- The paper introduces MTRouter as a framework that uses history–model joint embeddings to adaptively select LLMs for each turn, balancing performance with cost efficiency.
- It employs an outcome estimator trained with episode-level supervision to predict final outcomes and minimize unnecessary model switches, resulting in significant cost reductions.
- Experimental results on benchmarks like ScienceWorld and HLE demonstrate notable improvements in accuracy and cost savings compared to static and reactive routing baselines.
MTRouter: Cost-Aware Multi-Turn LLM Routing via History-Model Joint Embeddings
Introduction and Motivation
The increasing application of LLMs to complex, long-horizon agentic tasks, such as scientific simulations and open-ended problem-solving, fundamentally challenges practical deployment due to excessive inference costs accrued over many sequential model calls. The cost disparity between high-performing frontier models and cost-effective yet weaker LLMs is substantial, requiring a principled approach for adaptive model selection across multi-turn episodes. The MTRouter framework addresses this need by introducing cost-aware, turn-level routing based on history–model joint embeddings, and learning to optimize the performance-cost trade-off in long-horizon agentic workflows.
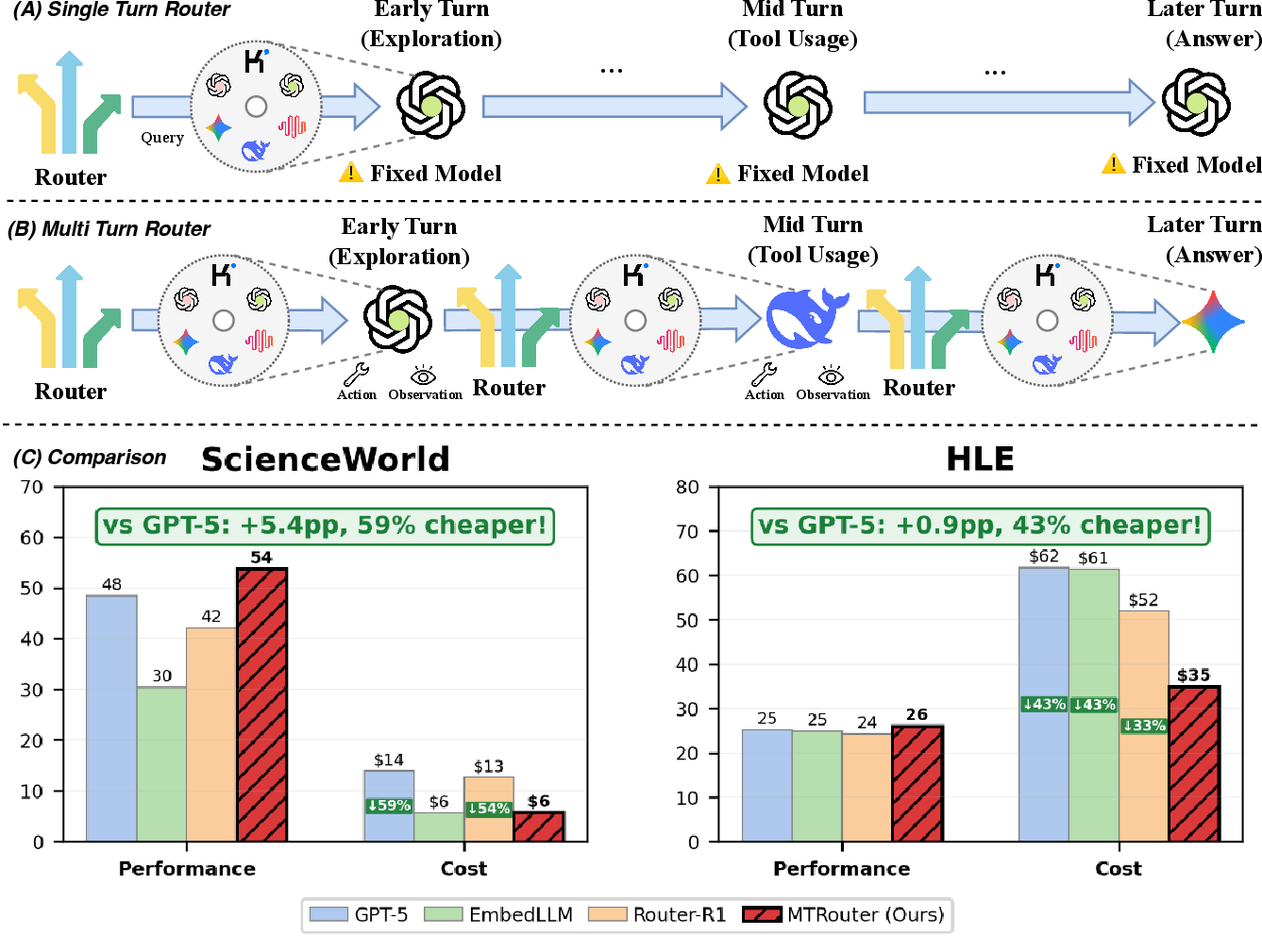
