- The paper introduces RLCM to optimize both final answer correctness and intermediate confidence calibration via process-level supervision.
- It employs a lightweight probe on intermediate reasoning steps with Monte Carlo sampling to generate reliable confidence estimates.
- Empirical results demonstrate consistent accuracy gains and reduced calibration error, enhancing risk control and aggregation across diverse benchmarks.
Process Supervision of Confidence Margin for Calibrated LLM Reasoning
Scaling test-time computation via RLVR has markedly advanced the reasoning capabilities of LLMs across domains including mathematics, code, and science. However, this performance improvement often comes at the expense of calibration: RLVR models tend to express overconfident predictions, resulting in unreliable uncertainty quantification, frequent hallucinations, and impractical confidence-based control. This is largely due to outcome-centric reward functions that optimize for final answer correctness, neglecting the alignment of confidence signals with actual correctness throughout the reasoning process.
The paper introduces RLCM (Reinforcement Learning with Confidence Margin), a process-supervision framework designed to jointly optimize correctness and confidence reliability. Rather than enforcing explicit score matching, RLCM incentivizes models to maintain a strong confidence margin between correct and incorrect intermediate reasoning states within a trajectory. Process-level calibration is delivered via a lightweight probe integrated at each reasoning step, predicting the likelihood that a truncated prefix will yield the correct answer.
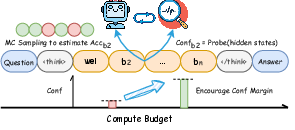
Figure 1: Overview of RLCM process supervision along intermediate compute budgets, incentivizing confidence margin between correct and incorrect states.
Methodology
Difficulty of Direct Calibration in Reasoning RL
The authors demonstrate that direct score matching rewards coupling confidence to correctness via Brier losses are brittle and at odds with reasoning optimization. Adjusting the calibration penalty weight results in inconsistent Pareto improvements along accuracy-calibration error tradeoffs, failing to yield robust gains. As a remedy, the paper proposes relative supervision: confidence ranking at the process level, maximizing the margin between more and less solvable prefixes within the same trajectory to produce a reliable calibration signal.
RLCM attaches a simple MLP probe to intermediate hidden states. Supervision is realized by forced-answer sampling on truncated reasoning prefixes—Monte Carlo completions estimate prefix answerability as soft binary targets, which the probe regresses during training. The probe remains aligned via joint updates alongside policy training, but gradients do not propagate into the main model, ensuring cheap and decoupled process supervision.
For each reasoning trajectory, the process reward is the gap between average predicted confidence across prefixes with high vs. low estimated correctness:
Rmargin(y)=∣B+(y)∣1b∈B+(y)∑Cb(y)−∣B−(y)∣1b∈B−(y)∑Cb(y)
The final reward combines outcome correctness and the margin objective:
R(y)=Rans(y)+λRmargin(y)
This design delivers dense, process-level calibration throughout reasoning rather than only at the end.
In-domain and Out-of-domain Benchmark Results
RLCM's process supervision yields a consistent accuracy-calibration tradeoff across mathematical, scientific, logical, and code reasoning benchmarks. The model matches or exceeds the strongest baseline (GRPO) in accuracy while yielding the lowest Expected Calibration Error (ECE) and Positive Calibration Error (PCE) across token budgets—outperforming alternatives such as RLCR (verbalized confidence) and C2GSPG (logit-based) both quantitatively and in expressive confidence signal breadth.
