- The paper presents DataPRM, a novel process-level reward model that improves agentic data analysis by differentiating exploratory steps from errors.
- It utilizes a generative, environment-interactive verifier with a ternary reward scheme that credits correct, correctable, and failed steps to maintain robust agent performance.
- Empirical results show significant performance improvements on benchmarks like ScienceAgentBench and DABStep, validating DataPRM’s efficiency even with a compact model size.
Process-Level Reward Modeling for Agentic Data Analysis: An Expert Perspective on DataPRM
Introduction and Motivation
Automated data analysis via LLM agents is advancing rapidly, yet existing RL and search supervision paradigms remain outcome-centric, insufficiently constraining agent decision sequences within complex, partially observable analytic environments. Prior Process Reward Models (PRMs), while boosting stepwise reasoning reliability in mathematical or code-generation scenarios, fail to translate effectively to open-ended, interactive data analysis. Specifically, in data-analytic agent settings, PRMs misclassify essential exploratory steps as errors (inhibiting adaptation) and cannot detect silent logical faults masked by successful code execution. This work provides an empirical dissection of these domain limitations, then introduces DataPRM, an environment-aware generative PRM integrating active verification and a nuanced ternary reward schema.
The key architectural innovation is an agent–verifier pipeline enabling step-level, process-centric reward supervision (Figure 1).
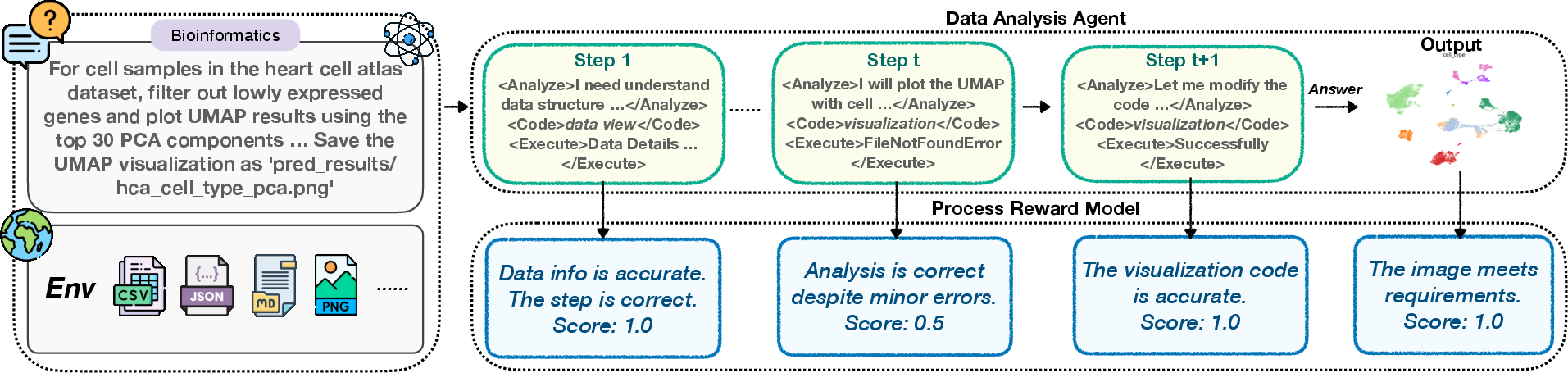
Figure 1: Illustration of the agent–PRM collaborative pipeline. The PRM operates as an interactive supervisor alongside the data analysis agent.
Failure Modes of Standard PRMs for Data Analysis Agents
Comprehensive ablation reveals general-domain PRMs have limited discriminative capacity for supervising analytic agent workflows. As shown in Figure 2, their verification signal lags even ensemble heuristics like majority voting. Critically, the study identifies two orthogonal failure modes:
- Silent Errors: Logical flaws undetectable via code exceptions, leading to incorrect results but passing traditional static or step-verifiers.
- Grounding Errors: Symptoms of schema mismatches or missing environmental priors, often necessary for adapting agent perception, but erroneously adjudicated as fatal errors by generic PRMs.
