- The paper presents FACT, a three-stage agentic workflow that integrates LLM-driven optimization with compositional CUTLASS kernel synthesis to enable scalable, pattern-based auto-tuning across GPU architectures.
- It employs a hierarchical synthesis mechanism—dividing the process into pattern discovery, pattern realization, and pattern composition—to systematically optimize subgraphs with measurable speedup improvements over traditional baselines.
- Experimental results demonstrate FACT’s dynamic pattern accumulation capability, achieving up to 2.79× speedup in complex model blocks relative to established PyTorch and compiler frameworks.
FACT: Compositional Kernel Synthesis with a Three-Stage Agentic Workflow
Motivation and Context
The paper proposes FACT (Framework for Agentic CUTLASS Transpilation), a library-centric framework unifying LLM-driven agentic optimization with compositional, architecture-specific CUTLASS kernel synthesis. FACT addresses the limitations of both traditional compiler-driven tensor program optimization—constrained by finite, engineer-encoded catalogs—and existing LLM agent approaches, which focus on synthesizing raw CUDA and thereby re-deriving optimizations already captured in advanced libraries. In contrast, FACT systematically exploits library-grounded CUTLASS templates for kernel synthesis, while maintaining a persistent, dynamically growing pattern registry indexed across optimization rule, data type, and target GPU architecture.
The integration of LLM agents with a library-grounded kernel synthesis workflow brings three core benefits: (1) generalization and accumulation of optimization knowledge across architectures and workloads, (2) the ability to auto-tune non-trivial configuration spaces inferred from the library’s instantiations rather than fixed heuristics, and (3) enabling multi-pattern composition for end-to-end deep model optimization beyond isolated operator replacement.
