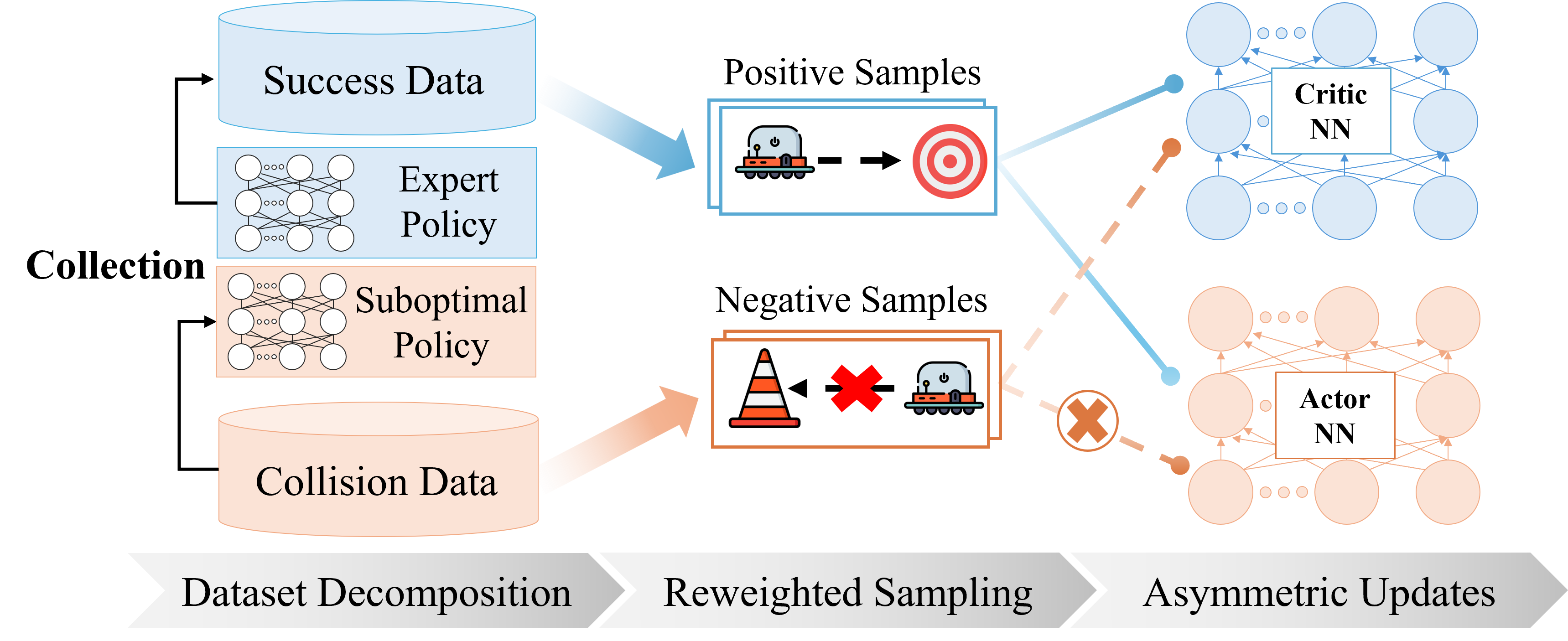
- The paper introduces a failure-aware learning framework that separates successful and collision data to improve navigation safety.
- It employs implicit Q-Learning with reweighted sampling and asymmetric updates to shape value functions using collision feedback.
- Simulation and real-world tests demonstrate a measurable reduction in collisions and improved generalization across diverse scenarios.
Failure-Aware Learning from Demonstration for Safe Robot Navigation
Introduction and Motivation
This paper addresses a fundamental limitation of learning from demonstration (LfD) in mapless robot navigation: the absence of failure awareness in standard expert datasets. Conventional LfD and imitation learning (IL) pipelines rely almost exclusively on successful trajectories, yielding policies that lack exposure to unsafe behaviors and, consequently, have poor generalization in safety-critical settings. This exposes robots to increased risk of catastrophic failures when encountering states outside the coverage of provided demonstrations. The authors propose a failure-aware learning framework that explicitly decomposes the roles of successful and failure data, enhancing navigation safety by leveraging collision experiences as negative feedback rather than as targets for direct imitation.
