- The paper introduces SHEAR, which leverages span-level Wasserstein distances between hidden states to assign fine-grained token-level credit in RLVR.
- It demonstrates robust statistical separation (Spearman’s ρ up to -0.96) between correct and incorrect reasoning spans, marking divergence points effectively.
- Empirical results on math and code benchmarks show SHEAR outperforms standard GRPO and PRM protocols with minimal computational overhead.
Span-Level Hidden State Divergence for Fine-Grained Credit Assignment in RLVR
Motivation and Problem Setting
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a leading paradigm for training LLMs on complex reasoning tasks, with Group Relative Policy Optimization (GRPO) as a foundational algorithm. In GRPO, multiple completion trajectories (rollouts) are sampled for each problem, with each receiving an outcome-level reward. The standard GRPO protocol assigns identical credits to all tokens in a rollout, making the method inherently coarse-grained and sub-optimal for tasks exhibiting long reasoning chains where sparse, localized errors can drastically alter solution correctness.
Process Reward Models (PRMs) have offered a more granular approach by assigning stepwise credit; however, they incur considerable annotation cost and are susceptible to distributional mismatch as policies evolve. This paper addresses a central open problem: can the intrinsic hidden state dynamics of autoregressive LLMs themselves provide the necessary fine-grained credit signal, using only outcome-level labels, thereby eliminating the need for auxiliary reward models or stepwise annotation?
Empirical Analysis: Hidden-State Divergence as a Credit Signal
To identify intrinsic signals correlated with local reasoning quality, the authors conduct a detailed study of span-level hidden state representations along reasoning trajectories. For each token span within a rollout, they compute the 1-Wasserstein distance between the distribution of hidden states within that span and the closest span of an opposite-labeled (correct vs. incorrect) rollout within the same group. Continuation success from each span truncation point is estimated by resampling completions, yielding a robust proxy for local reasoning quality.
Quantitative results show a strong anti-correlation (Spearman's ρ=−0.96 at the aggregate level, ρ=−0.42 at the stride-wise local level) between Wasserstein divergence and local continuation accuracy. Notably, transition zones between high and low-quality reasoning are sharply aligned with abrupt changes in Wasserstein distance.
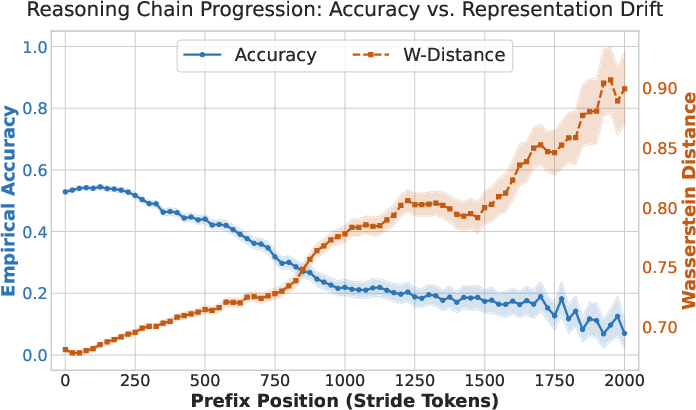
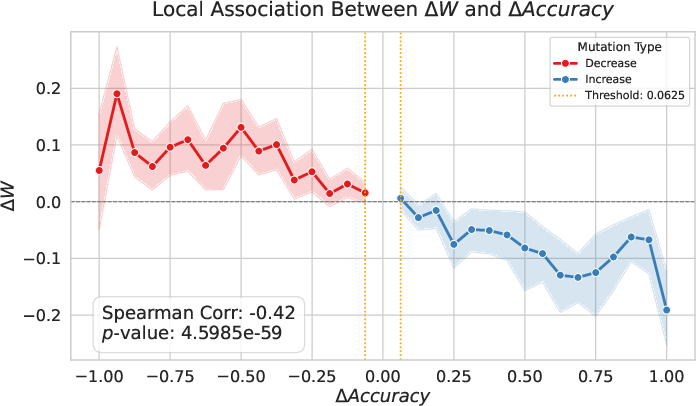
Figure 1: Aggregate trend along the reasoning chain—sharp transition zones in continuation success and Wasserstein divergence, indicating synchronous local reasoning failures.