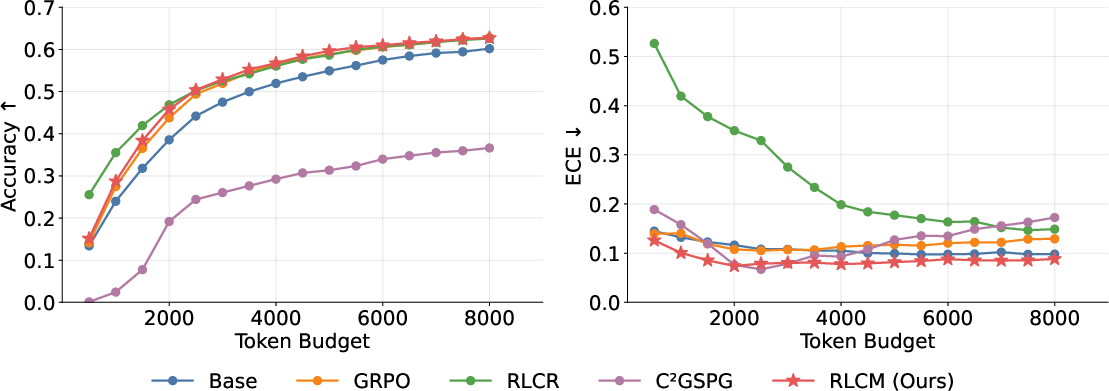
Figure 2: RLCM delivers consistently high accuracy and lowest ECE over in-domain benchmarks across token budgets.
Calibration gains generalize beyond training data: RLCM attains superior accuracy and calibration on code (LiveCodeBench), science (GPQA), and logic (LogiQA) tasks, demonstrating robust extensibility.
RLCM achieves reliable confidence estimation at every reasoning step, not just at the final output. It maintains accuracy parity with baselines throughout the computation trajectory and minimizes calibration error across intermediate token budgets. This process-level reliability is unattainable using outcome-only RL or calibration penalties applied solely at sequence end.
Epistemic Marker Analysis
Analysis of generated traces reveals that RLCM produces fewer hedging and knowledge-gap expressions than outcome-only RL models, while preserving self-correction rates, evidencing substantive calibration improvements reflected in natural reasoning content.
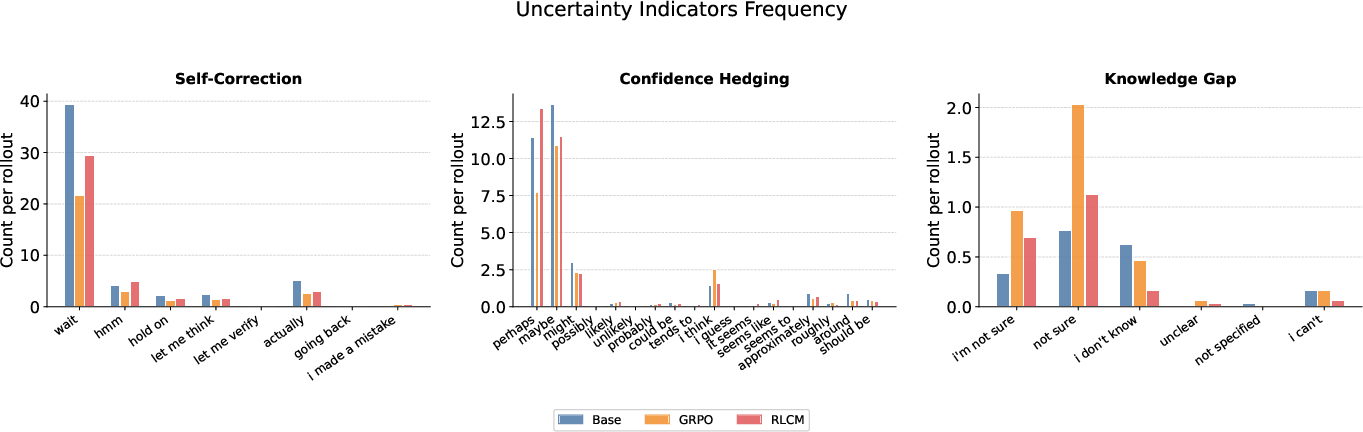
Figure 3: RLCM shows reduced hedging/knowledge-gap expressions and preserved self-correction frequency in epistemic uncertainty markers.