FACT Workflow and System Design
The FACT system decomposes whole-model kernel optimization into a three-stage agentic pipeline: Pattern Discovery, Pattern Realization, and Pattern Composition (Figure 1). Each stage exposes clear action interfaces for LLM-based orchestration and facilitates progressive optimization, from subgraph pattern matching to integrated deployment with PyTorch.
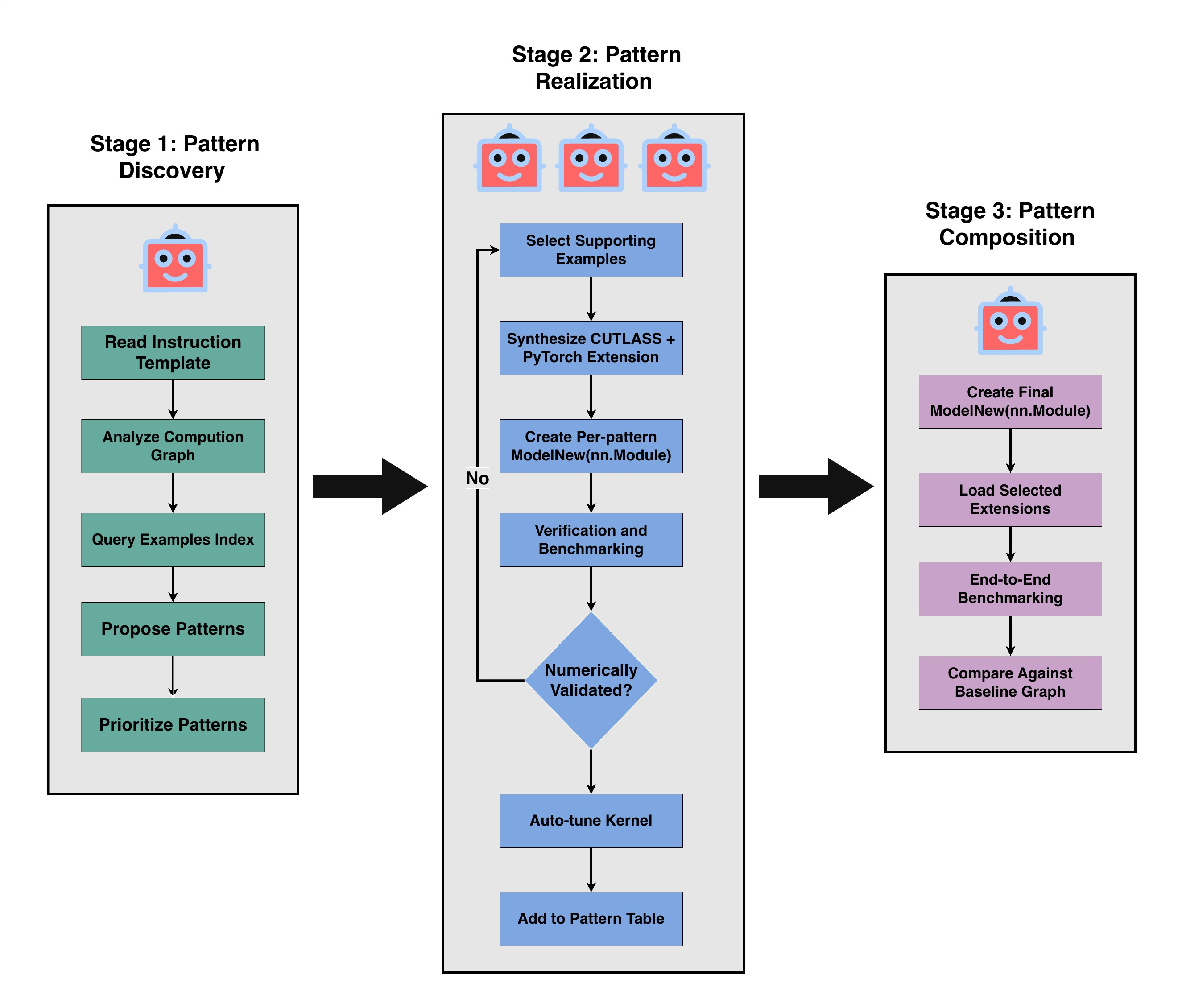
Figure 1: The FACT three-stage workflow: pattern discovery via graph analysis, pattern realization through CUTLASS kernel synthesis, and composition into deployable PyTorch models.
Stage 1: Pattern Discovery
The LLM-based agent first inspects the traced PyTorch computation graph, matches subgraphs with known optimization rules (e.g., GEMM, FMHA, fused MLP), and queries an architecture-indexed catalog of vetted CUTLASS example kernels. This enables rapid retrieval and prioritization of candidate patterns based on workload characteristics and expected performance gain.
Stage 2: Pattern Realization
For each prioritized pattern, the agent performs kernel synthesis by instantiating the relevant CUTLASS template, guided by retrieved examples. The synthesis process is structured hierarchically along three CUTLASS design levels (Figure 2):
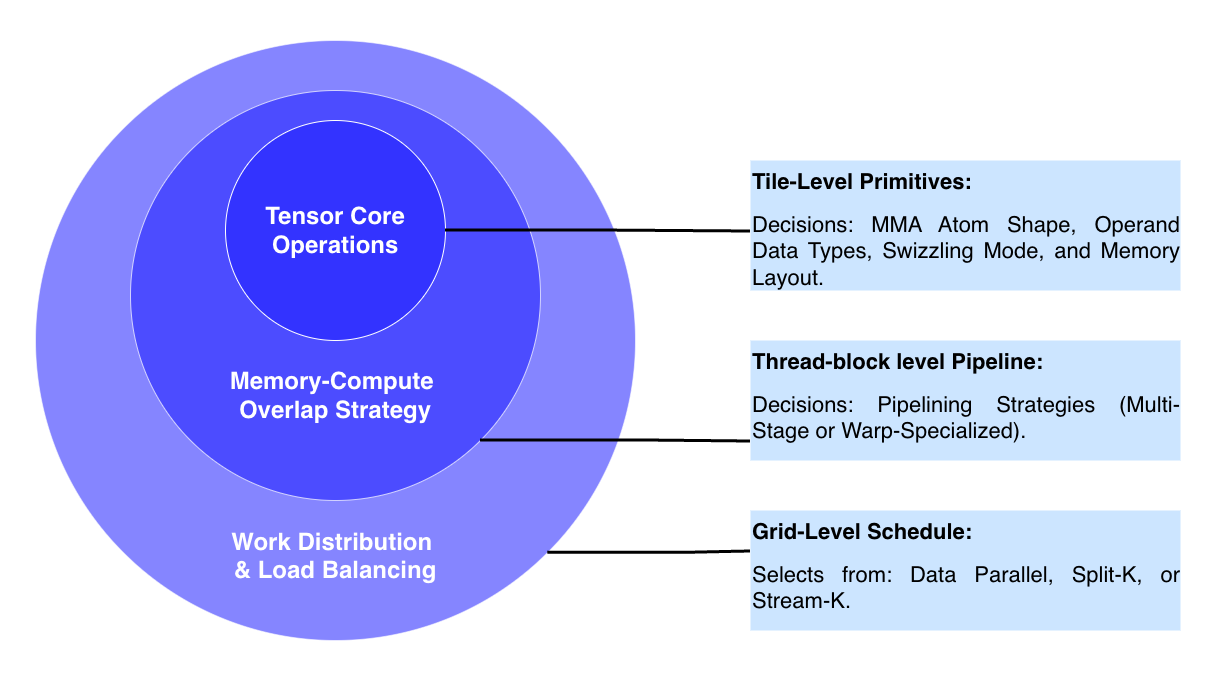
Figure 2: CUTLASS synthesis hierarchy—tile-level primitives, kernel-level pipelining, and grid-level scheduling.
- Tile Level: Configuration of tensor core primitives, instruction shapes, operand layouts.