The results empirically demonstrate that increases in span-level Wasserstein distance reliably mark divergence points in local reasoning quality, providing strong evidence that local hidden state geometry is an intrinsic indicator of reasoning reliability.
Methodology: SHEAR—Wasserstein-Weighted Advantage Rescaling
Building on this insight, the paper introduces Span-level Hidden-state Enabled Advantage Reweighting (SHEAR), a simple yet effective extension to GRPO. SHEAR partitions each rollout into overlapping spans, computes the Sinkhorn-approximated minimum Wasserstein distance for each span to the set of all opposing (correct/incorrect) spans, and assigns these distances as weights to tokens via max-pooling over the overlapping spans to which each token belongs.
These token-level weights rescale the rollout-level GRPO advantage, so that tokens where hidden states are highly divergent relative to the opposing label receive amplified credit (positive or negative, depending on correctness). Importantly, this mechanism is entirely self-supervised—no process-level annotation or external reward model is required—and involves only minimal modification to standard GRPO pipelines.
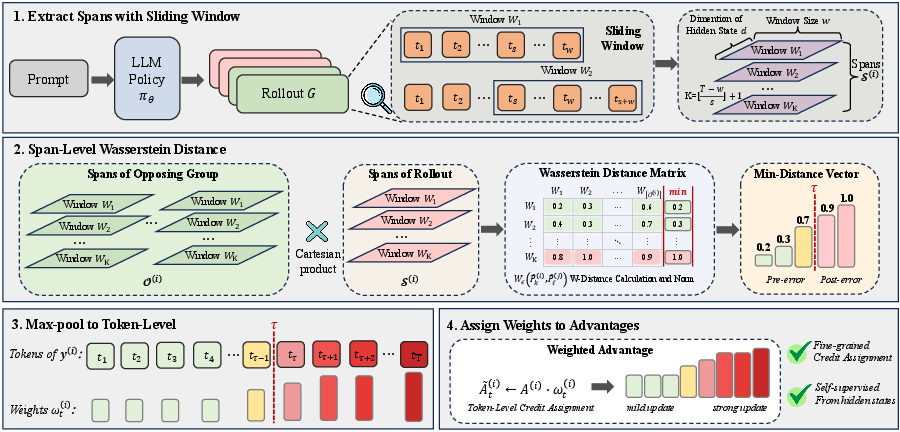
Figure 2: The overview of SHEAR—span partitioning, span-level Wasserstein distance computation, aggregation into token-level weights, and weighted policy gradient loss.
Theoretical Contributions: Separation Guarantees
The core technical underpinning is a separation theorem: under mild structural assumptions on reasoning trajectories, it is shown that Wasserstein distance between hidden-state distributions over post-divergence spans (the regions where reasoning deviates) is strictly greater than for pre-divergence spans, provided the population-level divergence exceeds the finite-sample estimation noise. This is proved for both pairwise rollout comparison and the group-minimum scenario used in SHEAR.
Empirical studies corroborate the theory: at high Wasserstein distances, the area under the ROC curve (AUC) for separating correct and incorrect spans approaches 0.97+; at low Wasserstein distances, accuracy distributions across correct/incorrect spans overlap almost completely.
