- The paper introduces AutoResearchBench, a benchmark for evaluating AI agent performance on complex scientific literature discovery tasks.
- It defines two key task types—Deep Research and Wide Research—highlighting the need for multi-hop reasoning and precise evidence integration.
- Experimental results expose a significant performance gap, with top models achieving only around 9% accuracy or IoU, underscoring the need for robust research frameworks.
AutoResearchBench: Advancing Evaluation for Agentic Scientific Literature Discovery
Motivation and Problem Setting
AutoResearchBench addresses the critical need for evaluating AI agent systems on rigorous scientific literature discovery tasks—capabilities foundational to autonomous research. The benchmark is explicitly tailored to capture the full complexity and demands of real-world scholarly exploration, where evidence is technical, often buried within full texts, and the set of valid results is open-ended and sometimes empty. Scientific literature search is not reducible to surface-level retrieval: it requires multi-hop reasoning, deep comprehension, and the ability to construct or exhaustively enumerate answer sets under uncertain constraints.
AutoResearchBench introduces two principal task types:
- Deep Research: Precise identification or abstention over the existence of a unique paper matching a conjunction of subtle, obfuscated constraints. The agent must perform multi-step reasoning and verification, often across full document context and citation chains.
- Wide Research: Comprehensive recovery of an entire set of papers matching intricate conjunctions of scientific attributes, with no prior on set cardinality. Agents must maximize recall without sacrificing precision, under the pressure of unknown answer boundaries.
The benchmark is instantiated over an up-to-date arXiv-sourced full-text corpus exceeding three million papers, facilitating evaluation in realistic settings with genuine technical evidence.
Benchmark Construction and Methodology