Figure 1: Routing strategies: single-turn keeps a fixed model; multi-turn allows model adaptation; MTRouter delivers better performance–cost trade-off than baselines on ScienceWorld.
Methodology: History–Model Joint Embeddings and Outcome Estimation
The core task is to select, at each interaction turn of a multi-step episode, which LLM from a candidate pool to invoke, respecting a strict cost budget while maximizing terminal task outcome. Unlike static routing decisions, MTRouter’s per-turn adaptivity accounts for dynamic interaction histories and evolving task demands.
Representation and Architecture
Both interaction history and candidate model characteristics are independently embedded:
- The historical context utilizes a frozen language encoder, producing a dense vector summarizing the evolving state and task-relevant progress.
- Candidate models are characterized via structured metadata (including context size, pricing, and knowledge cutoff) concatenated with a learned residual embedding.
These are joined to create history–model representations, serving as input to a feed-forward outcome estimator (MLP) that predicts the expected final outcome for each model–history pair.
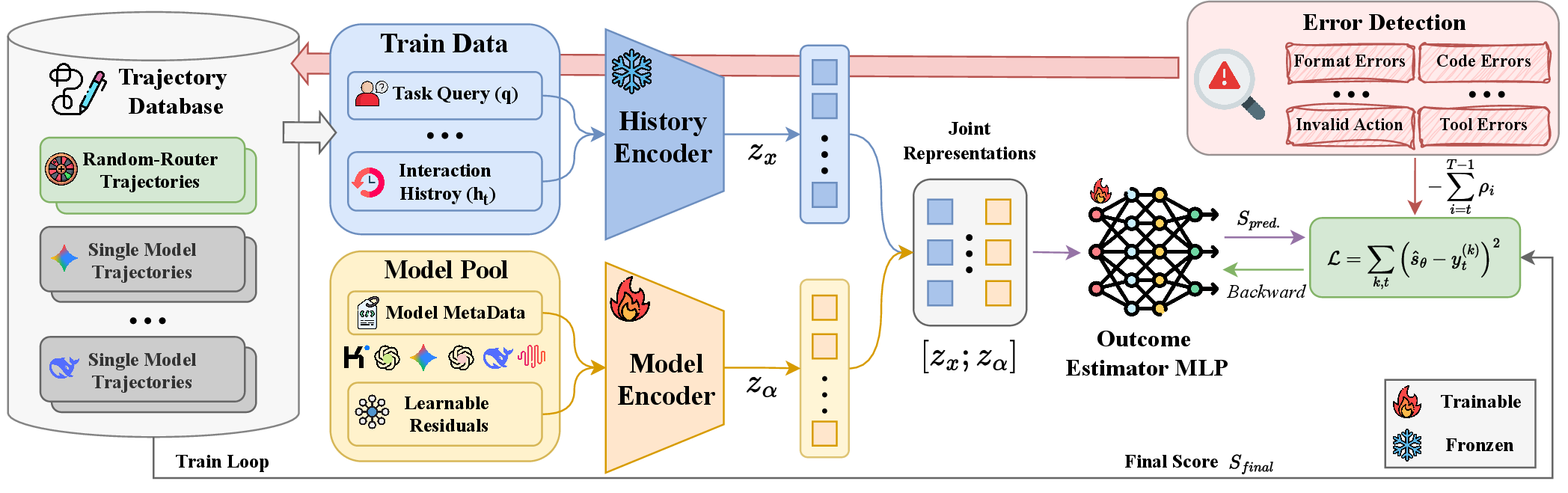
Figure 2: Schematic overview of MTRouter: history and model encoders yield joint embeddings, which inform the outcome estimator used for adaptive per-turn model selection.
