- The paper shows that RL post-training retains a stable, task-agnostic feature subspace compared to SFT's over-specialized feature proliferation.
- It employs Sparse Crosscoders for precise feature alignment and causal interventions, achieving significant performance improvements on various benchmarks.
- The findings suggest that RLHF is essential for enhancing generalization in LLMs, preserving base features for robust cross-domain transfer.
Mechanistic Feature-Level Analysis of Reinforcement Learning Generalization in LLMs
Motivation and Controlled Setup
The paper "Why Does Reinforcement Learning Generalize? A Feature-Level Mechanistic Study of Post-Training in LLMs" (2604.25011) addresses a fundamental open question: why do LLMs post-trained via RLHF consistently exhibit superior generalization to reasoning tasks outside their training domain, whereas supervised fine-tuning (SFT) often induces capability forgetting? By employing a strictly controlled experimental protocol—training SFT and RL models from identical base checkpoints on the same data—the authors ensure observed representational differences are attributed exclusively to the post-training paradigm. The analysis is grounded in cross-family (Qwen3-4B, Qwen2.5-7B, Llama3.1-8B-Instruct) evaluations across both mathematical and general QA benchmarks.
Feature Alignment via Sparse Crosscoders
The paper leverages Sparse Crosscoders (SCs) as the central interpretability mechanism. These linear, sparse autoencoder variants are used to jointly encode the residual activations of models in a unified, semantically aligned feature space. The authors advance SC methodology by introducing a three-model variant, allowing simultaneous alignment and attribution across base, SFT, and RL models. The Model Attribution Score (MAS) enables precise quantification of feature exclusivity and sharing across paradigms. The Normalized Relative Norm (NRN) further captures model-specificity of features.
Representational Dynamics: SFT vs RL
A principal finding is the stark divergence in representational evolution under SFT and RL. SFT rapidly introduces a large set of highly specialized features (NRN ≥ 0.8), stabilizing early and remaining persistent throughout optimization. This results in a rigid, task-specific internal structure which discards many base features. In contrast, RL post-training induces fewer, milder deviations (no extreme NRN tail), preserving much of the original model's feature repertoire and continually evolving its internal landscape.
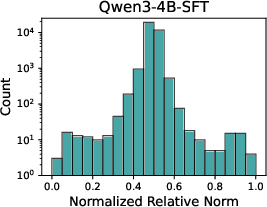
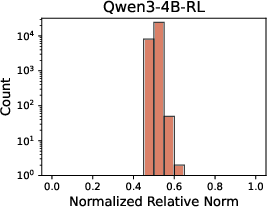
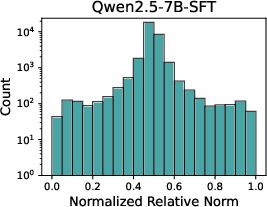
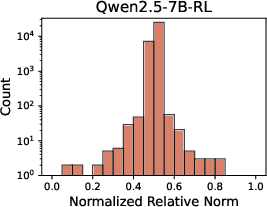
Figure 1: Distribution of Normalized Relative Norms across different training methods and model scales demonstrates SFT's aggressive feature turnover versus RL's retention of base features.
Moreover, temporal analysis using checkpointed SC training unveils that SFT's feature overlap is high across epochs (features established early), while RL is characterized by negligible overlap and substantial feature turnover throughout training.
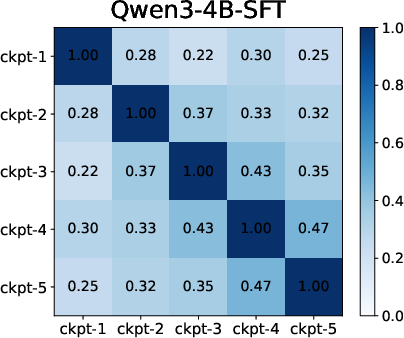
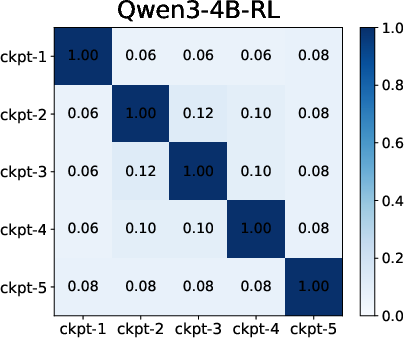
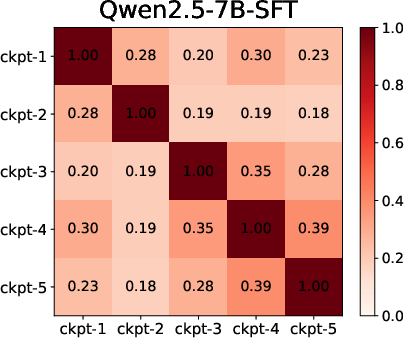
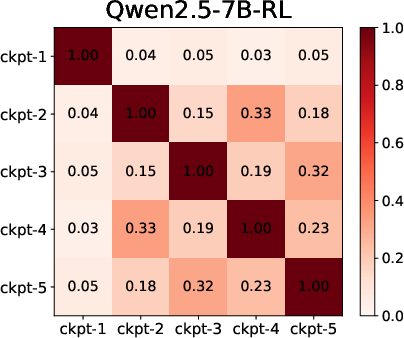
Figure 2: Feature overlap heatmaps across training checkpoints show SFT's early stabilization and RL's incremental, protracted feature evolution.