The benchmark construction follows a two-stage, human-in-the-loop pipeline with model-augmented candidate generation, focusing on coverage, minimal sufficiency, and resistance to shortcut exploitation.
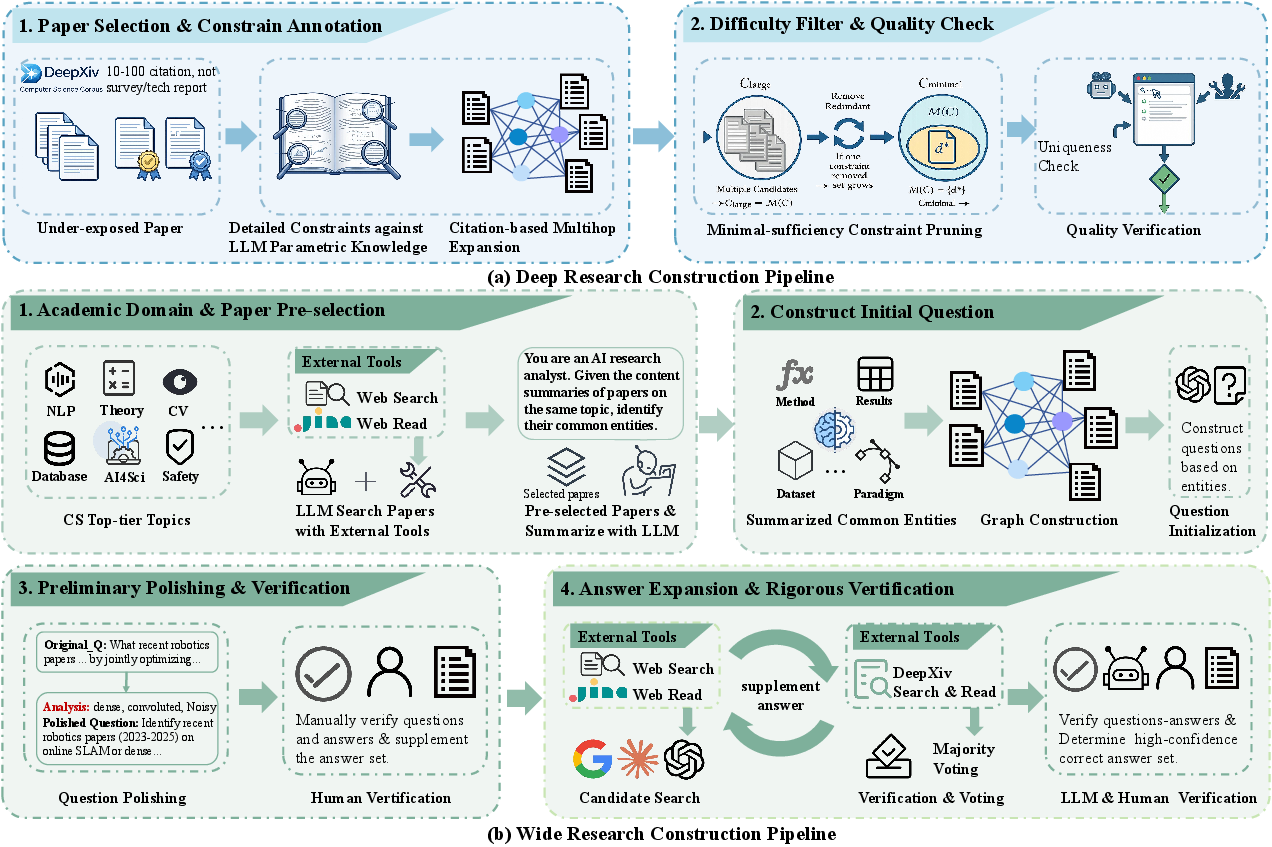
Figure 1: Overview of the benchmark construction pipeline for deep and wide research tasks.
For Deep Research, human annotators iteratively extract, refine, and paraphrase constraints from full paper context, eschewing headline clues, and rigorously verifying instance uniqueness. Negatives are constructed by perturbing constraints to ensure unsatisfiability. For Wide Research, large domain-specific candidate pools are synthesized, summarized, and filtered—then iteratively expanded using multiple LLMs and search tools, with rigorous human expert auditing to guarantee set completeness and label quality.
The result is 1,000 benchmark instances: 600 deep research (90% single-answer, 10% unsatisfiable) and 400 wide research (average valid set size 9.23).

Figure 2: Category distribution of deep and wide research tasks across major CS domains.
Task Evaluation Protocol and Metrics
AutoResearchBench employs a standardized ReAct-based agent framework, providing parity across open and closed-source LLMs as well as integrated end-to-end research agents. The evaluation is strictly contamination-resistant and leverages a unified DeepXiv toolchain, enabling direct, scalable search over full texts.
- Deep Research uses exact-match accuracy (matching the unique valid document, or abstaining when none exists).
- Wide Research employs set-based intersection-over-union (IoU), rewarding both precision and recall on open-set enumeration.
Emphasis is placed on interactive agent behavior, tool usage efficiency, and reasoning quality rather than static retrieval accuracy.
Experimental Results and Analysis
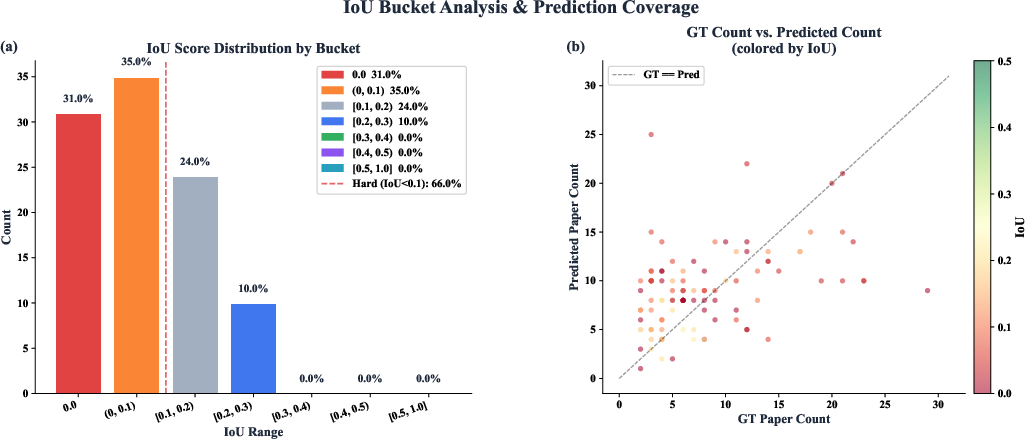
Main finding: All evaluated LLM agents—despite state-of-the-art performance on general web agent tasks—struggle severely on AutoResearchBench. The best closed-source model (Claude-Opus-4.6) achieves merely 9.39% accuracy for deep research; the best for wide research (Gemini-3.1-pro-preview) reaches only 9.31% IoU.