Supervision and Learning Objective
Supervision is provided exclusively by episode-level outcomes, penalized for turn-local errors via a monotonic penalty schedule that weights errors increasingly as the episode progresses. This objective guides the learning of an outcome estimator capable of mapping (history, model) pairs to expected episode performance, enabling the router to select the model expected to yield the best terminal outcome at each turn.
Experimental Results and Empirical Analysis
Benchmarks and Model Pool
Evaluation on ScienceWorld and Humanity’s Last Exam (HLE) benchmarks, both in-distribution and out-of-distribution, establishes a strong testbed for agentic workflows involving tool use, long-context reasoning, and error-prone action sequences. The candidate model pool spans six LLMs, covering a 20× price differential and varying context lengths.
MTRouter demonstrates dominant performance–cost trade-offs compared to both single-model and sequential/episode-level routing baselines:
- On ScienceWorld, average score improves from 48.4 (GPT-5 baseline) to 53.8, with a cost reduction of 58.7%.
- On HLE, MTRouter achieves comparable or better accuracy with 43.4% less cost than the best-performing single-model baseline.
- These gains are resilient to distribution shift, persisting under out-of-distribution task splits.
Diagnostic Analyses
- Switching Efficiency: Contrary to naive expectations, performance gains are not explained by more frequent model switches. MTRouter achieves better outcomes while requiring substantially fewer switches compared to prior multi-turn routing (e.g., Router-R1).
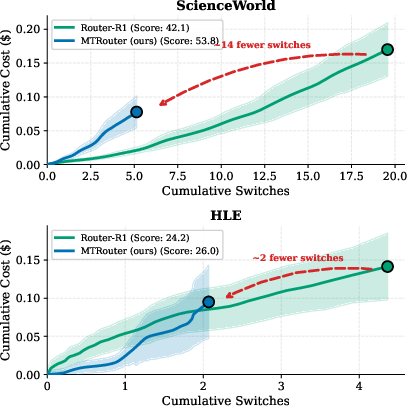
Figure 3: MTRouter attains successful episodes with lower cost and fewer model switches relative to Router-R1 on both ScienceWorld and HLE.
- Resilience to Errors: Upon encountering errors (format/invalid actions), MTRouter is less reactive, switching models less frequently after failure but achieving higher subsequent recovery rates, indicating a learned error tolerance strategy.
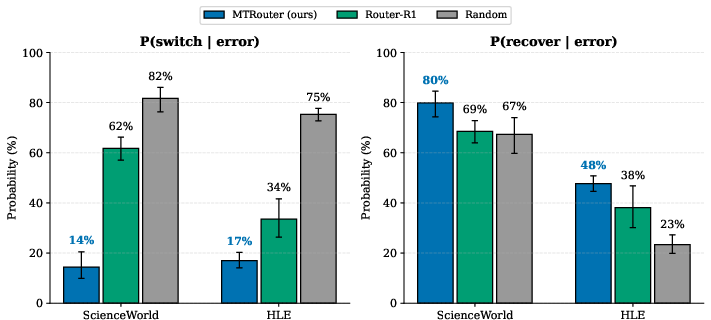
Figure 4: Post-error model-switch probability (left) and subsequent recovery rate (right): MTRouter opts for stability and achieves greater recovery than Router-R1.
