- The paper introduces ANCORA, a unified framework that shifts the focus from answering to questioning in verifiable reasoning.
- It employs a coupled two-level group update, iterative self-distillation, and a UCB-guided curriculum DAG to stabilize RL on thin valid manifolds.
- Experimental results on formal verification benchmarks show significant performance gains, even with a 3B-scale model and 0-shot test settings.
Manifold-Anchored Self-Play for Verifiable Reasoning: The ANCORA Framework
Motivation and Theoretical Foundations
"ANCORA: Learning to Question via Manifold-Anchored Self-Play for Verifiable Reasoning" (2604.27644) introduces a unified policy paradigm for autonomous learning in formal reasoning domains. The authors argue that standard supervised fine-tuning (SFT) and RL from verifiable rewards (RLVR) are fundamentally limited by reliance on a static, human-curated prompt pool and inherent scaling bottlenecks if the base model lacks sufficient coverage of structurally valid outputs. ANCORA shifts the optimization focus from learning to answer (solving) to learning to question (proposing), positing that a LLM, via alternating proposer/solver roles, can autonomously generate and verify novel reasoning problems and solutions, thereby expanding its epistemic horizon beyond its initial prompt pool.
Sparse-reward RL on thin valid manifolds is theoretically shown to induce policy collapse through three mechanisms: positive signal starvation, off-manifold gradient distortion, and optimizer momentum drift (see appendix for formal proofs). The probability of positive-gradient informative groups sharply decreases in low-manifold-mass regimes, such that standard binary reward RL fails unless the policy is anchored onto the valid-output manifold prior to RL; otherwise, most groups produce zero gradient, compounding the collapse via drift. The manifold-constrained SFT warmup and the strictly gated curriculum expansion are thus required for a non-degenerate policy update.
Methodological Contributions
ANCORA comprises three load-bearing components:
- Coupled Two-Level Group-Relative Update: Proposer advantages are aggregated across specifications and Solver advantages across solution attempts, using a mean-normalized variant of Group Relative Policy Optimization (GRPO) motivated by Maximum-Likelihood RL (MLRL); this is crucial for correctly weighting rare success events by their informativeness.
- Iterative Self-Distilled SFT: The base model is projected onto its valid-output manifold through iterative distillation of verifier-filtered rollouts, breaking signal starvation and providing a non-collapsed starting point for RL. Results show an improvement from 0.4% to 26.6% pass@1 on Dafny2Verus after SFT.
- UCB-Guided Curriculum DAG: The prompt pool is dynamically expanded via UCB-guided tree search on strictly verified, novel specifications, admitting only nodes for which the solver produces a valid solution. This ensures curriculum growth remains anchored to valid regions and prevents drift into invalid space.
The learning paradigms under ANCORA and comparator baselines are illustrated below.
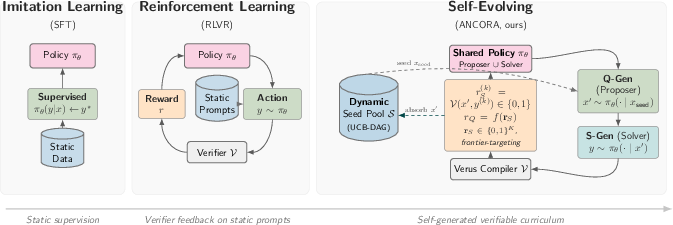
Figure 1: Learning paradigm comparison: ANCORA dynamically grows the curriculum via strictly filtered, solver-verified specifications and coupled RL updates, escaping the bounds of static SFT or RLVR.
The iterative self-distilled SFT procedure is visualized below.
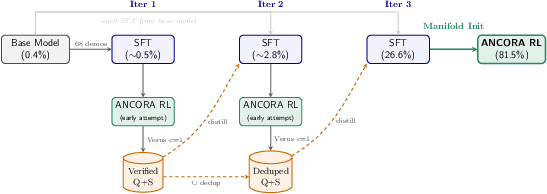
Figure 2: Self-distillation progressively projects the base policy onto the valid manifold, enabling RL training to avoid positive-signal starvation and model collapse.
Curriculum expansion relies on compositional reachability via the UCB-guided DAG:
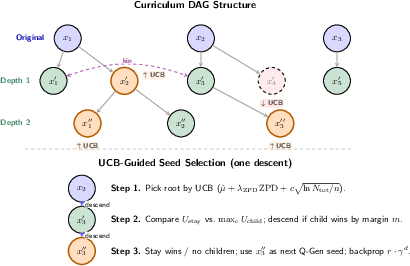
Figure 3: UCB-guided Curriculum DAG: Seeds and their descendants are admitted only after solved-only verification; high-UCB frontier nodes are prioritized, facilitating anchored expansion of the curriculum.