Figure 3: Illustration of complex trajectories required on deep and wide research instances, and performance collapse of flagship agents.
Most other models remain below 5% on both metrics. This represents an order-of-magnitude performance gap compared to previous web-based agent benchmarks, where top models regularly surpass 80%. Interactivity analysis reveals that simply increasing trajectory length or tool call count does not correlate with better outcomes; more steps often lead to redundant actions or illogical persistence.
Error analysis (see also Figure 4 in the paper) reveals persistent deficits:
Tool analysis confirms that a specialized academic search index (DeepXiv), with full-text coverage, is necessary; open-web search tools yield an even steeper collapse due to missing critical context.
Scaling and Ablation Studies
Scaling test-time compute—e.g., repeating trajectories and aggregating via pass@k or oracle-best—offers limited gains, evidencing that trajectory instability is only a partial bottleneck for deep research, while recall limitations dominate wide research.
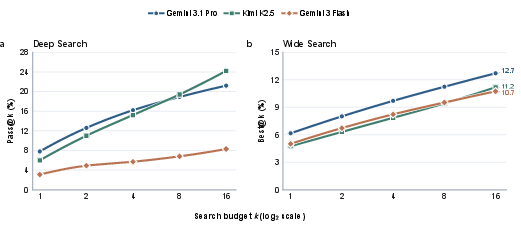
Figure 6: Test time scaling experiment across multiple models demonstrates only marginal improvement, reinforcing the irreducible complexity of the benchmark.
Ablation studies on thinking modes demonstrate that more structured reasoning does not consistently improve set coverage or identification performance, implying a need for substantially more robust agentic scientific reasoning architectures.
Implications and Future Outlook
AutoResearchBench provides compelling evidence that modern LLMs and agent-based frameworks, effective in web and general knowledge settings, do not transfer to the domain of complex, technical, open-ended scientific literature search. The tasks' difficulty is not simply due to input/document length, but rather arises from the confluence of:
- Long-horizon, multi-hop reasoning needs.
- Full-text and citation-network evidence integration.
- Open-world, underspecified, or unsatisfiable query scenarios.
- The need to balance completeness and correctness with verifiable evidence.
Success on AutoResearchBench appears to require joint progress on retrieval-augmented, logic-aware agents, scalable document analysis, principled trajectory planning, memory management for iterative hypothesis refinement, and reinforcement learning with process supervision specialized for technical and exploratory search. The results suggest that performance on traditional agentic and RAG benchmarks does not generalize and is not predictive of future agentic research capabilities.
Moreover, the dataset and tools offer a practical foundation for benchmarking incremental advances in autonomous research assistance, diagnosis of LLM reasoning and verification capabilities, and longitudinal measurement of model progress as the field pursues higher-order AI scientific skills.
Conclusion
AutoResearchBench establishes a rigorous benchmark for agentic scientific discovery, filling a critical gap in the evaluation of autonomous research capabilities. By demonstrating a substantive gap between current LLM-agent systems and real-world research needs, and by providing a detailed, controlled infrastructure for further experimentation, it marks a new standard for evaluating and driving progress in AI-assisted literature exploration and autonomous academic agents (2604.25256).