Generalizable Sparse-View 3D Reconstruction from Unconstrained Images
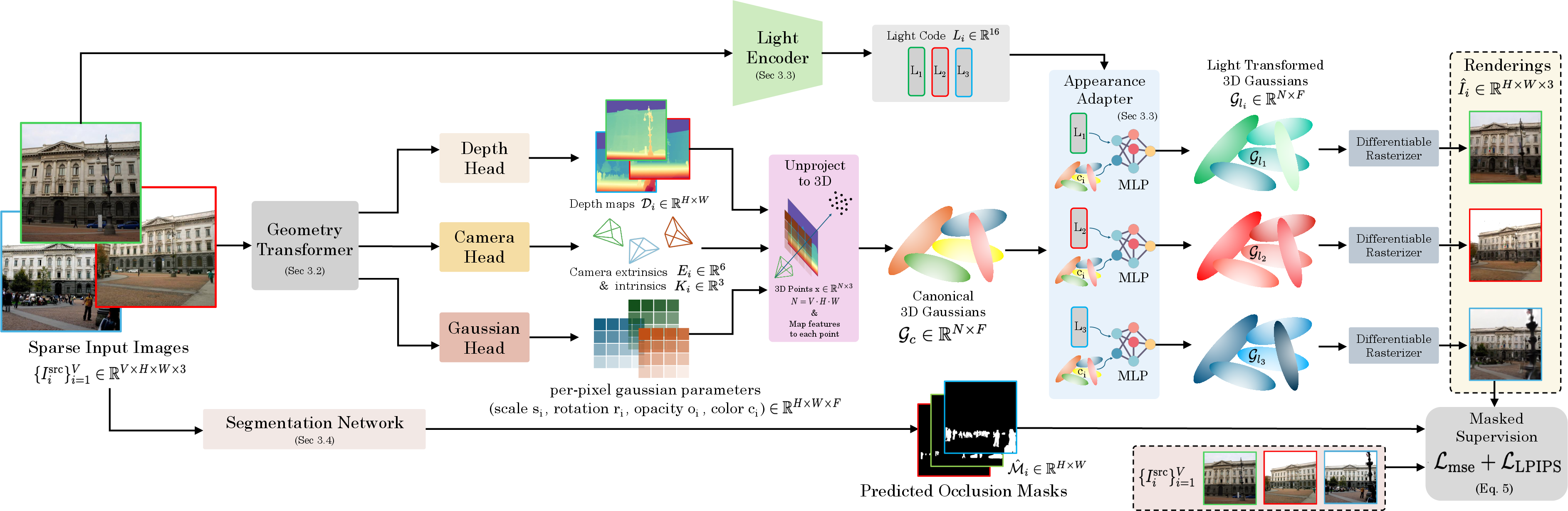
Abstract: Reconstructing 3D scenes from sparse, unposed images remains challenging under real-world conditions with varying illumination and transient occlusions. Existing methods rely on scene-specific optimization using appearance embeddings or dynamic masks, which requires extensive per-scene training and fails under sparse views. Moreover, evaluations on limited scenes raise questions about generalization. We present GenWildSplat, a feed-forward framework for sparse-view outdoor reconstruction that requires no per-scene optimization. Given unposed internet images, GenWildSplat predicts depth, camera parameters, and 3D Gaussians in a canonical space using learned geometric priors. An appearance adapter modulates appearance for target lighting conditions, while semantic segmentation handles transient objects. Through curriculum learning on synthetic and real data, GenWildSplat generalizes across diverse illumination and occlusion patterns. Evaluations on PhotoTourism and MegaScenes benchmark demonstrate state-of-the-art feed-forward rendering quality, achieving real-time inference without test-time optimization








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GenWildSplat, a fast computer vision method that can build a 3D model of a real-world place from just a few ordinary photos taken at different times, with different lighting, and even with people or cars in the way. It can also show new views of that place under different lighting—without slow, scene-by-scene training—running in about 3 seconds.