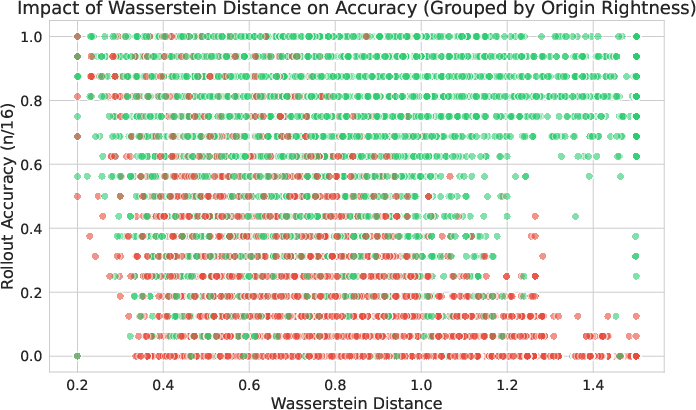
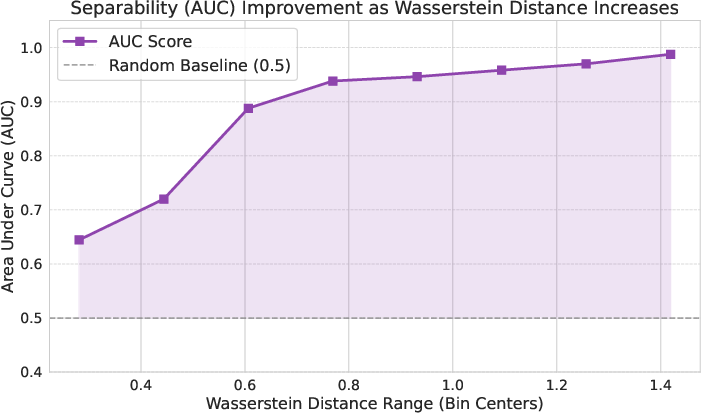
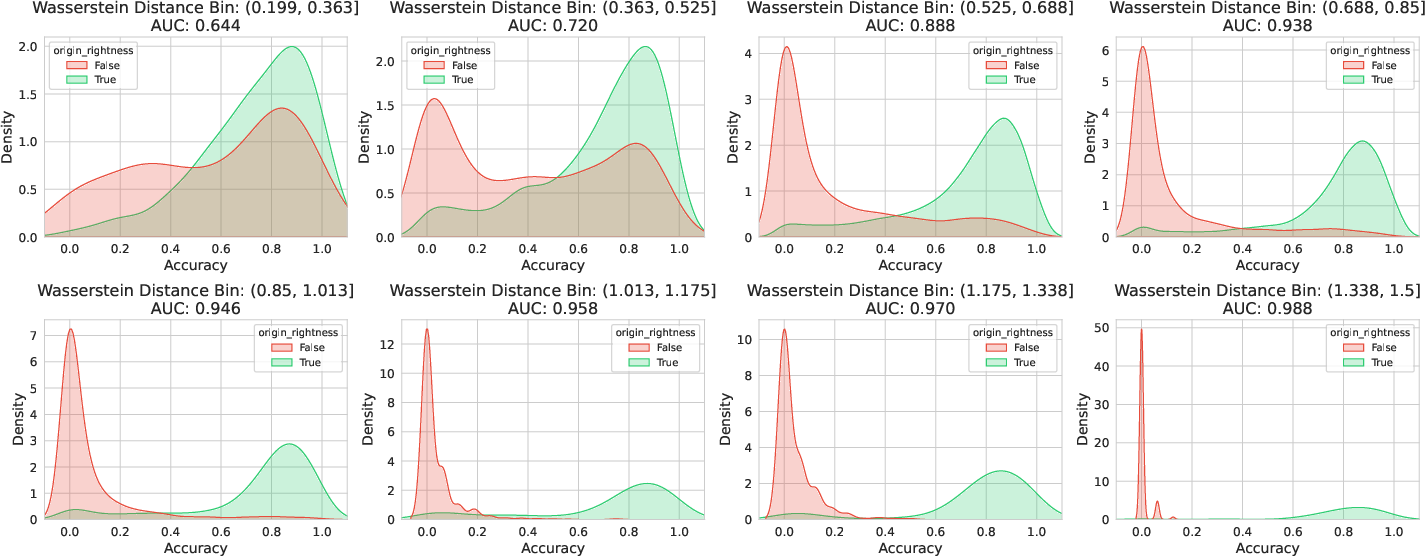
Figure 3: Empirical verification of separation theorem—accuracy stratified by Wasserstein, monotonic improvement in separability (AUC), and per-bin density plots.