- Kernel Level: Selection of software pipelining (multistage for Ampere, warp specialization for Hopper), including pipeline depth or kernel schedule type.
- Grid Level: Scheduling policy selection (data-parallel tiling, Split-K, Stream-K).
After initial synthesis, the agent wraps the kernel as a PyTorch extension, verifies correctness (element-wise tensor matching), measures end-to-end runtime, and conditionally triggers parameter-space auto-tuning. The auto-tuning search space is extracted from CUTLASS test instantiations, enabling sweep over tile shapes, pipeline stages, and other architecture-dependent parameters. The best-tuned variant is retained, and the kernel is then entered into the dynamic pattern table, indexed by rule, type, and architecture.
Stage 3: Pattern Composition
The realized kernels are composed into a new computation graph, replacing each matched subgraph with a call to the corresponding optimized extension. The system manages build, extension loading, and model benchmarking, reporting end-to-end speedup over baseline PyTorch and vendor library alternatives.
Experimental Results
Experimental evaluation is conducted on NVIDIA A100 (Ampere, SM80) on a range of kernel types and model blocks, using the KernelBench evaluation framework. Benchmarks span three GEMM variants (square, batched, large-K) and a complex Transformer-style block (MiniGPT).
Level-1 GEMM Optimization
For three representative GEMM workloads, FACT’s agent discovers and synthesizes kernels matching the optimal scheduling policy for each workload. Auto-tuning on the extracted search space consistently provides speedups over PyTorch cuBLAS baselines: 1.14× for square GEMM, 1.18× for batched GEMM, and 1.06× for large-K GEMM (Figure 3).
