- The paper demonstrates that embedding an LLM-driven reviewer in GitHub workflows enhances self-regulated learning and code quality through scaffolded, checklist-driven feedback.
- It employs a mixed-methods approach, combining objective repository metrics and survey data to reveal iterative student behaviors, with action rates of about 32%-33% after AI feedback.
- The study highlights the importance of pedagogical co-design and scope control in maintaining student agency and mitigating over-reliance on AI while ensuring constructive critique.
AI-Assisted Code Review for Code Quality and Self-Regulated Learning: An Experience Report
Introduction
The integration of LLM-based code review tools within software engineering education is an emergent paradigm responding to growing industry demand for human–AI collaborative workflows. The paper "AI-Assisted Code Review as a Scaffold for Code Quality and Self-Regulated Learning: An Experience Report" (2604.23251) systematically examines the deployment of an LLM-driven reviewer (LLM-Reviewer) embedded directly in GitHub pull request workflows for two large cohorts in a Master's capstone course. The study investigates behavioral engagement and self-regulated learning (SRL) processes through objective repository metrics, survey responses, and reflective reports, providing both quantitative and qualitative evaluations. Key contributions include (i) an in-workflow AI reviewer design mitigating cognitive offloading, (ii) cross-sectional contrasts between cohorts, (iii) mixed-methods analysis, and (iv) actionable pedagogy for responsible, student-agency-centered AI-assisted review.
Research Context and Design
The study was carried out over two semesters (2023, 2024) at the University of Melbourne's Master of Information Technology capstone, with >100 consenting students divided across agile sprints. The LLM-Reviewer was implemented as an on-demand GitHub Action, producing rubric-structured critique via GPT-3.5 (2023) and GPT-4 (2024). The tool injected checklist-driven feedback, aligned with established code review categorizations (e.g., M{\"a}ntyl{\"a} and Lassenius [mantyla2008types]), and explicitly avoided delivering code solutions, thereby enforcing human-in-the-loop decision making.
The research employed a mixed-methods strategy. Objective metrics included counts and statuses of PRs, commits, AI reviewer comments, and a defined "Action Rate" measuring follow-up student commits after receiving AI feedback. Subjective data comprised structured surveys and 400-word reflective reports, enabling triangulation of behavioral evidence with perceptions of utility and tool limitations.
Quantitative Engagement Analysis