Application to Risk Control and Aggregation
RLCM's calibrated confidence enables efficient conformal risk control. Using Learn-Then-Test (LTT) thresholds on AMC, the model produces a smooth, calibrated target-to-realized accuracy curve, closely tracking the ideal line, and consumes fewer tokens for comparable target accuracy levels versus baseline models. The probe-based confidence is effective for continuous early-exit control and practical compute savings.
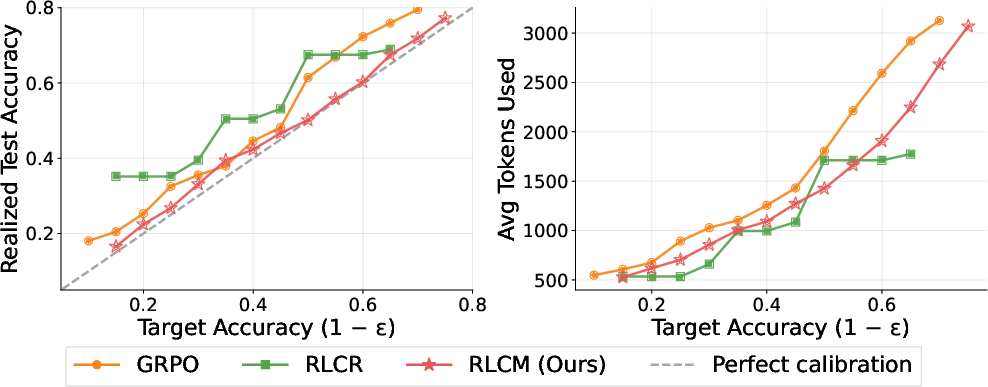
Figure 4: Smooth, calibrated accuracy curve and greater efficiency in compute usage for RLCM in risk-controlled early exit.
Confidence-weighted Aggregation
RLCM’s process supervision enables confidence-weighted aggregation to reliably outperform majority voting, with stronger alignment between confidence and answer correctness. This is consistent across benchmarks and token budgets—a marked contrast to RLCR and C2GSPG, whose confidence distributions are either highly quantized or compressed in the upper range and thus poorly suited for fine-grained aggregation.
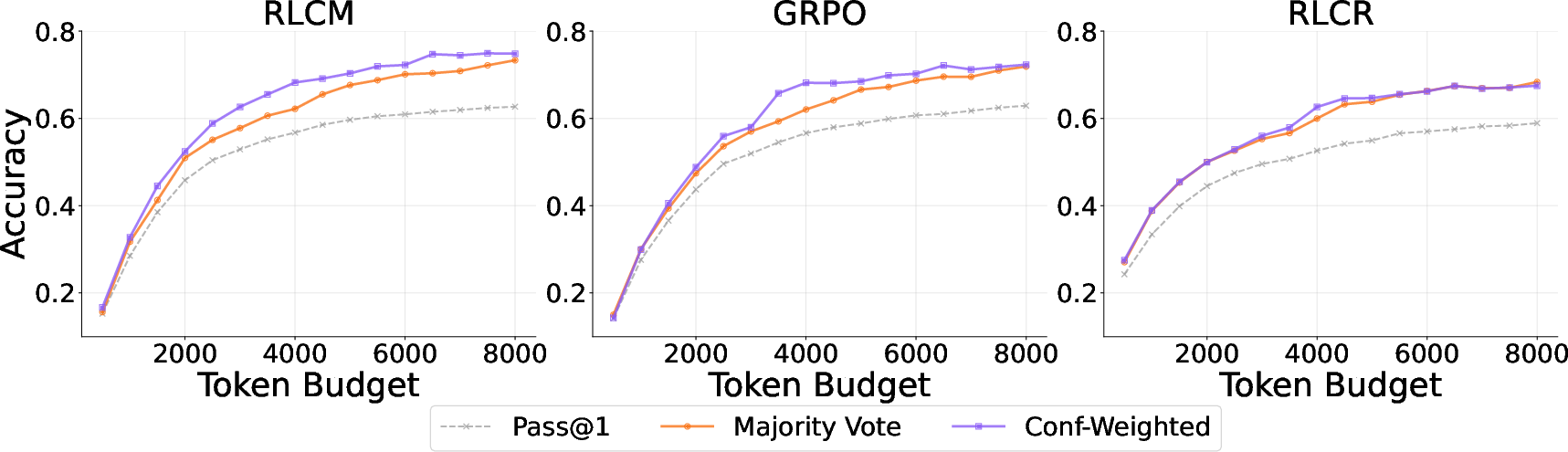
Figure 5: Confidence-weighted aggregation with RLCM outperforms GRPO and RLCR by leveraging reliably calibrated uncertainty signals.