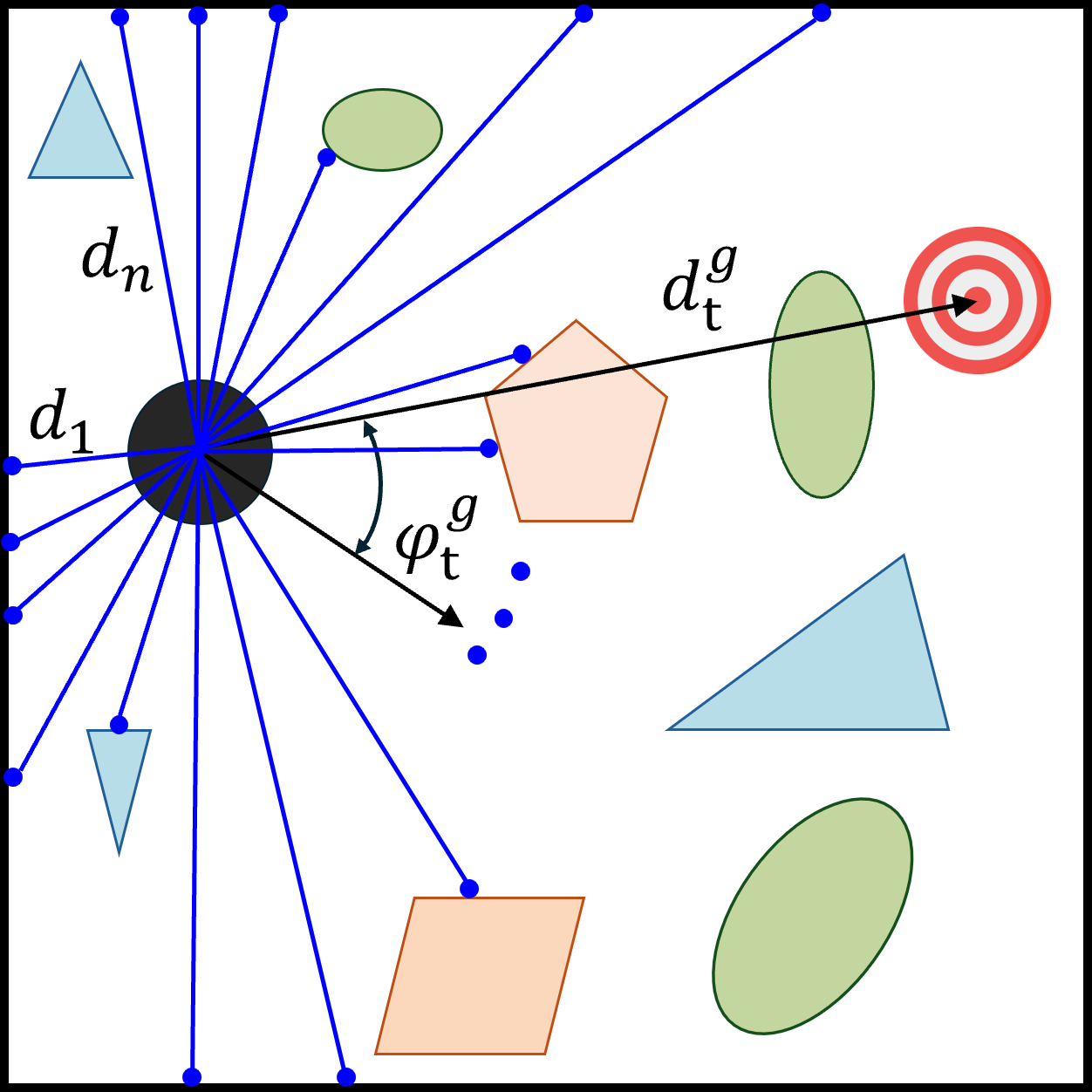
Figure 1: The mapless robot navigation problem—robot must reach a goal position in an unknown environment using local sensing and collision avoidance.
Core Framework and Algorithmic Design
The proposed approach is instantiated within an offline RL paradigm, employing Implicit Q-Learning (IQL) as the backbone. The framework introduces critical structural components:
This design follows the failure-aware learning principle, which postulates that policy supervision should only come from successful behaviors, while failures provide implicit negative reward shaping. This prevents policy degradation due to direct imitation of unsafe actions and avoids excessive conservatism.