- Structured Model Utilization: Usage of individual models evolves throughout the episode: MTRouter exhibits phase-aware routing and avoids uniform or random model allocation.
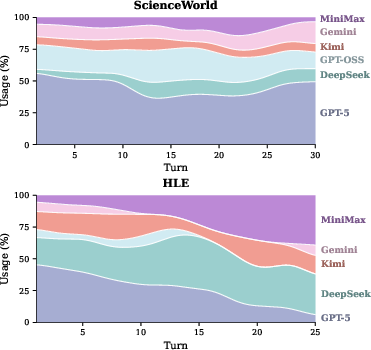
Figure 5: By turn position, MTRouter employs models in a structured, benchmark-dependent manner, e.g., early reliance on high-capability models with shifts to lighter models when appropriate.
- Emergent Specialization: Measured via lift statistics, MTRouter assigns models specialized roles across tools/actions. For instance, in HLE, DeepSeek is predominant for web search, while GPT-5 is specialized for code execution.
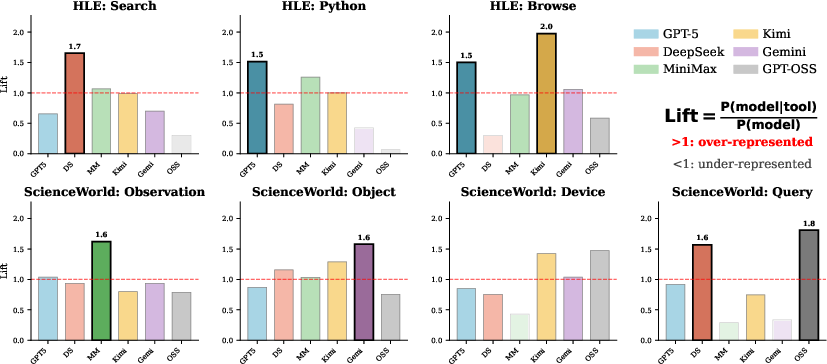
Figure 6: Tool/action specialization: models are over-represented for certain actions, reflecting emergent division of labor aligned with their capabilities and cost structure.
- Embedding Structure: Visualizing learned model embeddings (Figure 7) reveals clear separation by model and cost-tier, confirming that the architecture internalizes capability–cost distinctions not explicitly encoded in metadata.
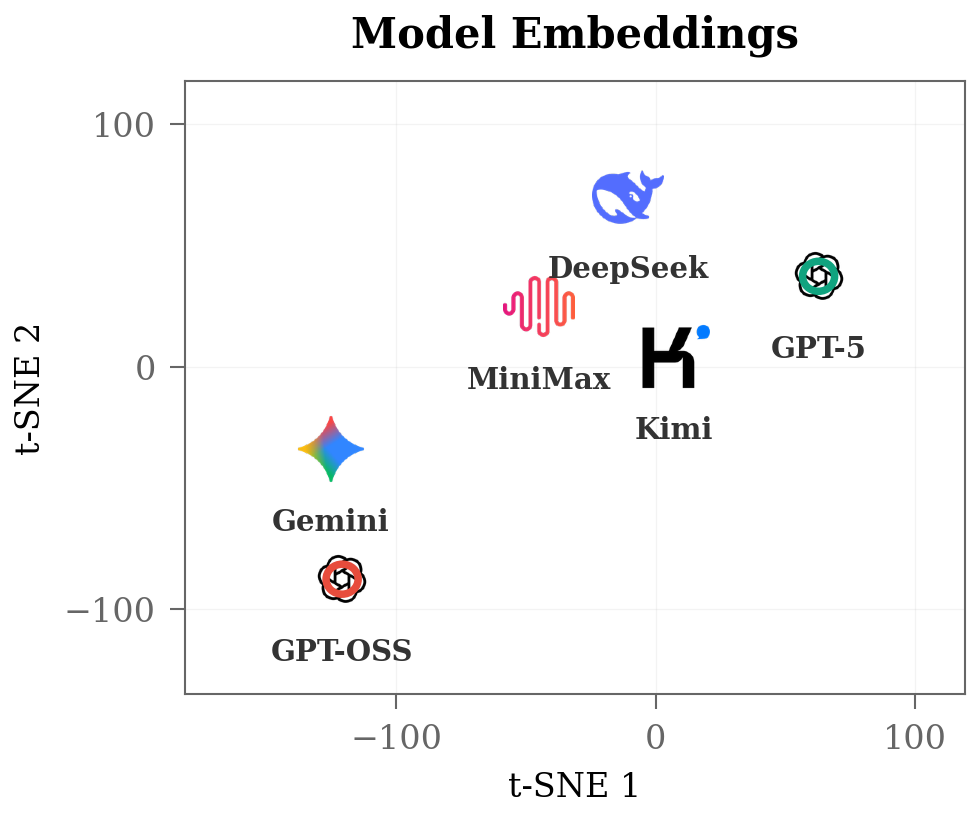
Figure 7: t-SNE visualization of model encodings: distinct clusters align with model identity and cost tier.