What questions did the researchers ask?
The paper focuses on simple but hard questions:
- Can we make a good 3D scene from only 2–6 photos, even if we don’t know where the cameras were exactly?
- Can we ignore “temporary stuff” like tourists or cars so the 3D model stays clean and stable?
- Can we change the lighting in the 3D scene (like day vs. evening) in a consistent, realistic way?
- Can we do all of this quickly and on new, unseen places without retraining each time?
How did they do it?
Key ideas in everyday language
- Sparse, unposed images: They use just a few pictures where the camera’s position isn’t known. Think of trying to build a model of a building from a handful of random vacation photos.
- 3D Gaussians (“fuzzy dots”): The scene is represented as many small, colored, semi-transparent blobs in 3D. Imagine filling the space with tiny soft marbles—together they form the shape and color of the scene.
- Canonical space (“neutral version”): First, they create a clean version of the 3D scene that captures the geometry (where things are) but doesn’t lock in any specific lighting. It’s like building a detailed diorama in neutral light.
- Appearance adapter (“lighting translator”): A small neural module adjusts the colors of those 3D blobs to match a target lighting. A separate light encoder turns an input image’s lighting into a short code (a “light code”), and the adapter uses that code to recolor the scene. Think of choosing a filter that matches sunrise, cloudy, or night, but applied consistently in 3D.
- Occlusion masks (“ignore the walk-ons”): A pre-trained segmentation model finds transient objects (people, cars, etc.). The system trains while ignoring these regions so the final 3D scene doesn’t include temporary clutter.
- Feed-forward (“no per-scene tuning”): The whole pipeline runs once and outputs the 3D scene immediately—no long, scene-specific training loops.
- Curriculum learning (“learn step by step”): Training is staged:
- Stage 1: Learn how to separate lighting from geometry on simple synthetic scenes.
- Stage 2: Learn general geometry and appearance across many scenes.
- Stage 3: Learn to handle occlusions (like fake people/cars) so the model ignores transients.
What does the model actually predict?
- Depth and camera parameters: It figures out how far things are and where the camera likely was for each input photo.
- 3D Gaussian attributes: Position, size, shape, transparency, and color (stored in a compact form suitable for lighting changes).
- Lighting-aware colors: The appearance adapter transforms neutral colors into ones that match a target lighting.
How are results checked?
The predicted 3D scene is “rendered” back into images (like taking new photos in a simulator). These are compared to the original pictures (but ignoring transient objects) to guide learning. They evaluate the method on two datasets:
- PhotoTourism: Internet photos of landmarks.
- MegaScenes: Harder scenes with fewer views, lots of lighting changes, and more occlusions.
What did they find and why is it important?
- Fast: GenWildSplat reconstructs scenes and renders new views in about 3 seconds.
- Works with few photos: It stays consistent and clear even with only 2–6 pictures.
- Controls lighting: It can generate novel views under different lighting (e.g., brighter, dimmer), keeping the 3D scene stable.
- Handles occlusions: It ignores people, cars, and other temporary blockers during training, avoiding messy artifacts.
- Better generalization: On tough datasets like MegaScenes, it outperforms previous methods that need hours of per-scene optimization. It produces cleaner geometry and more realistic, view-consistent results.
- Cross-scene lighting transfer: It even applies lighting from one scene to another, showing the model learned a reusable “lighting understanding,” not just memorized examples.
This matters because it makes building 3D scenes from real-world photos much more practical: faster, more reliable, and usable in messy, everyday conditions.
What could this lead to?
- AR/VR and games: Fast capture of real places with controllable lighting, useful for immersive experiences.
- Mapping and navigation: Quick 3D reconstructions of outdoor locations from casual photos.
- Virtual tourism and film: Consistent, relightable scenes without long setup times.