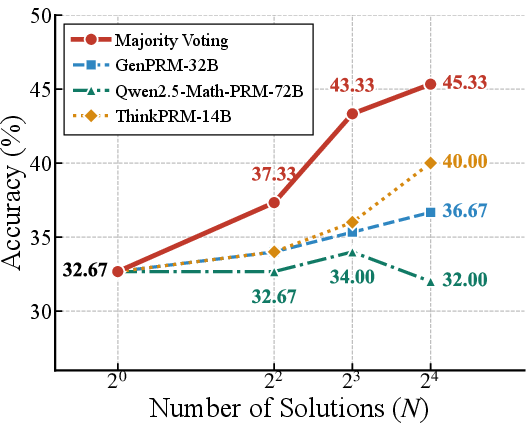
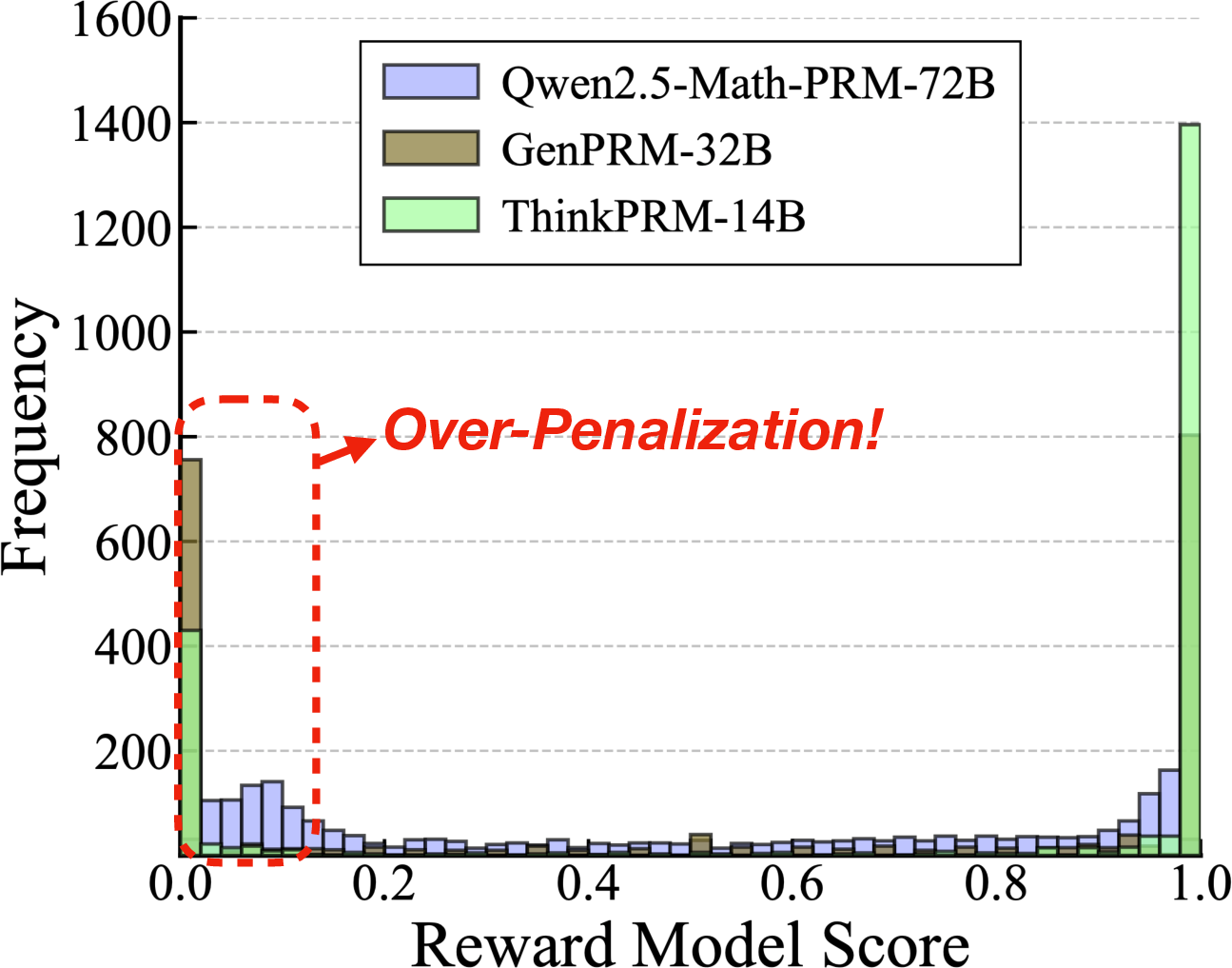
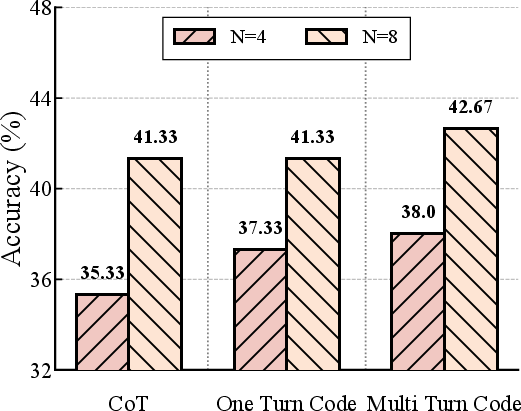
Figure 2: Parity and inferior performance of general PRMs on analytic reasoning, failing to outperform simple ensembling strategies.