Experimental Validation: Mathematical Reasoning and Code Generation
SHEAR is extensively evaluated on five difficult mathematical reasoning and five code generation benchmarks, encompassing a variety of architectures (e.g., Qwen2.5-Math-7B/14B, Llama3.1-8B-Instruct, Qwen2.5-Coder-7B). Performance is reported relative to baselines: standard GRPO, entropy-based advantage reshaping, and several PRM-based credit assignment protocols.
The numerical improvements are significant, especially on long-form mathematical reasoning tasks such as AIME24 and AMC23. SHEAR outperforms all baselines—including PRM-based methods—even though it relies exclusively on outcome-level correctness labels. Gain is especially evident on the largest models and hardest benchmarks.
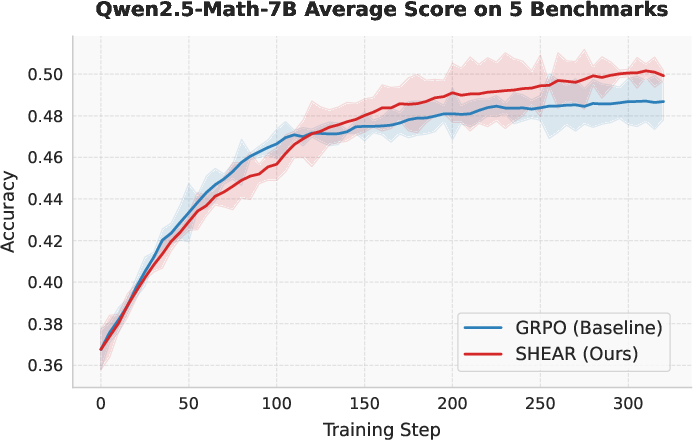
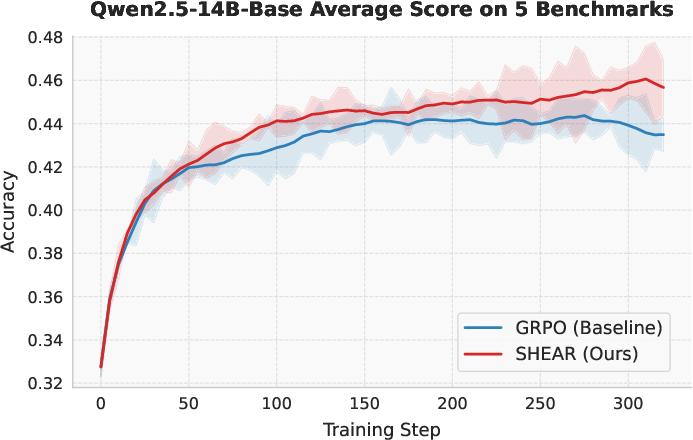
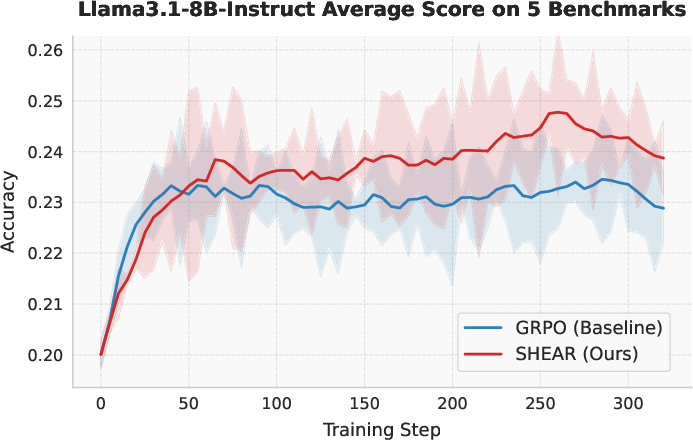
Figure 4: Training dynamics for mathematical reasoning—SHEAR accelerates progress after early training and maintains a sustained margin over GRPO.
Ablation studies show that distribution-aware metrics (e.g., Wasserstein, MMD, Chamfer) outperform mean-based metrics for credit assignment, confirming the importance of using full distributional divergence as opposed to low-order summaries. Notably, mean-only cosine metrics degrade performance relative to the GRPO baseline.