Limitations to keep in mind
- Unseen areas: With very few photos, parts of the scene you never saw may be incomplete.
- Extreme viewpoints: Views far from the inputs can show artifacts.
- Indoor scenes: Performance drops if occlusion masks are imperfect.
- Shadows/physical relighting: It doesn’t fully model realistic shadows or physics-based light interactions yet.
Bottom line
GenWildSplat shows that with smart training and the right scene representation (3D Gaussians), we can quickly build clean, controllable 3D models from everyday, imperfect photos—no slow tweaks per scene—bringing real-time 3D reconstruction closer to real-world use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored, framed to guide follow-up research:
- Physical lighting modeling
- No explicit, physically grounded lighting representation (e.g., HDR environment maps, sun position, sky model); the 16-D “light code” is uninterpretable and not mapped to physical parameters.
- No modeling of cast shadows, interreflections, or specular highlights; SH color modulation cannot capture high-frequency or view-dependent illumination effects.
- Unclear disentanglement between view-dependent appearance (BRDF) and illumination; SH coefficients likely conflate reflectance and lighting.
- Controllability and user-facing interfaces for appearance
- Target lighting is specified only via codes inferred from other images; no interfaces to specify lighting by text prompts, parametric sky/sun controls, or explicit environment maps.
- Lack of a learned mapping from the latent light code to interpretable/controllable lighting spaces (e.g., inverse rendering of an HDRI).
- Occlusions and transients
- Reliance on 2D off-the-shelf segmentation (COCO classes) misses many transient categories, thin structures, reflective/translucent objects, and scene-specific dynamics (e.g., flags, fountains, vegetation).
- Binary masks ignore uncertainty; no learning of per-pixel or per-Gaussian occlusion probabilities or cross-view mask consistency.
- Masking removes transients but does not reconstruct the occluded static background; no inpainting of unseen content behind occluders in 3D.
- Failure modes indoors and under mask errors are acknowledged, but no mitigation strategies (e.g., robust training, uncertainty weighting, joint transient discovery) are explored.
- Geometry, poses, and supervision
- Depth and pose are supervised by pseudo-labels (VGGT); sensitivity to label noise, bias, and OOD poses/intrinsics is not analyzed.
- No joint refinement of camera parameters (e.g., differentiable bundle adjustment) or probabilistic pose estimation to handle uncertainty.
- Lack of ground-truth geometric evaluation (e.g., depth/normal error, reconstructed mesh accuracy) beyond image metrics.
- “Canonical” representation and disentanglement
- The canonical color/geometry definition is unspecified and not directly supervised; risk of leakage of lighting into geometry or “canonical” albedo.
- No explicit albedo/shading decomposition; no cycle or multi-light consistency constraints to stabilize canonical reflectance.
- Open question: how to enforce scene- and view-invariant canonical properties with provable identifiability under sparse multi-lighting data?
- Spatially varying illumination
- Global light codes cannot capture spatially varying illumination (local shadows, skylight gradients, area lights); per-Gaussian modulation conditioned on a single global code is insufficient.
- No modeling of light visibility or shadow transport from estimated light sources/sky models; no path-based or visibility-aware approximation.
- Scaling with number of views and scene size
- Behavior beyond 2–6 views is unclear: does performance saturate or improve with more images? How does inference time and Gaussian count scale for larger scenes?
- No analysis of memory footprint, Gaussian budget, deduplication strategies, or scalability to city-scale/long-range scenes.
- Generalization limits and domain coverage
- Training is outdoor-centric; failures indoors are noted but not quantitatively characterized or addressed (e.g., mixed lighting, strong specularities).
- No evaluation under extreme conditions (nighttime, harsh weather, strong seasonal changes) or highly dynamic scenes (crowds, traffic).
- Cross-dataset generalization is limited (PhotoTourism: 3 scenes; curated 20-scene MegaScenes subset); broader and more diverse evaluations are missing.