This empirical insight is formalized by Bayesian modeling (Appendix): classical PRMs hallucinate unseen context due to POMDP uncertainty, misrewarding both exploratory and falsely successful steps.
The DataPRM Framework
Generative Environment-Interactive Verification
DataPRM adopts a generative, multi-turn ReAct-style verifier, symmetrically parameterized to the agent itself, and autonomously interacts with the analytic environment (file, interpreter, toolset access). This loop incrementally accumulates evidence, reducing estimation variance in the latent environment state. Tool usage (e.g., document/image queries) is fully integrated to support multimodal and long-context behaviors, making the verifier robust against complex data modalities and external references.
Reflection-Aware Ternary Reward
Crucially, DataPRM introduces a step-level ternary reward: strictly correct (1.0), correctable error (0.5), irrecoverable failure (0.0). The 0.5 state credits steps that reveal information/generate feedback, operationalizing an information-gain perspective and preventing search/learning collapse during necessary exploration. This reward structure is essential for RL or search settings, maintaining agent entropy and dense reward even in high-uncertainty regimes.
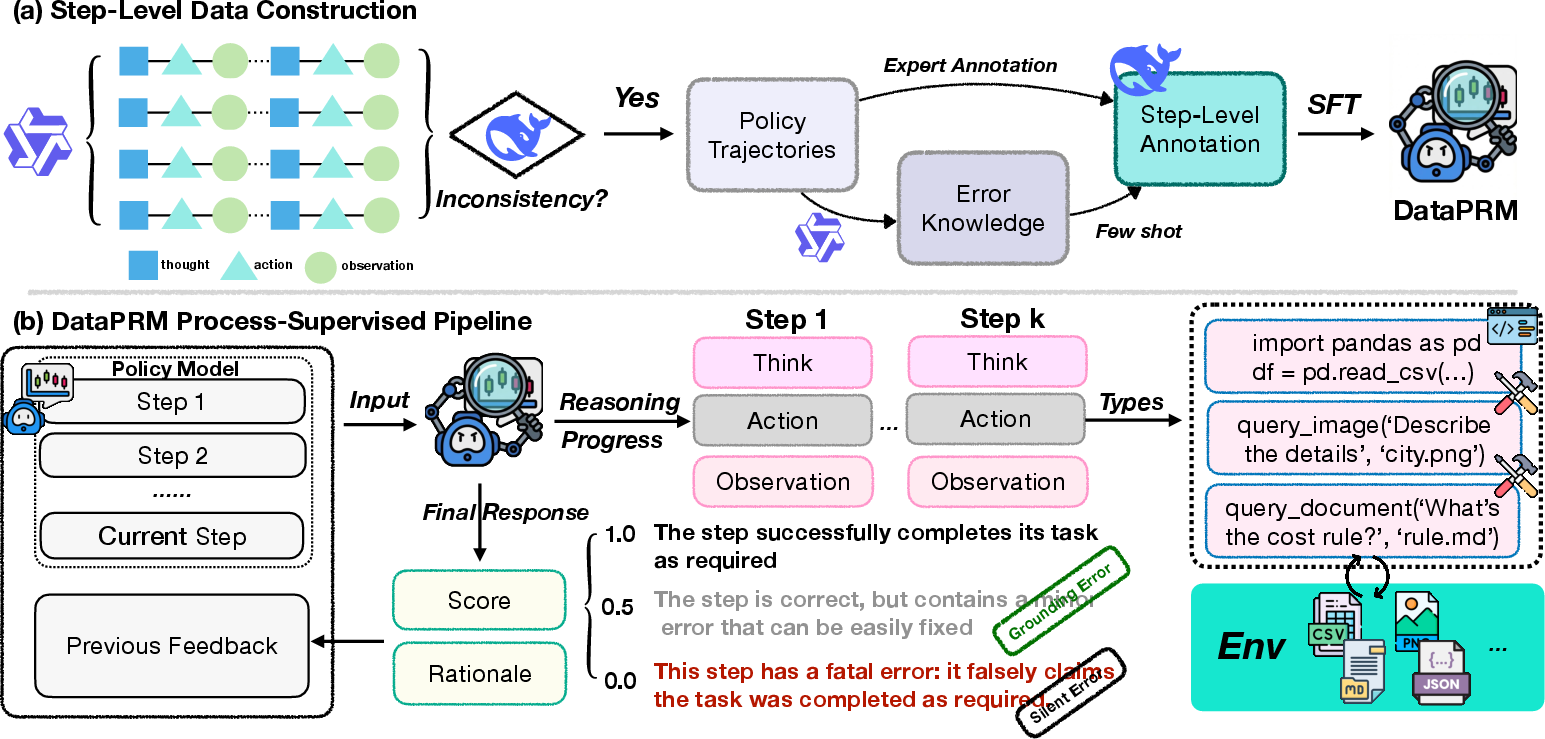
Figure 3: The DataPRM pipeline, showing diversity-driven trajectory generation, knowledge-augmented step-level annotation, and a fully interactive verification–reward loop.