- Commercial Baseline Comparison: By contrast, a production router (OpenRouter) often underestimates domain difficulty (e.g., ScienceWorld), over-utilizing lightweight models and underperforming drastically compared to MTRouter—demonstrating the necessity of task- and interaction-aware routing.
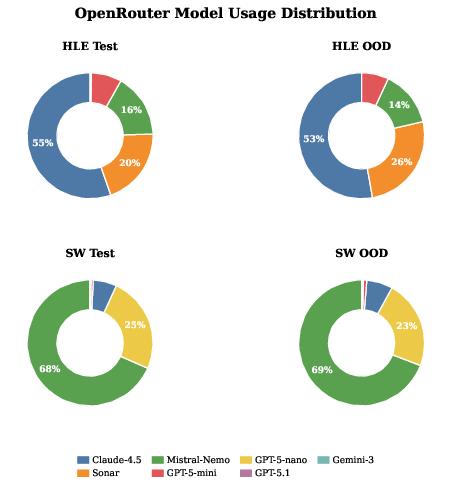
Figure 8: OpenRouter model usage: on ScienceWorld, over-reliance on lightweight models results in negative scores, highlighting inadequate generic routing.
Ablation and Robustness
Ablation studies reveal the contribution of individual architectural choices:
- Removing random-router data, error penalties, or the history encoder substantially degrades performance,
- Substituting the learned model encoder with hardcoded features, or replacing the non-linear regressor with simpler alternatives, eliminates much of the gain,
- Cost/accuracy improvements persist with changes in history token budget, candidate pool size, and budget constraints, demonstrating robustness.
Implications and Future Directions
MTRouter’s approach highlights the efficacy of outcome-driven, history–model joint representations for adaptive, resource-efficient LLM orchestration in multi-turn settings. Practically, such routers can lower operational costs and latency for LLM-powered agents and enable the scaling of agentic researchers and tool-users to larger tasks and longer horizons.
The paper’s demonstration that success does not entail indiscriminate switching, but rather emergent, strategy-driven specialization, suggests that agentic routing is best cast as an offline learning problem with explicit outcome penalties. This insight is aligned with recent trends emphasizing offline RL and counterfactual estimators for high-cost domains.
Limitations remain surrounding the scalability of trajectory collection, lack of online adaptation (i.e., RL-based updates in-the-loop), and prompt cache invalidation due to switching. Addressing these—e.g., with simulated data generation or hybrid offline–online protocols—represents an important direction for open-ended, cost-sensitive LLM orchestration.
Conclusion
MTRouter advances the state of LLM routing for multi-turn, cost-sensitive agentic applications by leveraging learned history–model outcome estimators, delivering empirically superior performance–cost balances compared to both static and reactive commercial baselines. This result underscores the importance of joint context and model conditioning, as well as explicit outcome supervision, for scalable agentic LLM infrastructure. Future work in cost-aware model orchestration is likely to benefit from further developments in offline learning and fine-grained trajectory supervision.