- Curriculum learning and synthetic relighting
- Synthetic relighting (DiffusionRenderer) may introduce biases/artifacts; effect on learned priors and real-world generalization is not quantified.
- Ablations isolate component presence/absence but do not test alternative curricula, data scales, or the dependency on each stage’s dataset quality.
- No study of failure modes or identifiability when training end-to-end on large real data with weak priors.
- Evaluation methodology
- Image-space metrics (PSNR/SSIM/LPIPS) lack assessment of 3D consistency (e.g., cross-view photometric consistency, silhouette consistency, depth reprojection).
- No metrics for transient handling quality (e.g., fraction of transients suppressed vs. static content preserved) or for background recovery behind occluders.
- No relighting accuracy evaluation relative to a target lighting ground truth (when available) or human studies on realism/control.
- Post-processing dependence
- Visualizations use SyncFix post-processing; the magnitude of its contribution and potential artifacts are not quantified.
- Open: can the core model match reported quality without post-processing, and under what settings?
- Camera model and intrinsics
- Lens distortion and rolling shutter effects are not modeled; robustness to varied intrinsics and mobile camera artifacts is untested.
- Open: incorporate distortion parameters and uncertainty into the pose/geometry heads.
- Uncertainty, reliability, and active capture
- No predictive uncertainty over geometry, appearance, or rendering; no calibration or failure detection for OOD inputs.
- No framework for active view planning to reduce uncertainty or fill unseen regions under a time/view budget.
- Temporal and 4D dynamics
- The approach removes transients rather than modeling time-varying scenes; no 4D extension to represent dynamics with consistent geometry/appearance over time.
- Open: jointly reconstruct static scene and dynamic actors with consistent trajectories and appearance.
- Reflectance and material modeling
- Materials are not modeled explicitly (BRDF/BSDF); specular/transparent surfaces and complex reflectance remain challenging.
- Open: integrate neural reflectance fields or learned microfacet models compatible with Gaussian splats.
- Interface to downstream tasks
- No mesh extraction, semantic labeling of the 3D scene, or support for physically based renderers; limits applicability to AR/robotics requiring metric geometry.
- Open: pipeline to convert Gaussians to watertight meshes with material estimates and to export lighting for standard renderers.
- Resource and performance profiling
- Inference time is reported (3 s on A6000) without details on image resolution, Gaussian count, VRAM, throughput across scenes, or performance on commodity/mobile hardware.
- Open: comprehensive profiling and model compression/acceleration for deployment.
- Fairness and baselines
- Comparisons rely on custom baselines (e.g., DiffusionRenderer+AnySplat); lack of head-to-head with strong feed-forward pose-free methods that incorporate lighting/occlusions if/when available.
- Open: standardized benchmarks for sparse, in-the-wild, multi-illumination reconstruction with agreed-upon protocols and data splits.
- Failure cases requiring targeted remedies
- Missing geometry in unobserved regions and “double-geometry” at far test views are noted but not addressed with priors, hallucination modules, or geometric regularizers.
- Open: integrate generative geometry priors (e.g., diffusion priors) and cross-view regularization to mitigate sparsity-induced failures.
- Hyperparameters and design choices
- Light code dimensionality (16), SH order (L=4), and voxel/merging thresholds are not justified; no sensitivity or ablation on these choices.
- Open: principled selection or learned adaptation of these parameters to scene complexity and lighting variability.
Practical Applications
Overview
Below are practical, real-world applications that follow directly from the paper’s findings and innovations (feed-forward sparse-view 3D reconstruction from unposed images; appearance adapter for lighting control; transient-object masking; curriculum training for generalization). Each item highlights sectors, example tools/products/workflows, and assumptions/dependencies that may affect feasibility.