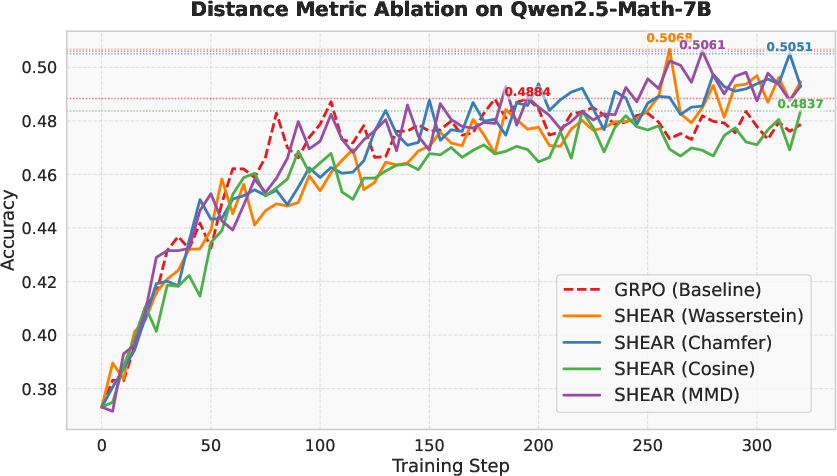
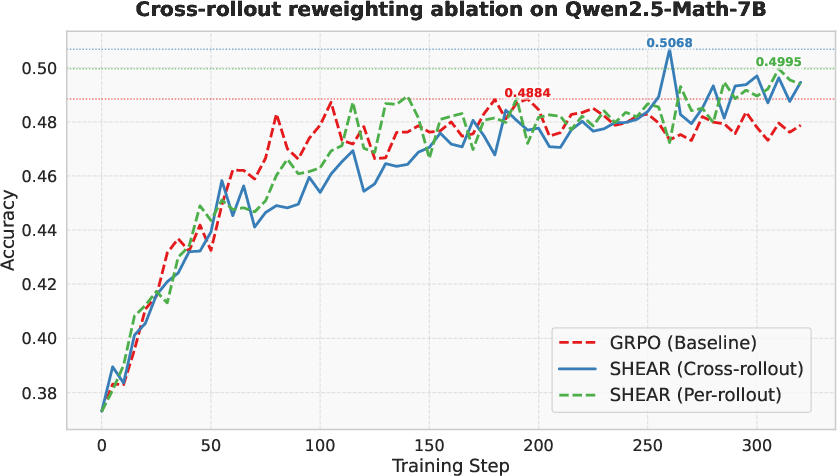
Figure 5: Distance metric ablation showing optimality of Wasserstein and similar distributional metrics for fine-grained credit assignment.
The approach is robust to span and stride hyperparameters and benefits from larger rollout group sizes, which provide more reliable contrastive sets for Wasserstein computation.
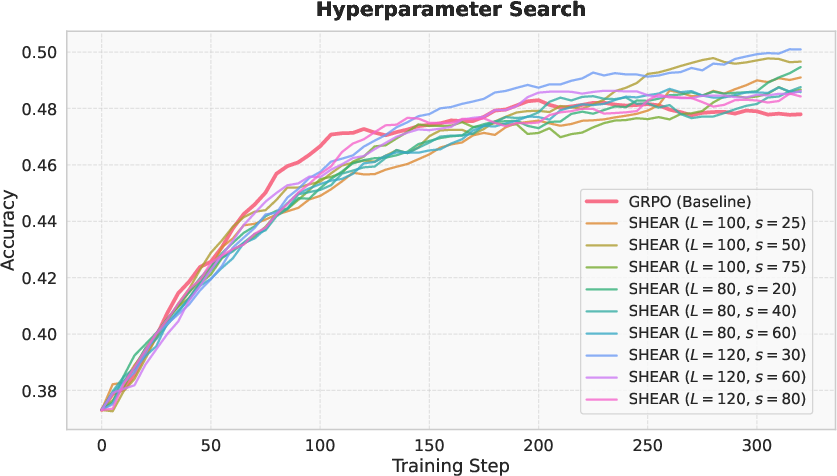
Figure 6: Average accuracy across five math benchmarks for varying span length w and stride s; accuracy improves with denser (smaller stride) coverage.