Data Generation and Scalability
Leveraging the brittleness of policy models, DataPRM's training set is synthesized from a pipeline of (1) diversity-driven agent sampling—retaining only non-identical outcome trajectories for maximal supervision entropy—and (2) expert-augmented annotation, merging programmatic error attribution with curated rationales. This pipeline systematically yields over 7k high-information process supervision instances.
Experimental Results
Test-Time Scaling and Robustness
On ScienceAgentBench and DABStep, DataPRM delivers state-of-the-art agentic performance, with a 7.21% improvement on ScienceAgentBench and 11.28% on DABStep (Best-of-N). Despite a parameter count of just 4B, it robustly surpasses much larger PRMs (e.g., GenPRM-32B, Qwen2.5-PRM-72B) and LLM-judge/self-rewarding baselines. Scaling analyses show consistent monotonic improvement as search pool N grows, whereas existing PRMs degrade due to reward hacking—a direct consequence of improper penalty for exploration—whereas DataPRM maintains process fidelity.
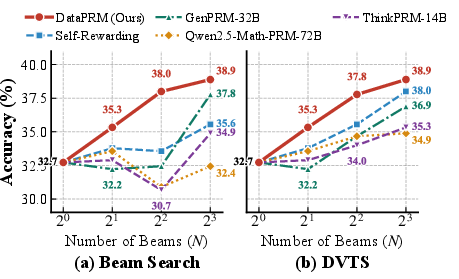
Figure 4: DataPRM maintains strong performance across Beam Search and Diverse Verifier Tree Search policies, revealing resistance to reward exploitation and empirical robustness.
RL Integration and Process-Supervised Training
In RL settings, policy models trained with DataPRM supervision achieve 78.73% accuracy on DABench and 64.84% on TableBench (Figure 5). Notably, outcome-only reward RL converges prematurely, evidenced by entropy collapse and stagnating reward signals; DataPRM-trained agents exhibit sustained exploration and pass@3 improvements, affirming the importance of dense, stepwise rewards within high-dimensional agentic solution spaces.
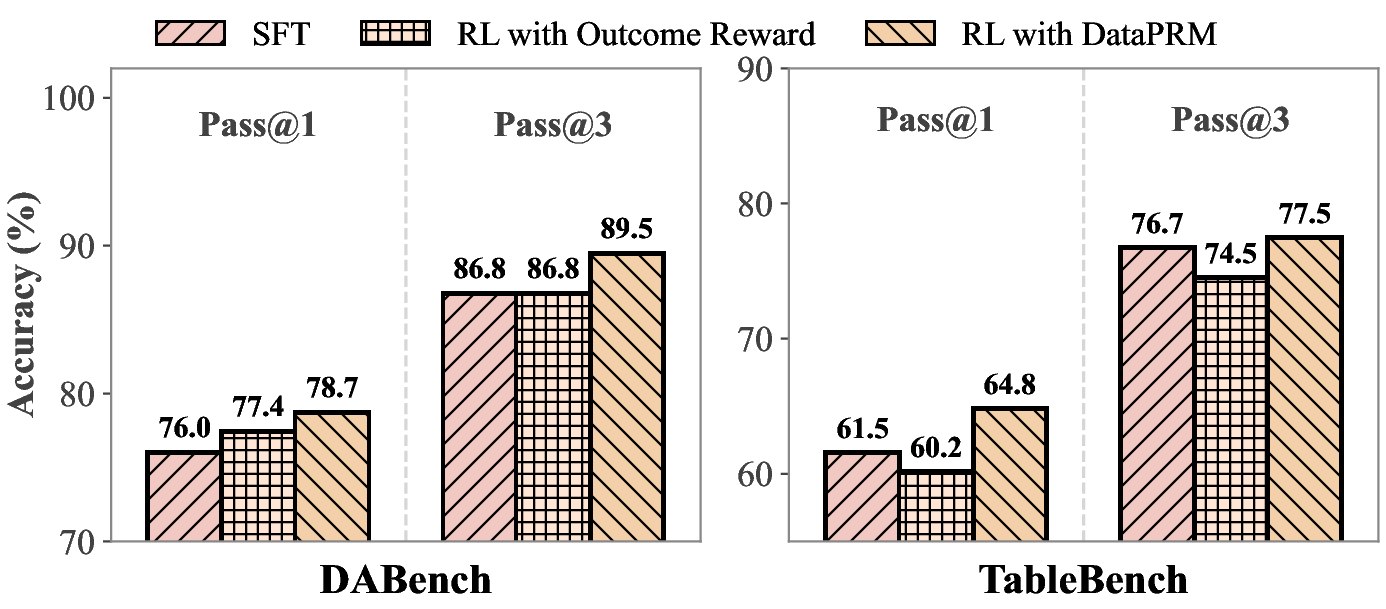
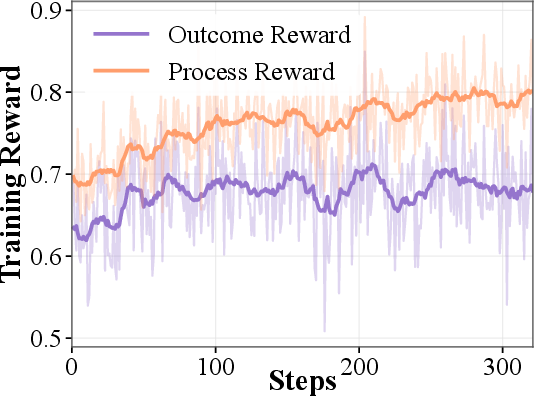
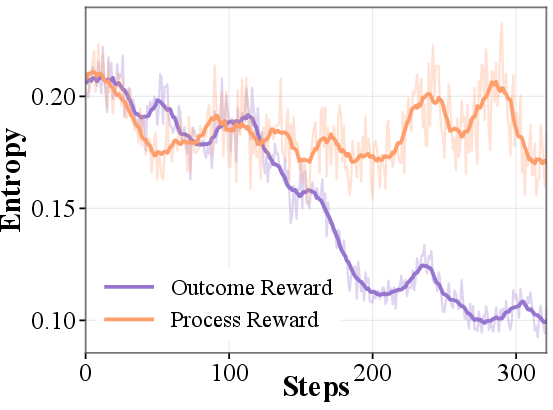
Figure 5: Process-level RL training: DataPRM significantly elevates downstream RL accuracy on DABench and TableBench.
Module and Data Component Ablation