Immediate Applications
- Generalizable 3D from few outdoor photos for AR anchoring and previews Sectors: AR/VR, software, mapping Workflow/product: Upload 2–6 photos → GenWildSplat produces a navigable 3D Gaussian scene in ~3s → export to USD/PLY/gsplat-compatible formats for AR anchors or quick previews; integrate as a plug‑in in Unity/Unreal or as a Blender add‑on. Dependencies/assumptions: Works best outdoors; uses VGGT-like pose priors and YOLOv8‑style segmentation; GPU inference (e.g., server-side); incomplete geometry in unseen regions.
- Tourism and cultural-heritage recon from public photo collections (tourists filtered out) Sectors: culture/heritage, education, media Workflow/product: Curate internet images of a site → run feed‑forward reconstruction with transient-masking to produce a “clean” static model for virtual tours or museum exhibits. Dependencies/assumptions: Licensing/rights for public imagery; segmentation must cover common transient classes; limited shadow/relighting realism.
- Rapid exterior scene capture for real estate and hospitality Sectors: real estate, hospitality, marketing Workflow/product: Agents capture 2–6 smartphone photos (exteriors, courtyards, gardens) → instant 3D tour with a time‑of‑day “look” using the appearance adapter (e.g., golden hour vs mid‑day). Dependencies/assumptions: Outdoor bias; on-device likely too heavy today (use cloud); appearance control is non-physical (no cast shadows).
- VFX and game dev: fast plate or reference-set reconstruction from limited stills Sectors: film/VFX, gaming Workflow/product: Set-reference photos → quick 3D proxy assets for layout and pre‑viz; appearance adapter used to harmonize looks across shots; export Gaussians or convert to meshes via existing pipelines. Dependencies/assumptions: Not fully production‑grade relighting; may need artist cleanup for distant viewpoints or sparse coverage.
- News and incident reporting: scene-overview from a handful of user photos Sectors: media, public safety Workflow/product: Aggregate 2–6 verified photos → generate a navigable 3D overview with people/vehicles masked → embed in news web pages for spatial context. Dependencies/assumptions: Verification and chain-of-custody policies; limited accuracy in poorly covered areas; avoid indoor use.
- Outdoor robotics and inspection: quick map priors in dynamic, crowded places Sectors: robotics, utilities/infrastructure Workflow/product: Robot receives sparse opportunistic images (telephoto, social, or onboard) → GenWildSplat produces a static prior map robust to crowds → seed SLAM or planning with more consistent geometry. Dependencies/assumptions: Outdoor scenarios; integrate with SLAM/visual odometry; no dynamic object tracking; geometry incomplete behind occluders.
- Geospatial/3D mapping pipelines: fast, human-in-the-loop pre-models Sectors: mapping, GIS Workflow/product: Use sparse-view feed-forward recon for pre-alignment and QC before expensive MVS/photogrammetry; appearance adapter for consistent look across captures taken months apart. Dependencies/assumptions: Still need high-density capture for survey-grade deliverables; pose quality depends on VGGT-like priors.
- Education and outreach in 3D vision and graphics Sectors: academia, education Workflow/product: Classroom/lab exercises: students collect few outdoor images → build and explore controllable 3D scenes in seconds; use for visualization of geometry vs appearance disentanglement. Dependencies/assumptions: GPU compute availability; limited indoor generalization.
- API-as-a-service for “3D from a handful of photos” with time-of-day slider Sectors: software, platforms Workflow/product: REST/gRPC service: POST images (and optionally a target “lighting image”) → returns 3D Gaussians and rendered views under chosen appearance; front-end uses gsplat-based web viewers. Dependencies/assumptions: Privacy handling for uploads; clear UX on limitations (sparse geometry, non-physical relighting).
- Privacy-by-design reconstruction of public spaces Sectors: policy, civic tech, smart cities Workflow/product: Municipalities produce public 3D models of parks/plazas while masking people/vehicles; publish privacy-preserving digital twins. Dependencies/assumptions: Segmentation quality determines privacy effectiveness; governance for use of citizen imagery; outdoor focus.