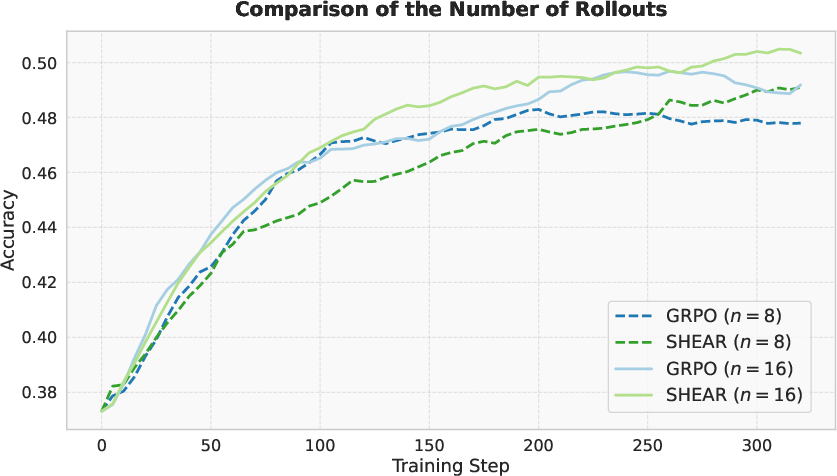
Figure 7: Larger rollout group sizes improve both GRPO and SHEAR, with a wider improvement margin for SHEAR.
On computational cost, the Sinkhorn algorithm yields less than 16% overhead across all model configurations, an acceptable tradeoff given the empirical gains.
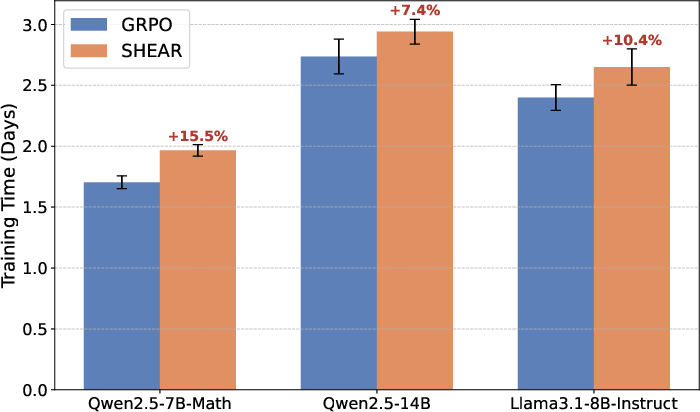
Figure 8: Training time overhead of SHEAR compared to standard GRPO; scale-up reduces overhead due to dominance of model forward/backward cost.
Implications and Future Directions
SHEAR demonstrates that the latent space geometry of contemporary LLMs contains rich, fine-grained signals regarding local reasoning quality. By extracting credit assignment signals directly from the evolving hidden state representations, SHEAR removes reliance on annotation-heavy or static process reward models and, importantly, avoids the risk of miscalibration as training progresses.
Other intrinsic signals (entropy, first-moment shifts, etc.) do not offer the same discriminative capacity. The generality of the optimal transport formalism ensures that nuanced deviations—whether mean shifts, variance, or higher-order changes—are all captured, setting SHEAR apart from alternatives.
Practically, SHEAR's design makes it highly amenable to current RLVR training infrastructures. Its competitive or superior performance to PRM-based methods—even where the latter employ dedicated 7B reward models—indicates a promising direction for scalable, annotation-free fine-grained credit assignment.
On a theoretical level, these results point to the importance of modeling credit signal emergence within the representational geometry of autoregressive LMs. Future extensions could explore more sophisticated transport metrics, the impact of non-trivial divergence structures, or broader applications (e.g., open-ended planning, theorem proving).