Feature rank shift analyses further empirically validate this distinction, with SFT's rank hierarchy largely stabilizing after initial epochs and RL showing continuous rank reordering and blanking.
MAS Distribution and Feature Specificity
The three-model Sparse Crosscoder allows direct comparison of feature specificity. MAS distributions confirm SFT's right-skew (many strongly attributed features), while RL yields significantly fewer paradigm-specific features, supporting the thesis that RL tunes generalization through subtle shared features.
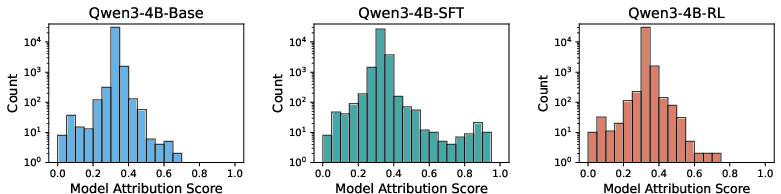
Figure 3: Distribution of Model Attribution Scores on Qwen3-4B-Base; SFT induces many high-attribution features, RL operates with restrained specificity.
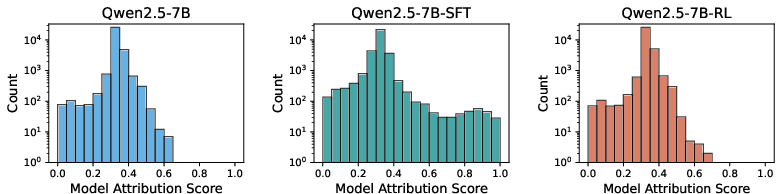
Figure 4: Distribution of Model Attribution Scores across different training methods on Qwen2.5-7B; consistent trends are observed for larger models.
Mechanistic Identification of Generalization Features
To move from descriptive statistics to functional causal analysis, the authors localize "generalization-controlling" features. By focusing on samples where RL succeeds and base fails across diverse benchmarks, they select features whose activation differences are consistent and significant—a task-agnostic intersection forming a compact set of generalization features (50 for Qwen3-4B, 16 for Qwen2.5-7B).
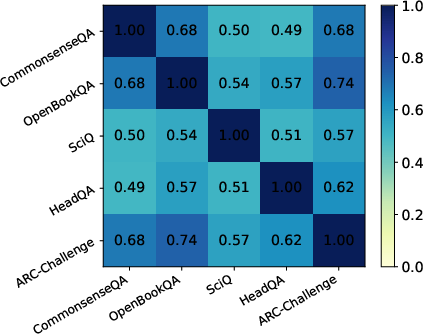
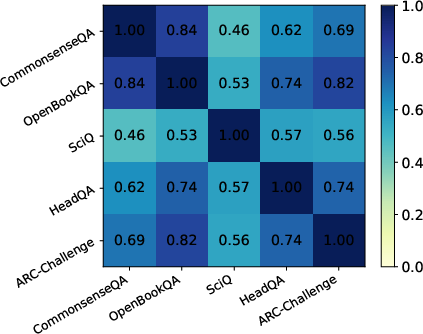
Figure 5: Feature overlap across tasks reveals high intersection, identifying compact sets of generalization-controlling features.
Causal Intervention Experiments
The causal role of these features is rigorously validated: zeroing them in RL models leads to catastrophic performance drops (>40% for OpenBookQA, CommonsenseQA), while amplifying them in base models induces dramatic performance gains (up to 56% on SciQ for Qwen2.5-7B). These interventions are robust to transfer: generalization features amplify performance on unseen tasks (LogiQA, PIQA), indicating task-domain independence.
Theoretical Implications
The paper offers a direct mechanistic explanation for RL-induced generalization: RL does not simply incentivize answers, but selectively strengthens a compact, task-agnostic subspace in the internal feature manifold, causally mediating cross-domain transfer. SFT, conversely, overfits via feature proliferation that encodes teacher traces and eliminates general reasoning pathways. This distinction reframes RLHF as a paradigm for preserving and selectively reweighting functional circuitry, diverging from conventional distillation-based view of SFT.
Practical Implications and Future Directions
These findings have immediate practical implications: adoption of RLHF should be preferred in reasoning post-training when transferability and avoidance of catastrophic forgetting are critical. The SC methodology provides a robust foundation for interpretability-focused fine-tuning, enabling targeted interventions in internal feature spaces. Future research directions include automated training objectives to explicitly select for generalization features, integration with alternative interpretability schemes, and scaling experiments across model architectures and task distributions.
Conclusion
Through rigorous controlled experiments and mechanistic feature-level analyses, the paper establishes that RLHF generalizes by reinforcing a stable, task-agnostic feature subspace, contrasting sharply with SFT's over-specialized and rigid internal encoding. Feature-level causal interventions confirm generalization is governed by a small set of functional features, transferable across tasks and architectures. The analysis underscores the importance of granular interpretability methodologies for understanding and controlling post-training dynamics in LLMs.