Long-Term Applications
- Photorealistic relighting with shadows and reflections for virtual production Sectors: film/VFX, gaming, XR Concept: Extend the appearance adapter with physically grounded light transport (e.g., estimated BRDFs, shadow casting) to support true time-of-day changes and on-set virtual lighting. Dependencies/assumptions: New training data with multi-view, multi-light annotations; hybrid Gaussian+neural light transport; more compute.
- Indoor-ready sparse-view recon with robust transient handling Sectors: AR for interiors, AEC, retail Concept: Improve segmentation and occlusion reasoning for cluttered indoor scenes; handle glass, mirrors, and thin structures; augment training with indoor curricula. Dependencies/assumptions: Better indoor datasets and masks; enhanced priors for camera/depth in low-texture/low-light conditions.
- Completion and consistency for far-apart viewpoints and unseen regions Sectors: mapping, robotics, creative tools Concept: Fuse generative priors with Gaussians to hallucinate plausible but flagged geometry beyond observed views; uncertainty-aware rendering for editorial use. Dependencies/assumptions: Reliability and bias control for generative completion; clear provenance and uncertainty indicators.
- Real-time on-device reconstruction on mobile and edge Sectors: consumer mobile, AR glasses, field inspection Concept: Optimize model size and inference (quantization, distillation) to run in seconds on smartphones/edge GPUs; enable in-situ AR anchoring from a few photos. Dependencies/assumptions: Model compression and efficient rasterization; battery/thermal constraints.
- 4D scene capture: joint modeling of structure and dynamics Sectors: robotics, sports analytics, security Concept: Extend static/transient separation to continuous dynamics (people, vehicles) to build dynamic scene models from sparse asynchronous images. Dependencies/assumptions: Temporal priors and tracking; privacy and ethics for dynamic subjects.
- High-confidence civil/engineering workflows from sparse imagery Sectors: AEC, infrastructure, insurance Concept: Combine sparse-view feed-forward recon with downstream metrology (LiDAR, photogrammetry) to flag gaps and guide where to capture more data; accelerate claims or site assessments. Dependencies/assumptions: Traceable accuracy metrics and QA; integration with survey-grade pipelines.
- Web-scale 3D from social media for time-aware city models Sectors: smart cities, urban planning, heritage Concept: Aggregate massive public photo streams over time → build evolving 3D models with consistent appearance controls for temporal studies. Dependencies/assumptions: Data governance, licensing, and privacy; robust deduplication and spam filtering; compute scale-out.
- Curriculum-driven cross-domain training frameworks Sectors: academia, foundation models for 3D Concept: Use the paper’s staged curriculum (appearance → multi-scene → occlusions) as a general recipe to train 3D models that handle domain shifts (seasonality, weather, crowds). Dependencies/assumptions: Synthetic-to-real transfer improvements; standardized benchmarks with variable lighting/occlusions.
- Policy templates for public 3D recon projects Sectors: government, standards bodies Concept: Best-practice guidelines requiring transient-removal and privacy-preserving outputs when using public imagery for municipal 3D models; disclosure standards about uncertainty and edits. Dependencies/assumptions: Cross-agency collaboration; legal frameworks for image rights and personal data.
- Creative tools for scene-level appearance transfer and editing Sectors: creator economy, design software Concept: End-user controls to stylize or transfer lighting between outdoor scenes consistently across views; integrate with Photoshop/Blender side panels. Dependencies/assumptions: UX for non-technical users; physics-inspired controls to avoid uncanny results.
- Training data augmentation for vision models with controllable appearance Sectors: ML/AI, autonomy Concept: Generate multi-appearance renderings from sparse captures to expand datasets for detection/segmentation in different lighting conditions (day/night, seasonality). Dependencies/assumptions: Non-physical relighting may affect downstream model generalization; need empirical validation.