Experimentation and Empirical Results
Experiments are conducted on the Verus formal verification benchmarks: Dafny2Verus, MBPP-Verified, and HumanEval-Verified. A single Qwen2.5-Coder-3B model is trained via full-parameter fine-tuning; RL operates over 2,000 steps with a dynamically expanding DAG curriculum. The verified performance demonstrates strong numerical results:
- In test-time-training (TTT) on Dafny2Verus, ANCORA attains 81.5% pass@1, outperforming the PSV self-play baseline (1-shot) by +15.8 points, even though ANCORA uses 0-shot at test time.
- On MBPP, ANCORA reaches 44.1% pass@1 (TTT), and 36.2% on transfer from Dafny2Verus seeds. HumanEval transfer achieves 17.2% pass@1, closing the gap with PSV despite lack of target-domain exemplars.
- The learning curves reveal that coupled optimization is essential: freezing the proposer or solver branch causes plateau or collapse (see main text and appendix), confirming the necessity of two-level co-evolution.
The ablation studies demonstrate that No-Descent (root-only curriculum) initially peaks on curated seeds but collapses rapidly once the seed pool is exhausted, indicating structural necessity for compositional expansion.
Practical and Theoretical Implications
The proposed framework synthesizes autonomous curriculum learning, manifold-constrained RL, and entropy-targeted proposer rewards. The main claim is that manifold anchoring (via self-distilled SFT) and strictly anchored curriculum expansion (UCB-DAG) are jointly necessary for any thin-manifold RL regime. Without these stabilizers, RL on sparse valid output spaces induces collapse via signal starvation, off-manifold distortion, and optimizer drift, regardless of reward shape.
ANCORA operationalizes a self-growing, solver-adaptive curriculum capable of discovering new problems near the solver's epistemic frontier. The joint optimization expands the trainable distribution beyond the initial seed pool, enabling compound gains. The methodology generalizes to domains with verifiable semantics, such as formal proof synthesis or type-correct code generation. Notably, the authors argue that negative-gradient filtering is a downstream expression of the manifold constraint—highlighted in recent Lean formalization work—suggesting this principle is domain-independent.
In terms of resource efficiency, the paper empirically demonstrates that even a 3B-scale model can bootstrap verifiable reasoning without human-provided solutions or large-scale annotation. The controlled use of binary rewards, strict gating, and curriculum bandit analysis ensures robust expansion without poisoning the valid manifold.
Limitations and Future Directions
The study is compute-limited to a single scale and domain (3B model, Verus). The long-horizon dynamics, mode collapse within the valid manifold, and transfer to other settings such as Lean4 are yet unresolved. Improved solution diversity may require explicit entropy auxiliaries or repair loops. The formal homotopy continuation analysis of dynamic curriculum schedules is presented but not empirically validated at multi-shot levels. Ultimately, exploration of more advanced annealing schedules, modular repair, and cross-domain transfer remains crucial.
Gradient-norm trajectories comparing branch-weighting schemes are available for further analysis:
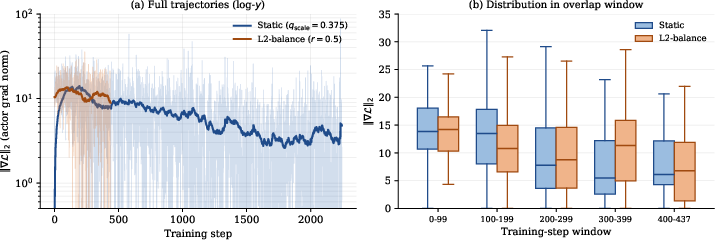
Figure 4: Gradient-norm trajectories for static vs. adaptive branch weighting; static weighting yields more stable long-horizon convergence.
Conclusion
ANCORA provides a principled framework for RL self-play in verifiable reasoning domains, unifying problem proposing and solving via a single policy, stabilized through manifold anchoring and carefully gated curriculum expansion. The empirical gains and theoretical formalism advocate that successful self-improvement in thin-manifold settings fundamentally depends on pre-RL manifold projection and state-conditioned exploration anchoring. These results substantiate ANCORA's claims and establish its methodological relevance for scalable autonomous reasoners in formal domains (2604.27644).