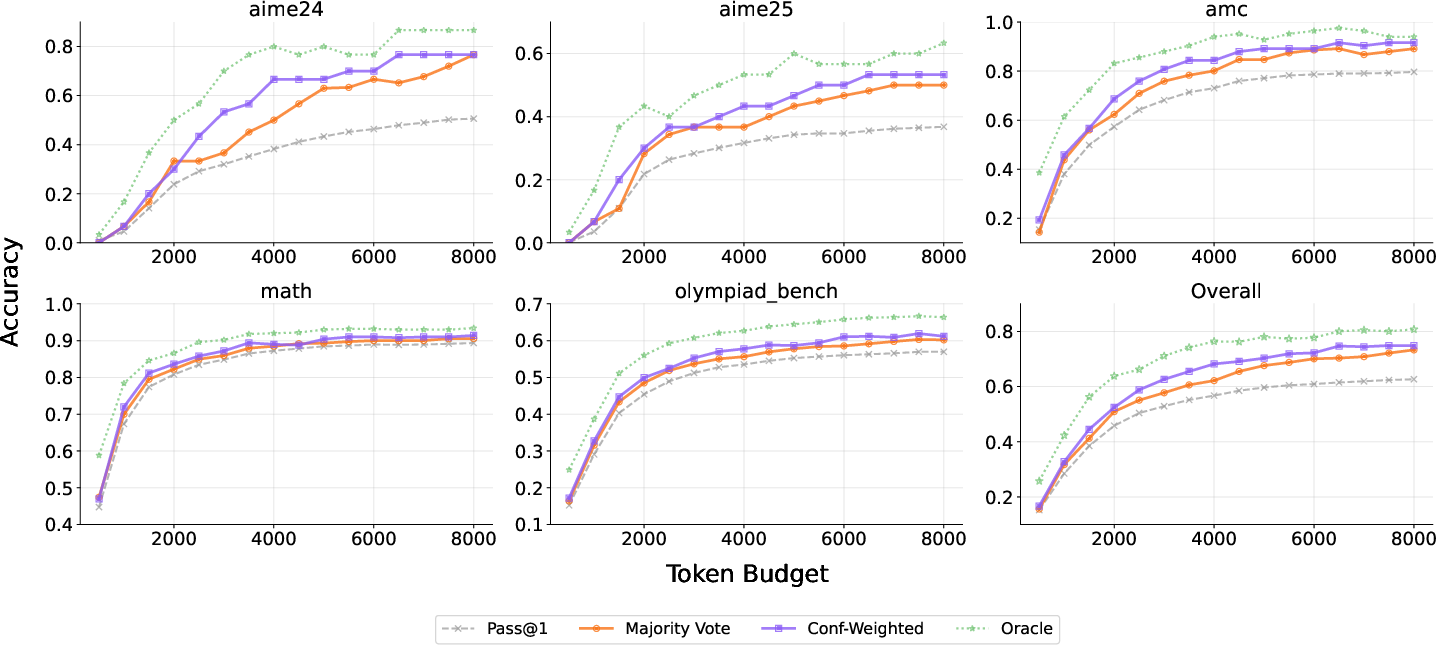
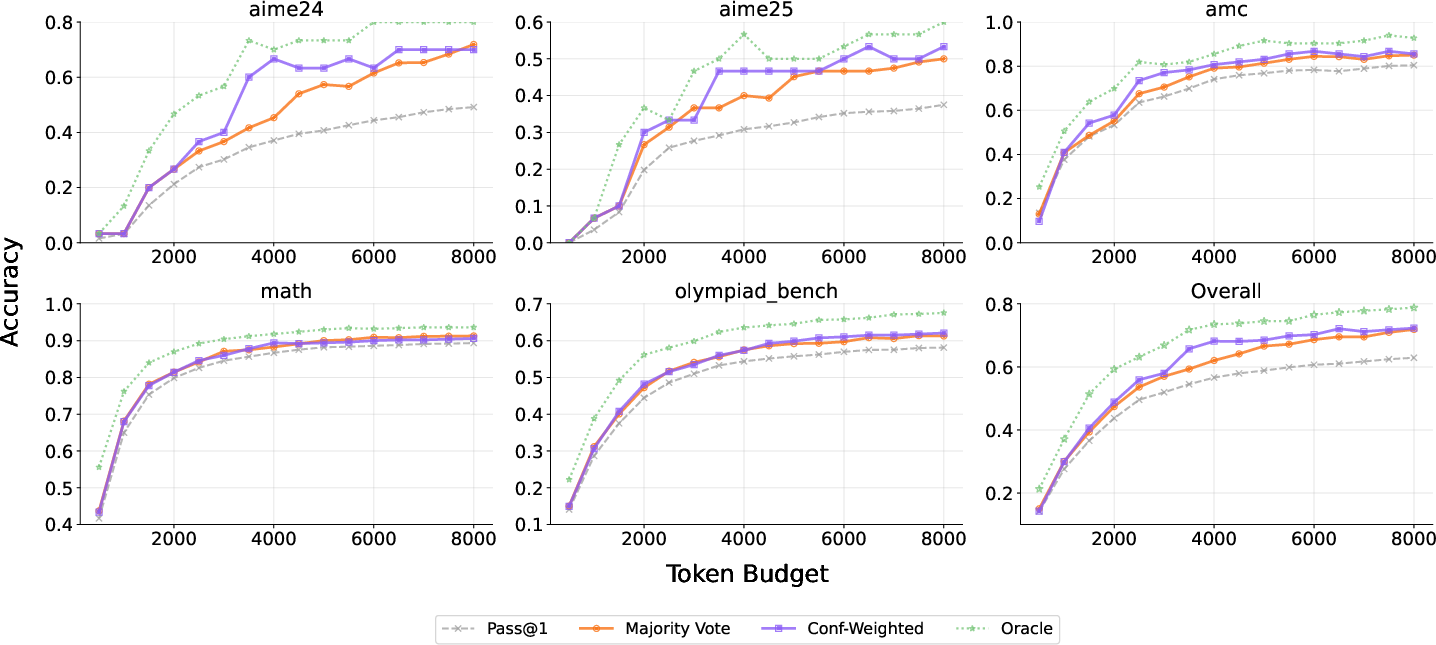
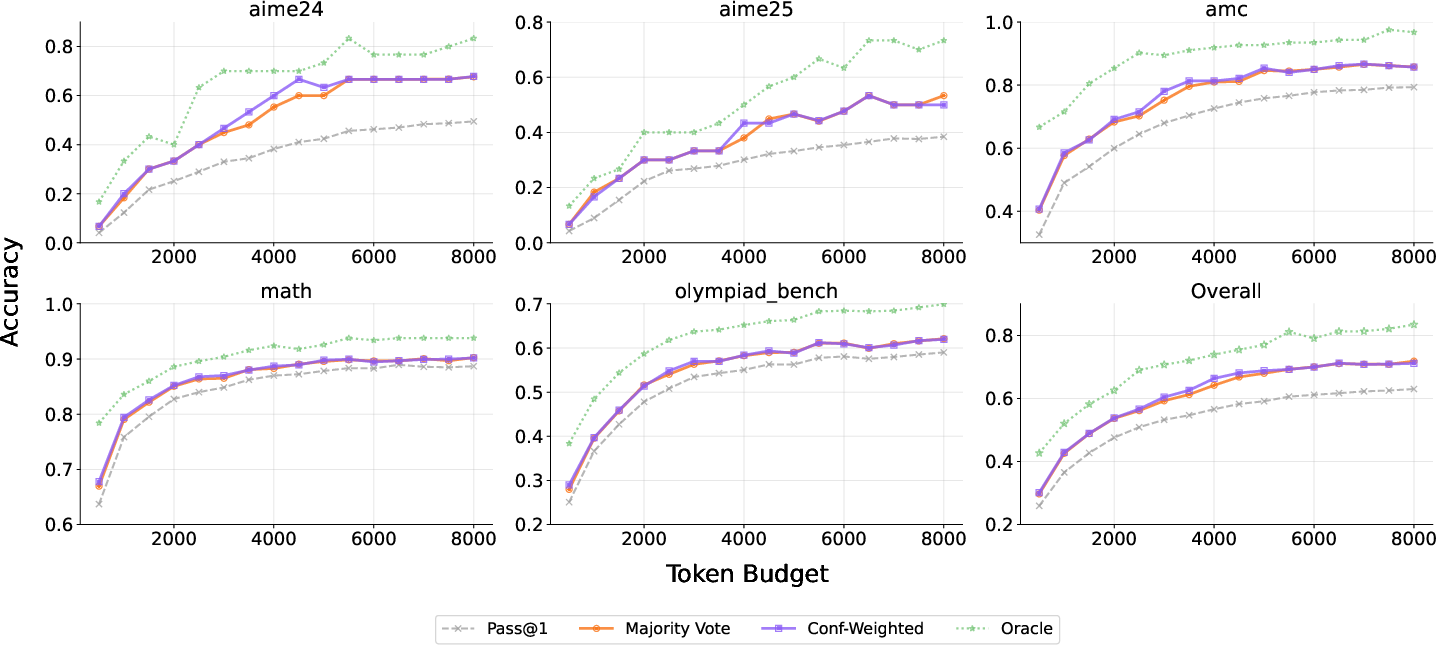
Figure 6: RLCM yields most consistent gains from confidence-weighted aggregation, demonstrating strong alignment with correctness across benchmarks.
Theoretical and Practical Implications
RLCM’s relative, margin-based supervision advances RL training for LLMs by decoupling calibration from strict score matching, elegantly harmonizing process- and outcome-level rewards. This enables robust uncertainty quantification, refined abstention, and safe deployment scenarios. Probe-based process supervision is computationally efficient compared to external model-based verification pipelines and annotation-dependent calibration, making widespread adoption plausible.
By improving calibration without degrading accuracy, RLCM challenges outcome-only RLVR approaches that often induce overconfidence and fails to guide the uncertainty signal. The broader, smoother confidence distribution observed for RLCM unlocks downstream applications including selective prediction, resource allocation, and human-AI collaboration.
Conclusion
Process-level supervision via confidence margin rewards enables LLMs to produce more reliable uncertainty estimates throughout reasoning trajectories, supporting robust calibration without sacrificing performance. RLCM delivers improved calibration and expressive confidence signals across benchmarks and reasoning domains, enhancing downstream decision processes from dynamic inference risk control to answer aggregation. The findings support margin-based process supervision as a practical strategy for training trustworthy and actionable reasoning models (2604.23333).