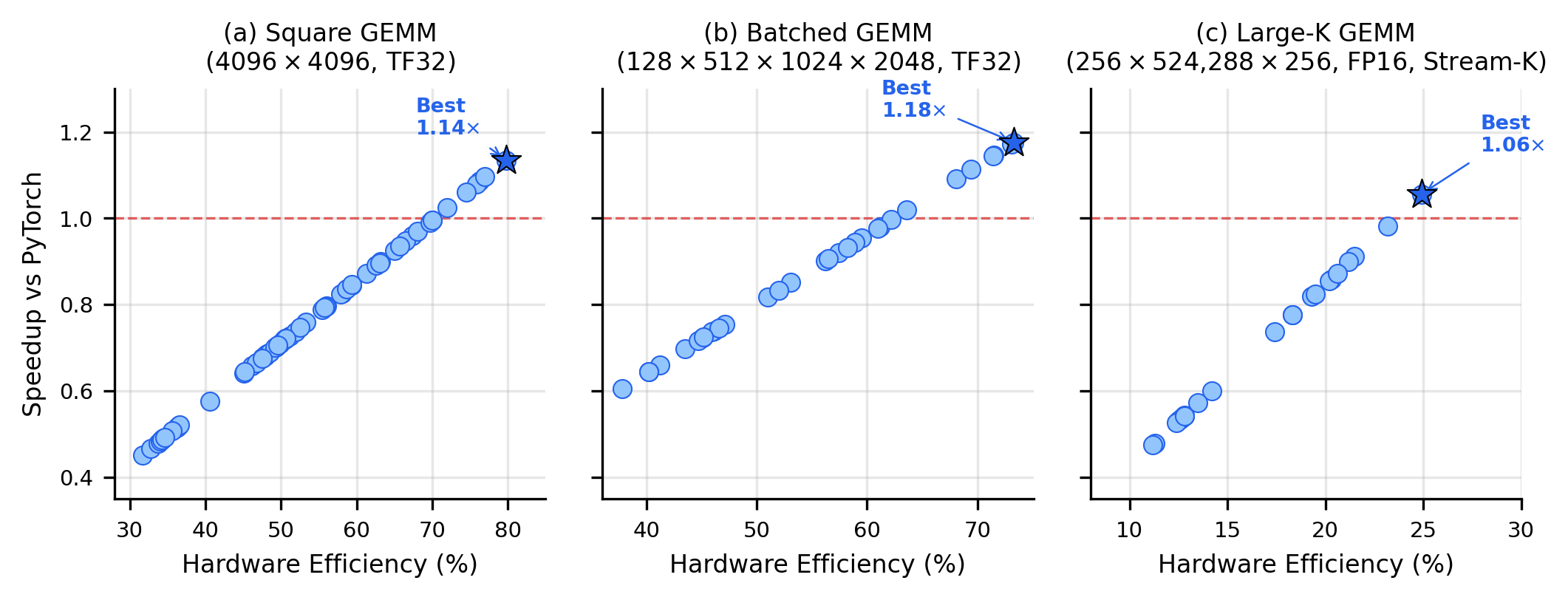
Figure 3: Auto-tuning exploration of tile shapes and pipeline stages for Level-1 tasks on A100; stars mark configurations winning over PyTorch cuBLAS.