Notes on feasibility across applications:
- The method currently excels in outdoor scenes with limited, sparse photos and significant lighting/transient variability. Indoor scenes and physically accurate relighting are open challenges.
- Inference times (~3 seconds) were demonstrated on a high-end GPU; immediate deployments likely require server/cloud inference.
- Transient-object masking depends on the coverage and quality of pre-trained segmentation; policies and audits are needed for privacy-critical use cases.
- Where safety or metrology is required, pair with additional sensors or reconstruction stages and communicate uncertainty clearly.
Glossary
- AnySplat: A feed-forward method that predicts 3D Gaussian representations from multiple unposed images in a single pass. "Our method builds upon AnySplat~\cite{jiang2025anysplat}, a feed-forward framework that reconstructs 3D scenes as Gaussian primitives from multiple input images in a single pass."
- Appearance adapter: A module that modulates canonical Gaussian colors to match a target lighting condition. "An appearance adapter modulates appearance for target lighting conditions"
- Canonical representation: A lighting-agnostic 3D description disentangled from appearance that captures unified scene geometry. "The resulting set of attributes defines a canonical representation that captures a unified scene geometry disentangled from illumination."
- Canonical space: A shared, lighting-independent coordinate space in which 3D Gaussians are predicted. "Given unposed internet images, GenWildSplat predicts depth, camera parameters, and 3D Gaussians in a canonical space using learned geometric priors."
- Camera extrinsics: Parameters describing a camera’s pose (orientation and position) relative to the world. "h_C estimates camera intrinsics K and extrinsics E"
- Camera intrinsics: Parameters describing a camera’s internal characteristics (e.g., focal length, principal point). "h_C estimates camera intrinsics K and extrinsics E"
- COLMAP: A structure-from-motion and multi-view stereo pipeline commonly used for estimating camera poses. "Methods rely on COLMAP for pose estimation, which fails under sparsity."
- Curriculum learning: A staged training strategy that introduces tasks progressively to stabilize optimization. "Through curriculum learning on synthetic and real data, GenWildSplat generalizes across diverse illumination and occlusion patterns."
- CUDA pipeline: A GPU-accelerated rendering path used here for real-time Gaussian rasterization. "Gaussian Splatting (3DGS)~\cite{kerbl20233d} represents scenes with explicit 3D Gaussian primitives, enabling realâtime rasterization via a CUDA pipeline."
- Differentiable rasterizer: A rendering component whose gradients can be backpropagated through for learning. "However, directly decoding these canonical Gaussians into a novel view via a differentiable rasterizer leads to multi-view inconsistencies."
- DiffusionLight-Turbo: A diffusion-based lighting estimation method used to provide environment maps. "which uses environment maps from DiffusionLight-Turbo."
- DiffusionRenderer: A diffusion-based module for relighting or harmonizing illumination across views. "DiffusionRenderer+AnySplat integrates AnySplat with DiffusionRenderer"
- Environment map: A representation of scene illumination (often HDR) used for lighting and relighting. "which uses environment maps from DiffusionLight-Turbo."
- Feed-forward: Inference performed in a single pass without per-scene test-time optimization. "We present GenWildSplat, a feed-forward framework for sparse-view outdoor reconstruction that requires no per-scene optimization."
- Gaussian primitives: Explicit 3D Gaussian elements (position, scale, rotation, color, opacity) used to represent scenes. "represents scenes with explicit 3D Gaussian primitives"
- Gaussian Splatting (3DGS): A real-time rendering technique that models scenes with 3D Gaussians and splats them to images. "Gaussian Splatting (3DGS)~\cite{kerbl20233d} represents scenes with explicit 3D Gaussian primitives"
- Geometric priors: Learned constraints or biases about 3D structure that guide predictions from sparse views. "using learned geometric priors."
- Latent space: A compact, learned feature space capturing complex factors like lighting. "represents it in a compact latent space."