Simulation Evaluation
Experimental evaluation in simulation leverages the ROS Stage environment, with data collection split explicitly between goal-reaching and collision episodes. The task is formulated as a Markov Decision Process (MDP), with states defined by LiDAR observations, velocities, and relative goal coordinates. The algorithmic comparison includes:
- IQL--CA: The proposed failure-aware method with structured dataset.
- IQL--DM: Original IQL trained on a naively mixed dataset.
- IQL--SO: Original IQL trained on successes only.
- BC: Behavior cloning policy from successful demonstrations.
Strong quantitative results demonstrate that IQL--CA achieves a higher success rate and consistently lower collision rate across all tested scenarios, outperforming both demonstration-only and naive data mixing approaches. In the most challenging scenario (SEnv3), the collision rate is reduced by 5.3% compared to BC. IQL--DM, which mixes collision and success transitions without structure, suffers degradation in both success and collision metrics, confirming the necessity of principled separation.
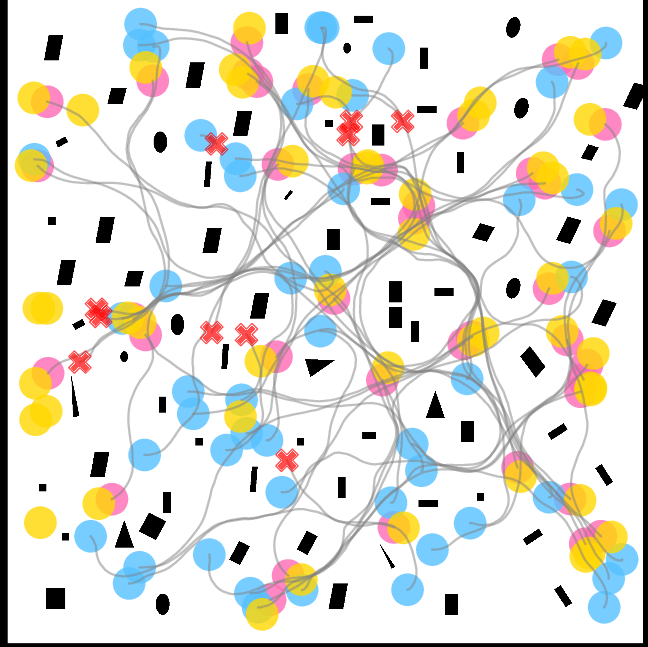
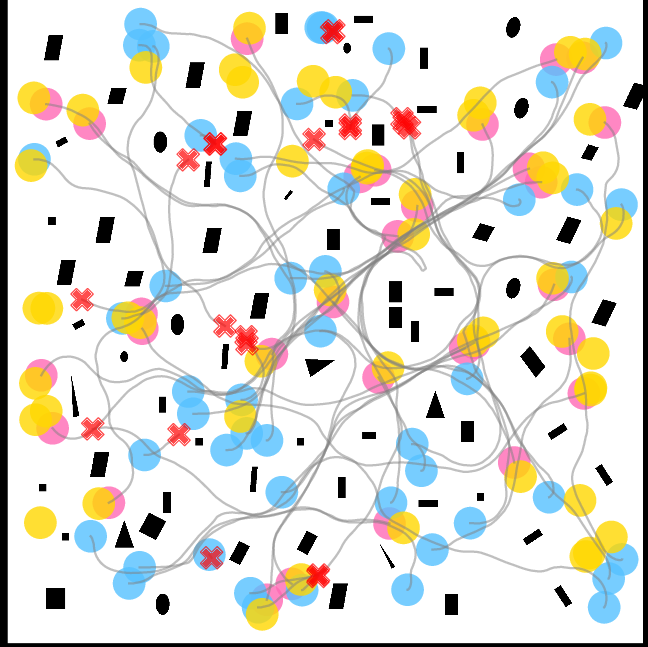
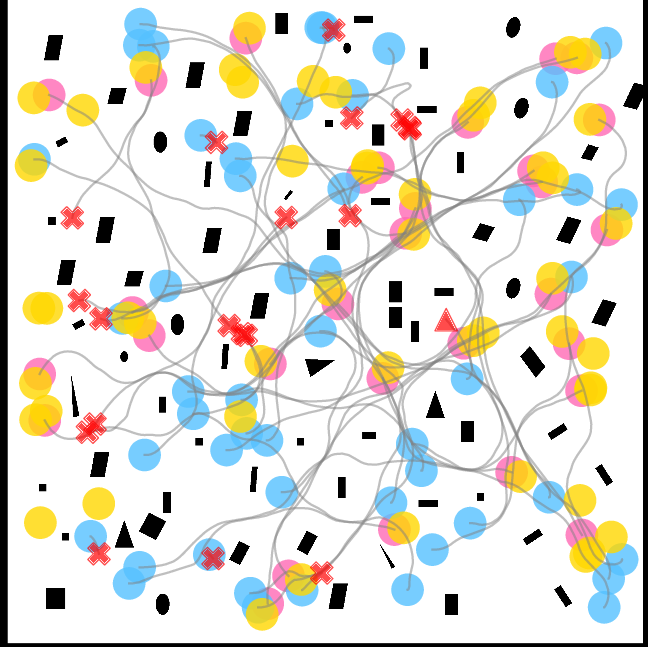
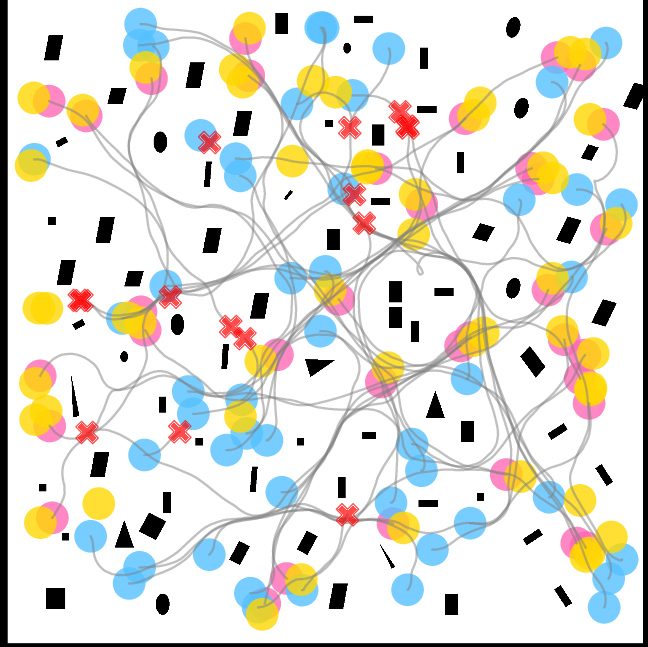
Figure 3: Trajectories of IQL--CA in SEnv3, showing fewer collisions and smoother navigation.
Real-World Validation and Generalization
The method’s robustness is substantiated through real-world experiments using Turtlebot2 and Unitree Go2 platforms. Notably, the navigation policy is trained entirely in simulation and deployed in previously unseen environments, confirming its generalization capability. The experiments include static and dynamic scenarios, such as avoiding unexpected pedestrian appearances.