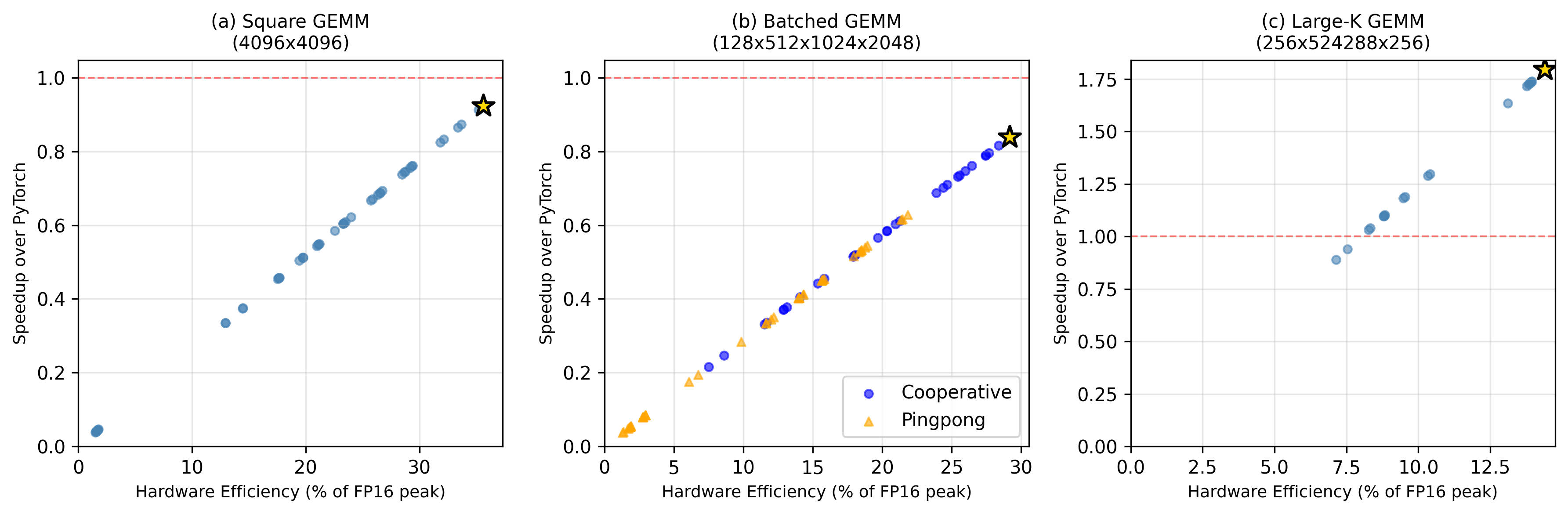
Figure 4: Corresponding autotuning results on H100 (Hopper), showing additional grid-level schedule type exploration (cooperative, pingpong).
Analysis shows that CUTLASS's rich scheduling policies (e.g., Stream-K for large-K workloads) and template auto-tuning allow FACT to outperform vendor libraries especially for batched/irregular shapes where such libraries rely on fixed heuristics.
Multi-Pattern Block Composition
On the challenging MiniGPT-style block, FACT discovers multi-head attention (FMHA) and fused GEMM+GELU as high-impact candidates, synthesizes fused kernels for both, and composes them into an optimized block. The result is a 2.79× end-to-end speedup relative to PyTorch eager mode, outperforming both Inductor (1.86×) and Torch-TensorRT (1.81×) compiler baselines (Figure 5).
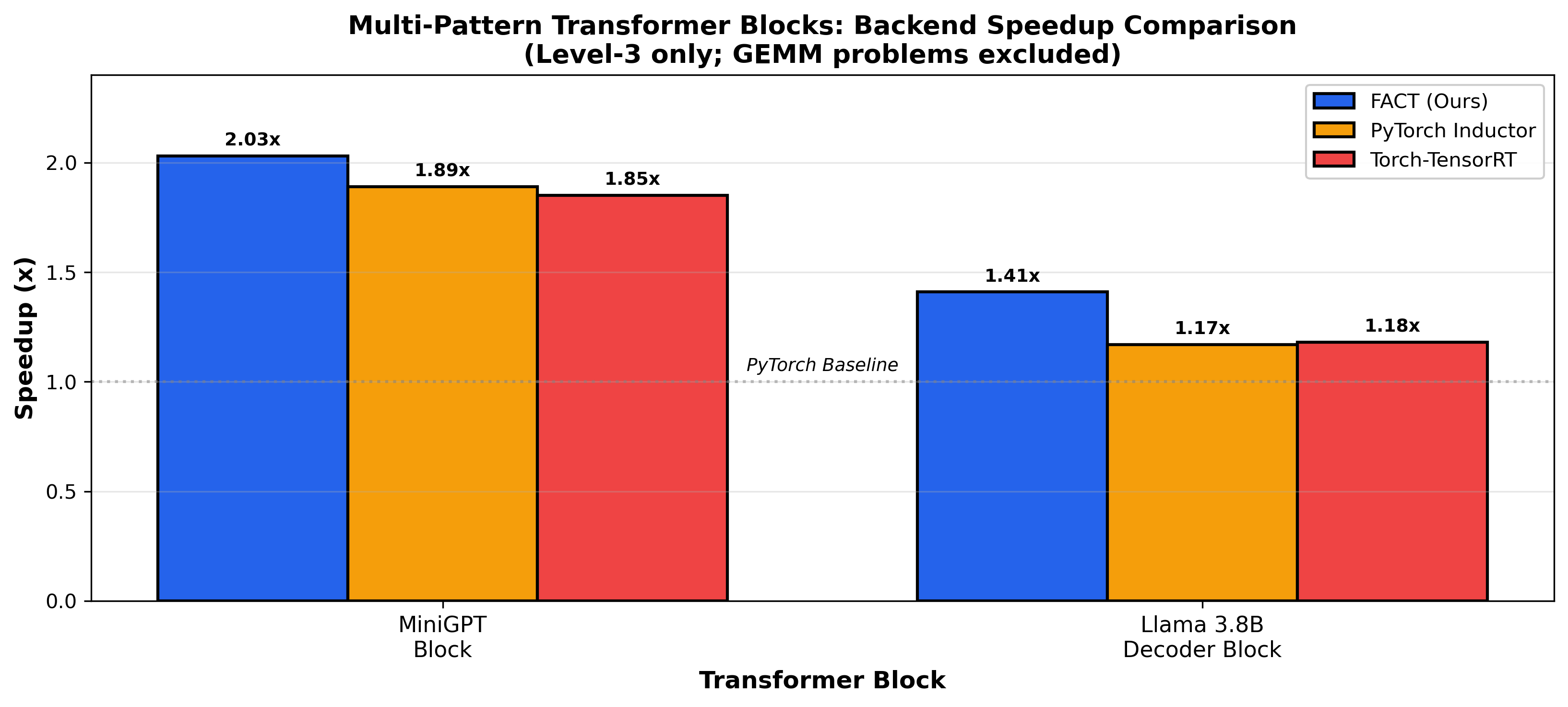
Figure 5: Backend speedup comparisons for advanced blocks; only FACT reaches 2.79× via aggressive multi-pattern tuning.
Ablation analysis (Figure 6) reveals that most gains originate from MLP fusion, though both components are required for maximal aggregate throughput.
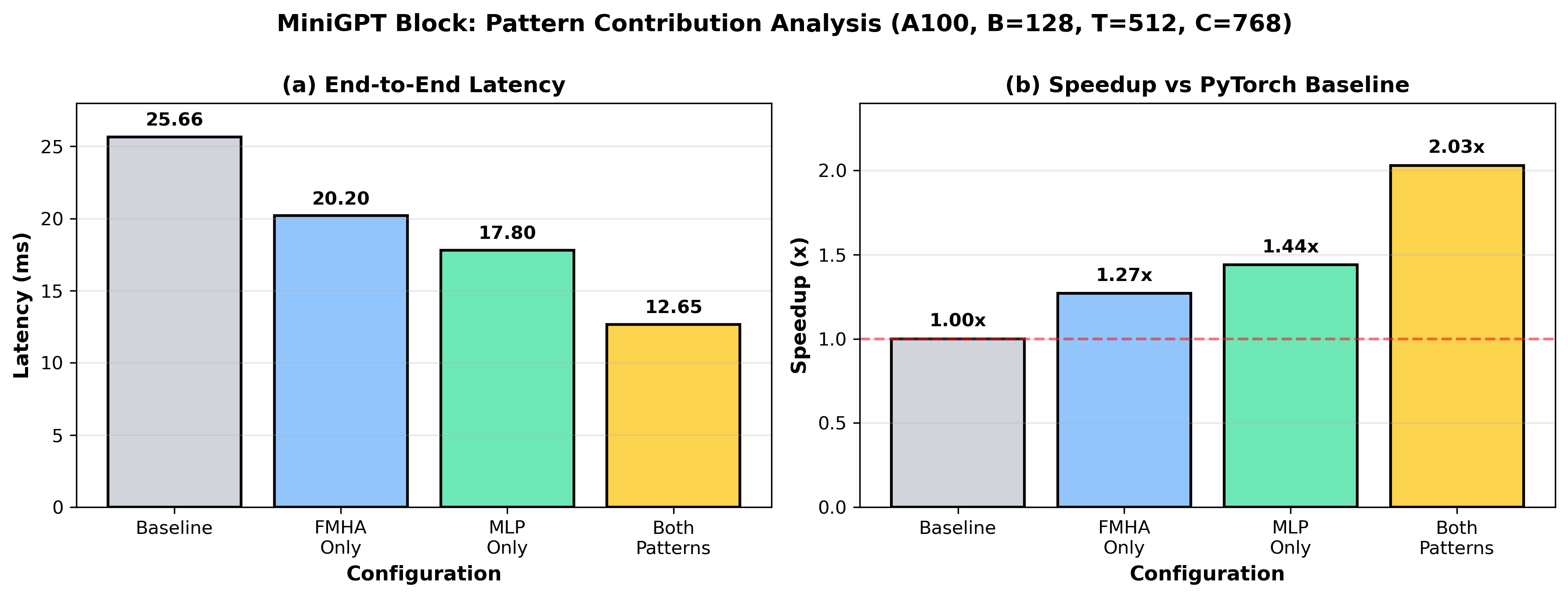