Activity data demonstrated substantial iterative behaviors that matured between cohorts. Total PRs increased from 581 (2023) to 1176 (2024), with the latter exhibiting refined agile practice and greater PR volume. Technical friction, including bot failures due to API or scoping errors, was resolved after enhanced onboarding and guardrails—failed AI attempts dropped from 227 in 2023 to zero in 2024. Despite the adoption shift (93% teams used tool in 2023 vs 50% in 2024), the critical response metric stabilized: 32% (2023) and 33% (2024) of AI-reviewed PRs were followed by actionable code changes.
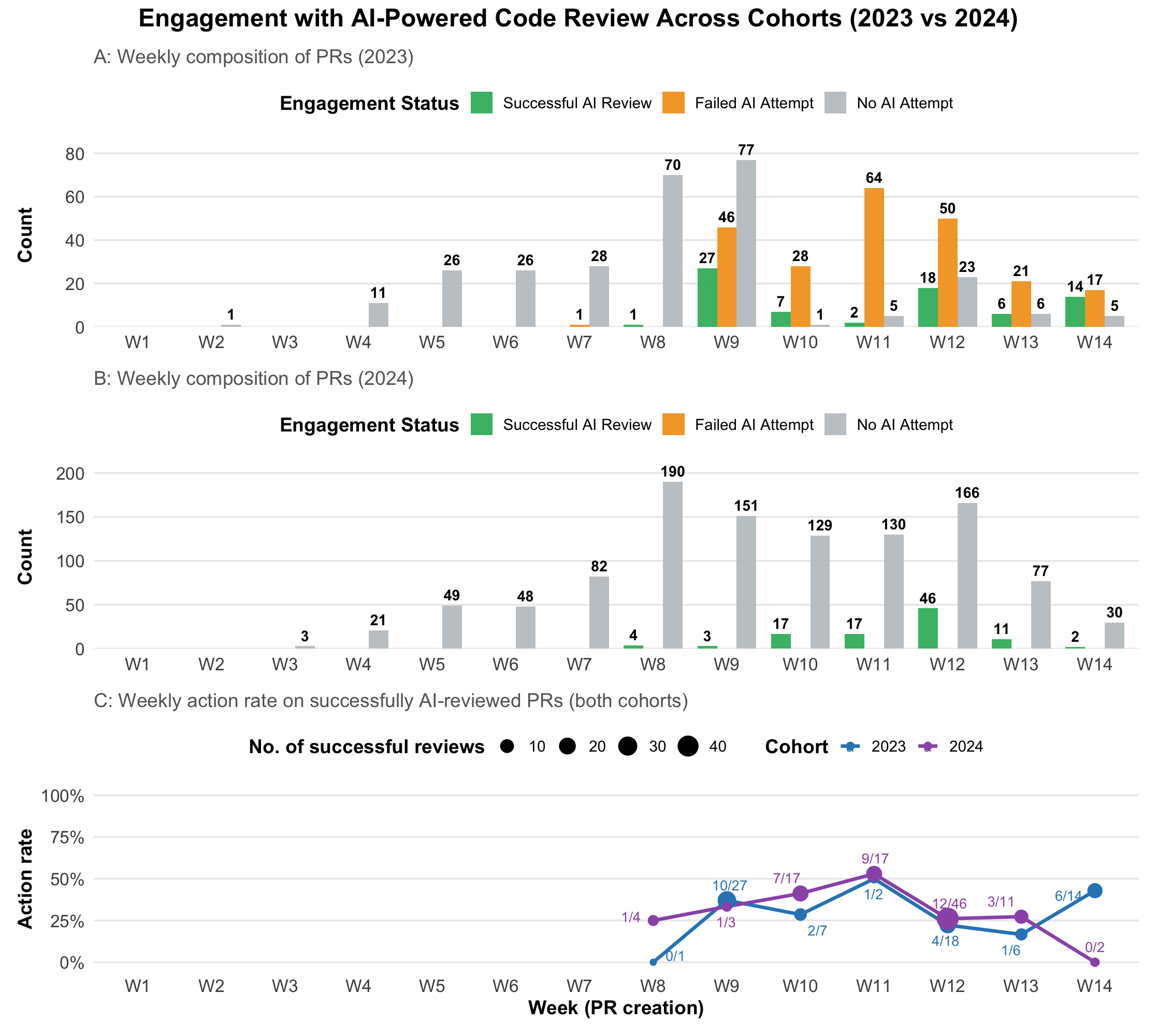
Figure 1: Weekly breakdown of student engagement with LLM-Reviewer across cohorts; Panel C visualizes the action rate and its stability as a function of successful AI reviews.
Temporal analysis aligned engagement spikes with agile sprints. Over-reliance episodes—large-scale, whole-repo reviews—were observed and subsequently mitigated with scoping restrictions and formative feedback. Notably, the action rate (successful AI review → subsequent commit) peaked during active development cycles and diverged in the final week between cohorts, suggesting an evolution from last-minute quality efforts (2023) to continuous integration (2024).
Fine-grained traces confirm the action metric’s reliability: e.g., PRs receiving feedback on documentation, structure, and readability resulted in a sequence of targeted student commits directly addressing the reviewer’s critiques. This linkage provides robust evidence for SRL cycles (monitor–evaluate–plan–act) enacted in authentic student workflows.
Qualitative Analysis: Perception and SRL Impact
The thematic analysis of student reflections (2023 cohort) identified four dominant themes:
- Learning and Skill Development: Tool used for language and legacy code comprehension, security-aware coding, and alternative approaches. Especially impactful for novices/intermediates, promoting independent reasoning beyond mere copying.
- Code Quality and Documentation: Students reported improvements in naming, formatting, and generating meaningful documentation. Feedback was explicit, clear, and actionable, reinforcing professional hygiene and conventions.
- Accelerated Debugging and Understanding: AI enabled efficient bug identification, explanations of incorrect behaviors, and comprehension of complex functions. Reviews offered multi-perspective evaluation, increasing productivity over manual checklists.
- Limitations: Main limitations included lack of system-level context awareness, technical constraints (e.g., prompt size), contradictory feedback, over-reliance risks, and privacy/cost concerns for full codebases.
Strong numerical results in survey responses validated qualitative claims: 80% agreed the tool enhanced code review skills, 73% improved understanding of coding conventions, and 87% rated the AI review process as more productive than manual approaches.