Conclusion
SHEAR establishes, both theoretically and empirically, that local distributional divergence in hidden-state space provides a principled, robust, and self-supervised signal for process-level credit assignment in RLVR settings with only outcome-level feedback. It achieves consistent and strong improvements over established baselines with minimal pipeline modification and manageable overhead. These findings suggest that leveraging the expressivity of LLMs' latent manifolds for intrinsic reward estimation will be an increasingly important theme in the development of general reasoning agents.
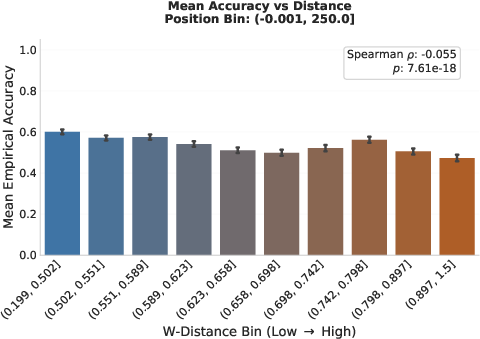
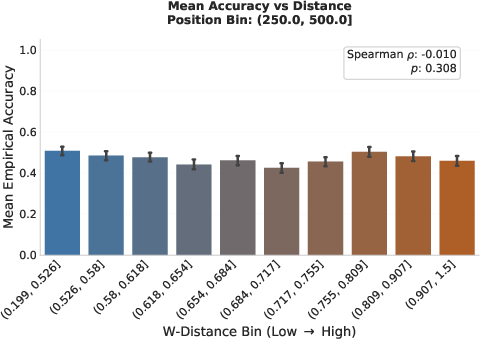
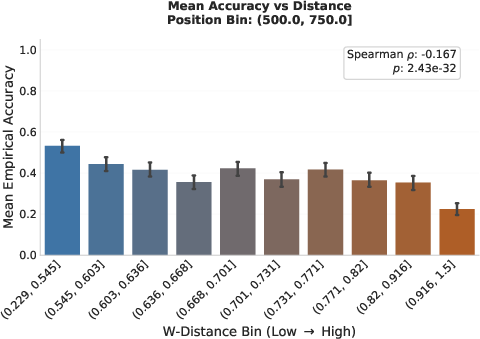
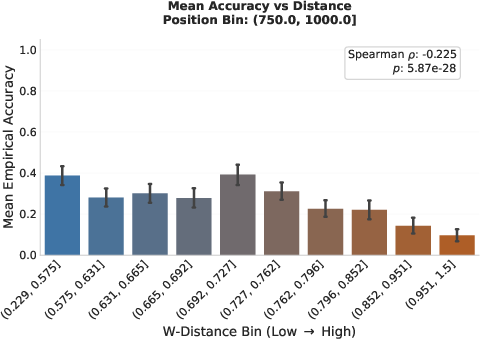
Figure 9: Wasserstein distance robustly discriminates between robust and vulnerable reasoning trajectories, with the gap widening along reasoning chains.
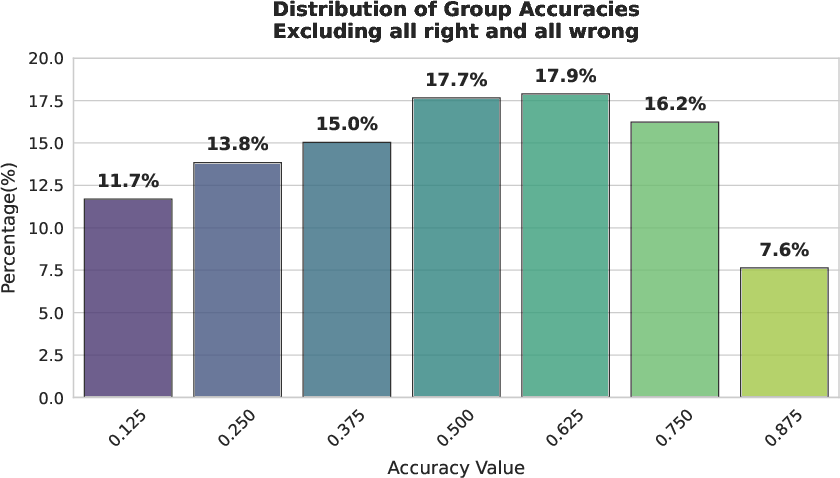
Figure 10: Distribution of group accuracies for MATH500, showing evaluation is robust across difficulty spectrum.