Figure 6: MiniGPT block ablations—single-pattern vs dual-pattern optimization, showing the additive effect of compositional instantiation.
Scalability and Generalization
The experimental protocol highlights that FACT’s agentic workflow not only achieves modest-to-substantial speedups across operator types but does so via systematic pattern table growth. Optimizations are automatically accumulated and reused, reducing synthesis overhead for subsequent models with overlapping workloads.
Implications and Future Directions
FACT’s integration of agentic optimization with CUTLASS library grounding demonstrates a practical bridge between LLM-driven, closed-loop code synthesis and state-of-the-art architecture-tuned libraries. Key implications include:
- Pattern Table Generalization: Dynamic pattern accumulation enables scaling across models and hardware generations, reducing redundant search and making agentic optimization incrementally more effective.
- Library-Augmented Agent Learning: Unlike prior raw-CUDA synthesis agents, FACT leverages vetted library templates for both safety and coverage, avoiding rediscovery of known optimizations.
- Compiler Complementarity: FACT does not supplant tensor compilers but provides a means of aggressive, subgraph-specific tuning that compiler backends may not reach, especially for novel pattern compositions and data types.
Several avenues remain open for future generalization:
- Extending support for Hopper-specific schedules (e.g., TMA, WGMMA pipelining) and other emerging CUDA primitives.
- Benchmarking and ablation against state-of-the-art LLM agent systems (e.g., KernelBlaster, CUDA Agent, StitchCUDA) to disentangle the benefits of library grounding versus reward engineering or in-context RL.
- Community release of generated kernel artifacts and tuning logs for reproducibility.
Conclusion
FACT establishes a scalable methodology for bridging LLM agentic reasoning and compositional CUDA kernel synthesis. The three-stage workflow—pattern discovery, realization, and composition—enables persistent, architecture-aware multi-pattern optimization, outperforming both mature vendor libraries and current deep learning compilers for targeted workloads. Its dynamic knowledge accumulation and systematic exploitation of CUTLASS parametric space offer a template for future AI-augmented systems, where agents both leverage and extend evolving, highly parameterized software libraries.