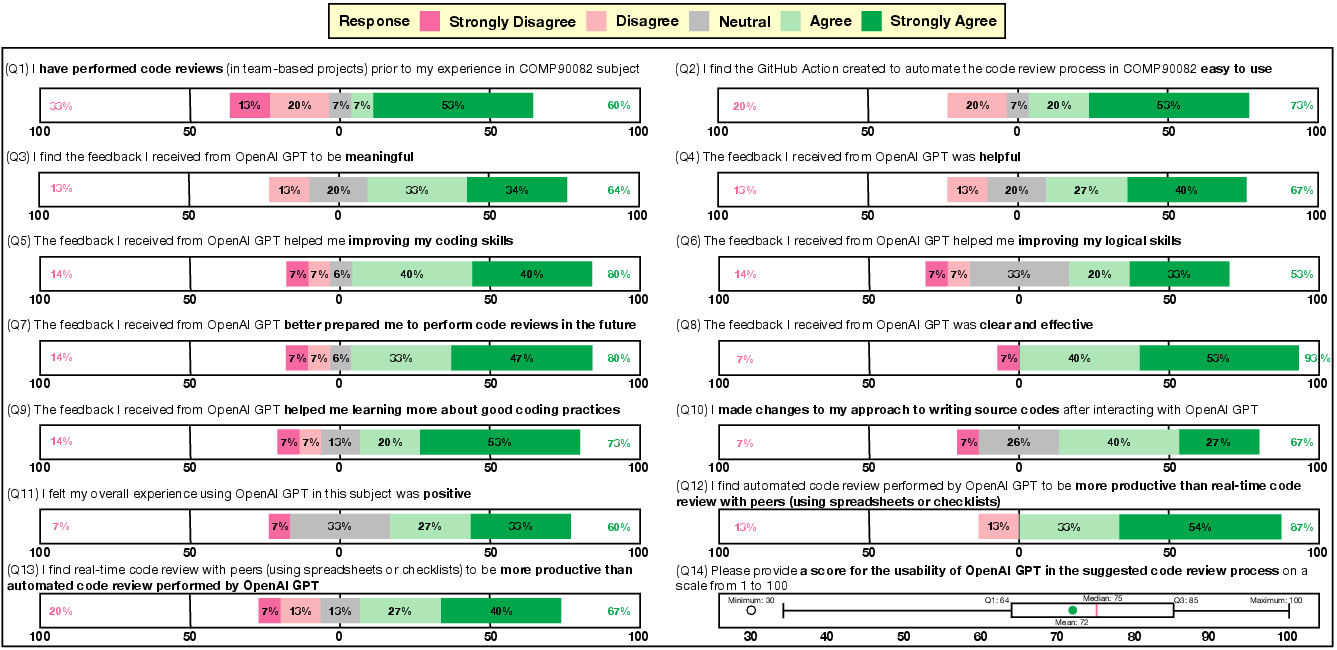
Figure 2: Distribution of survey responses mapping student perceptions of AI reviewer utility and its impact on code quality, learning, and reasoning skills.
Pedagogical and Operational Lessons
Five synthesized lessons inform future AI/education deployments:
- Align AI reviews with agile cadence: Embedding reviewer at sprint milestones triggers SRL processes at granular, authentic intervals.
- Tool–pedagogy co-design for friction reduction: Operational guardrails and formative instructional materials are necessary for scalable adoption.
- Scope control to preserve agency/prevent offloading: Human-in-the-loop design, explicit scope prompts, and feedback messaging recalibrate behaviors toward purposeful review.
- Auditable behavioral telemetry: Repository traces and structured AI outputs provide robust measures beyond self-report, enabling objective evaluation of SRL enactment.
- Frame AI as context-blind companion: Students recognize strengths (pattern, structure) and limitations (deep logic), practicing critical trust and maintaining authority over complex review decisions.
These findings indicate that AI reviewers, carefully designed and situated, enhance SRL cycles without promoting cognitive passivity or blind acceptance.
Implications and Future Directions
Theoretical implications reinforce the centrality of SRL frameworks in AI-assisted education, demonstrating that AI tools scaffold planning, monitoring, and evaluation without supplanting student agency. Practically, the experience report establishes a replicable, evidence-based deployment model for AI review in capstones and professional training.
Future directions include: designing context-aware AI reviewers capable of ingesting broader architectural information; longitudinal studies tracking SRL skill retention/transference; comparative examination of prompting strategies (e.g., Socratic AI); augmentation of the forethought phase of SRL; and systematic blending of human–AI review modalities to optimize hybrid feedback loops.
Conclusion
The deployment of LLM-based code review tools in authentic project-based education—when structured to provide critique without direct solution—effectively scaffolds code quality improvement and SRL cycles. Empirical results show stable behavioral responsiveness, tangible skill development, and critical tool engagement across cohorts. The core contribution is the demonstration that technological affordance alone is insufficient; pedagogically, agency-preserving, theory-aligned co-design is required to sustain critical thinking and lifelong learning skills in the age of AI.