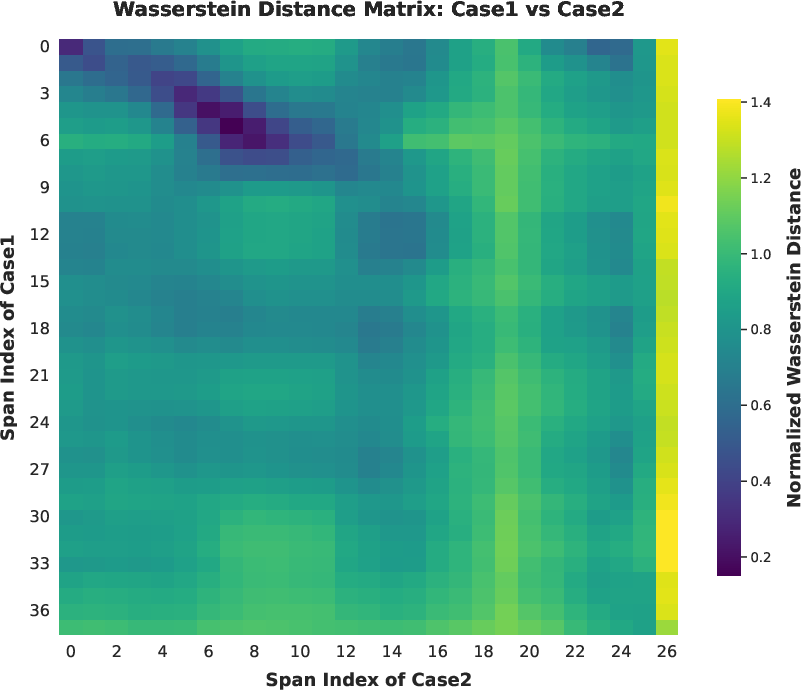
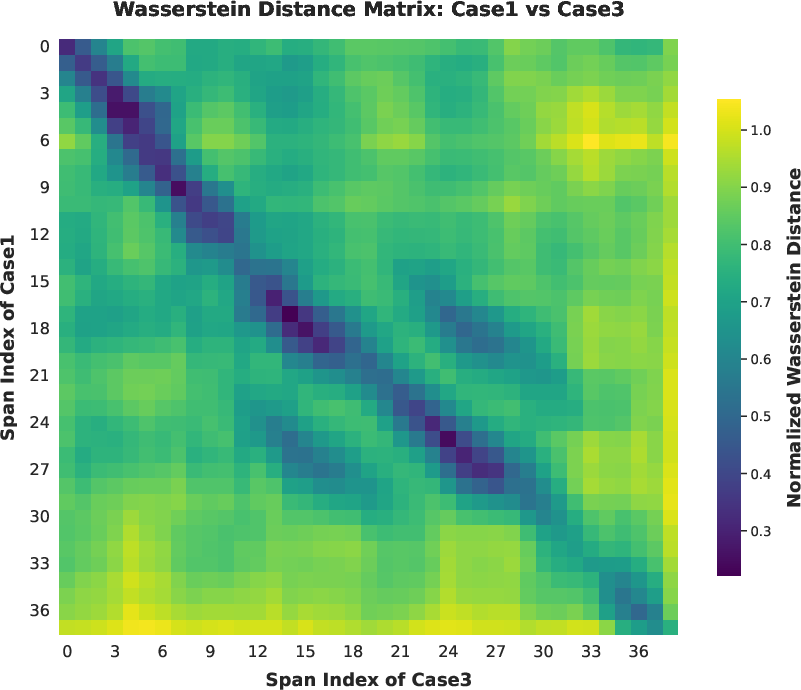
Figure 11: Span-level Wasserstein heatmaps—visualization of divergence localization between correct and incorrect trajectories.