- Light code: A compact embedding that encodes lighting/appearance conditions for modulation. "We parameterize lighting information using a light code estimated by a light encoder"
- Light encoder: A network that extracts the light code from an image. "estimated by a light encoder"
- MegaScenes: A challenging dataset with diverse lighting, sparse views, and occlusions for evaluating generalization. "The MegaScenes dataset poses significant challenges for 3D reconstruction due to wide variations in viewpoints and lighting."
- NeRF (Neural Radiance Fields): A neural implicit representation for view synthesis that often requires optimization per scene. "Prior NeRF~\cite{chen2022hallucinated, rudnev2022nerf, sun2022neural} and Gaussian Splatting~\cite{kulhanek2024wildgaussians, xu2024wild, dahmani2024swag, wang2024we, kaleta2025lumigauss, wang2025look} methods rely on per-scene optimization and dense views"
- Novel View Synthesis (NVS): Generating images from viewpoints not present in the input set. "Optimizationâbased Novel View Synthesis (NVS) reconstructs 3D scenes from 2D images for novel viewpoint generation."
- Occlusion masks: Binary masks indicating transient/dynamic regions to exclude from supervision. "It produces explicit occlusion masks that guide our model to ignore transient regions during supervision"
- Per-scene optimization: Scene-specific fine-tuning at test time, often slow and impractical for real-time use. "requires no per-scene optimization."
- Perceptual loss: A feature-space loss (e.g., using pretrained networks) to encourage perceptual similarity. "uses a perceptual loss weight of "
- PhotoTourism: A dataset of internet photo collections commonly used for evaluating multi-view reconstruction. "Evaluations on PhotoTourism and MegaScenes benchmark demonstrate state-of-the-art feed-forward rendering quality"
- Pose-aware: Methods that assume known/calibrated camera poses at inference time. "Poseâaware methods use calibrated poses"
- Pose-free: Methods that estimate camera poses jointly while reconstructing views. "Poseâfree methods jointly estimate poses and novel views"
- Pseudo-labels: Labels generated by a pretrained model used as supervision in lieu of ground truth. "uses VGGT's pretrained model to generate pseudo-labels for depth and camera poses."
- Rasterization (diff. splatting): Projecting Gaussians to images; here differentiable splatting enables learning from image comparisons. "are rasterized via diff. splatting:"
- Semantic segmentation: Pixel-wise classification used to identify dynamic/transient objects. "semantic segmentation handles transient objects."
- Self-supervised training: Learning without explicit ground-truth targets by reconstructing inputs and comparing predictions. "enabling self-supervised training without test-time optimization."
- Spherical harmonics (SH): A basis for representing view-dependent color/lighting; used as per-Gaussian coefficients. "appearance-dependent spherical harmonic (SH) coefficients "
- State-of-the-art (SOTA): The best reported performance among contemporary methods. "demonstrate state-of-the-art feed-forward rendering quality"
- Transformer backbone (VGGT): A transformer-based feature extractor grounded in geometry for multi-view processing. "A VGGT transformer backbone extracts multi-view features"
- Transient occluders: Moving objects (e.g., people, vehicles) that block views and should not be reconstructed as static geometry. "handheld captures contain transient occluders like tourists or vehicles that must be excluded"
- Unposed images: Images without known camera poses; the system estimates poses during inference. "Given unposed internet images"
- View-consistent rendering: Maintaining consistent appearance and geometry across multiple viewpoints. "yielding photorealistic, view-consistent results."
- Visibility weighting: Reweighting losses using masks to suppress gradients in transient/dynamic regions. "We apply visibility weighting "
- Voxelization: Discretizing space into voxels to merge or compact per-pixel Gaussians. "AnySplat voxelizes the scene"
- YOLOv8 Segmentation: A segmentation model used to detect and mask transient objects. "For occlusion detection, we use YOLOv8 Segmentation~\cite{yolov8_ultralytics}"
Collections
Sign up for free to add this paper to one or more collections.