Ablations for environment interaction, multi-turn verification, and the ternary reward schema highlight non-trivial interaction effects: multi-turn + environment context yields the bulk of the gain, with the ternary reward further closing the gap by resolving ambiguity in necessary adaptation versus actual error. Data filtering further reveals—counterintuitively—that higher data diversity in process supervision outperforms strict answer-purification, underscoring the value of broad-based agentic feedback in PRM training sets.
Theoretical and Practical Implications
The DataPRM architecture demonstrates that process-level reward modeling for agentic environments is nontrivial: static or purely outcome-based verification is insufficient for step-resolved reasoning in complex, multi-modal domains. Rather, environment-aware generative verifiers and information-theoretic reward granularity are operational prerequisites for generalizing PRMs beyond static reasoning tasks. The ternary reward manifests a formal reflection/exploration signal, tying together epistemic progress and task completion metrics.
Practically, scalable data pipelines for boundary-case trajectory sampling and multi-source annotation are essential to construct robust PRMs. This insight is domain-agnostic and points toward similar requirements for scientific, engineering, or broader agentic AI workflows.
Future Directions
Future research should focus on scaling environment-aware PRMs to richer tasks (e.g., model design, causal inference) and on minimizing supervision requirements via RL, skill-based distillation, or meta-critic strategies. Further, the integration of real-world noisy, incomplete, or ambiguous supervisory signals remains an open challenge for process-level reward models in the wild.
Conclusion
This work exposes the inherent shortcomings of prior process reward paradigms for data-analytic agents and introduces DataPRM as an effective, scalable solution. The results show that fine-grained, interactive reward supervision is essential for reliable agentic data analysis, and that generative, environment-aware verification and reward schemas dramatically elevate both RL optimization and inference search efficacy. DataPRM offers a template for future process-verified agentic AI development and evaluation.
Reference:
"Rewarding the Scientific Process: Process-Level Reward Modeling for Agentic Data Analysis" (2604.24198)