Across diverse office and daily-life environments, IQL--CA controllers demonstrate reliable goal-reaching and avoidance, as visualized across multiple setups. Other methods, including BC and IQL--SO, exhibit collisions or become trapped, underscoring the value of failure-aware value shaping.












Figure 4: IQL--CA trajectories in REnv1, with successful and safe navigation through real-world clutter.





Figure 5: IQL--CA navigation in REnv5 with Unitree Go2, showing robust performance across platforms.
Practical and Theoretical Implications
The findings establish that collision experiences are an effective source of implicit supervision for safe robot navigation, provided their utilization respects the asymmetry between positive and negative transitions. The framework advances offline RL application in safety-sensitive domains by preventing degradation and conservatism that arises from naive failure data integration. The structured approach enhances generalization across environments and hardware, suggesting applicability in broader robotics and autonomous systems.
Future research directions include scaling the framework to complex navigation tasks with richer sensory inputs, integrating trajectory-level negative supervision, and studying the efficacy in other outcome-driven offline RL frameworks [jiang2026beyond]. Comparative studies with trajectory classification-based safety RL [gong2025offline] may further refine failure-aware paradigms.
Conclusion
This paper identifies and addresses a critical limitation of classic LfD for robot navigation—the lack of failure awareness. By explicitly decomposing the roles of successful and failure data and structuring their influence within offline RL, the method achieves significant improvements in navigation safety and maintains high task performance. The results underscore the importance of principled, asymmetric utilization of collision data, establishing a clear pathway for future safe RL applications in real-world settings.
(2604.23360)