efficient, scalable, privacy-aware deployment of Mixture-of-Experts models by systematizing the empirical analysis of expert activation patterns and leveraging them for batching and placement optimizations. The demonstrated reductions in communication volume and runtime, together with the outlined risk of side-channel information leakage, establish data-driven expert activation analysis as a cornerstone for both performance engineering and safeguarding in MoE-based AI clusters. Further advancements in network kernel implementation and dynamic resource management, as proposed in the conclusion, are likely to magnify these gains and will be critical in future exascale LLM deployments.