- The paper introduces MemCoE, a cognition-inspired two-stage optimization that separates memory guideline induction from policy optimization to enhance personalization.
- It leverages contrastive textual feedback and RL-based Group Relative Policy Optimization to efficiently manage memory evolution in long, multi-turn dialogues.
- Experimental results show improved accuracy, long-term preference retention, and scalability compared to static heuristics and other RL-based memory agents.
Cognition-Inspired Two-Stage Optimization for Evolving User Memory in LLM Agents
Motivation and Problem Statement
LLM agents require the capacity to maintain and evolve long-term user memories for effective personalization in multi-turn dialogue and agentic interaction. Context-window limitations of LLMs preclude direct retention of long histories, while existing memory augmentation strategies—whether static heuristics or reinforcement-learning (RL) based—fail to robustly capture evolving user preferences over extended interactions or under noisy, non-stationary inputs. Static rule-based schemes lack adaptability, and RL approaches are bottlenecked by sparse supervision, large action spaces, and instabilities in long-horizon policy optimization. Inspired by memory schema theory and neuroanatomical findings on the division of labor between prefrontal cortex (schema selection/organization) and hippocampus (episodic encoding), this paper introduces MemCoE: a two-stage optimization paradigm with distinct phases for learning "how" memory should be structured and "what" to store at each point in the dialogue trajectory.
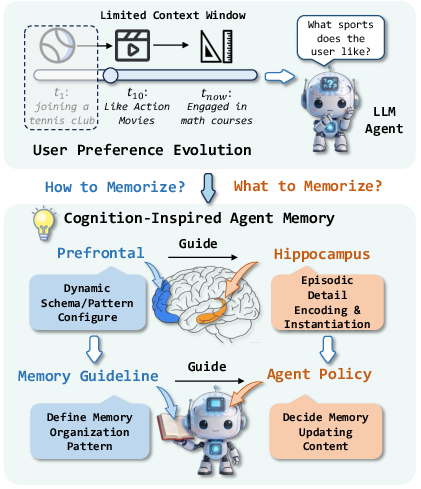
Figure 1: With a limited context window (top), the agent cannot track preferences; by decoupling memory guideline (prefrontal-like) and episodic agent memory (hippocampal-like) (bottom), organization and content updating are separated for higher fidelity personalization.
Method: MemCoE Two-Stage Optimization
MemCoE operationalizes the cognitive analogy via a split architecture:
- Memory Guideline Induction (MGI): Treats the memory update instruction prompt as an optimizable natural-language parameter encoding memory organization schemas. Using a labeled dataset of dialogue-query pairs, contrastive feedback over generated memory-augmented trajectories is converted into batch-aggregated "textual gradients" driving prompt/token optimization. This produces a domain-agnostic, explicit, and transferable memory guideline S⋆.
- Guideline-Aligned Memory Policy Optimization (GMPO): Conditioned on S⋆, this stage uses RL (specifically Group Relative Policy Optimization, GRPO) to induce a memory evolution policy maximally aligned with both the learned guideline and downstream answer correctness, solving for "what" content is extracted, retained, or forgotten in each round via more granular, guideline-aligned and answer-based dense rewards.
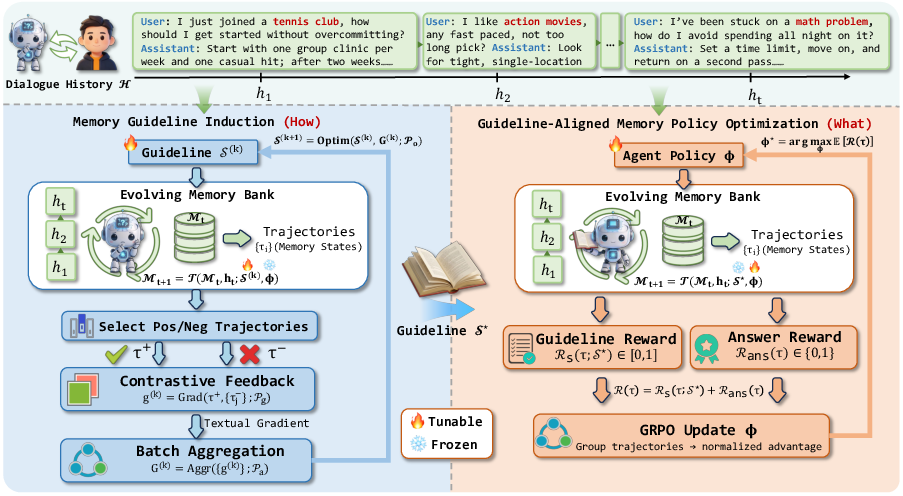
Figure 2: The two-stage framework: first, Memory Guideline Induction develops a robust textual guideline; second, GMPO aligns memory policy evolution to this fixed organizing principle via RL over memory-augmented trajectories.
Experimental Validation
MemCoE is evaluated on three personalization memory benchmarks: PersonaMem (long-term preference evolution), PrefEval (explicit/implicit preference following), and PersonaBench (heterogeneous and noisy user grounding). Metrics are task dependent: accuracy for PersonaMem and PrefEval, F1 for PersonaBench.
Empirically, MemCoE demonstrates superior performance relative to both classical RAG, static heuristics, and state-of-the-art RL-based agents (MemAgent, MEM-α) across all settings—robustness to noise, out-of-domain generalization, and efficient scaling with longer histories are explicitly shown.
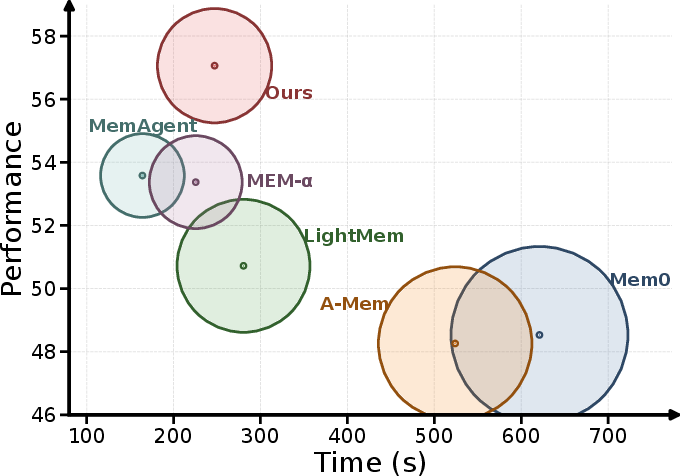
Figure 3: Efficiency/performance tradeoff on PersonaMem (32K): MemCoE achieves highest accuracy within a regime of comparatively low runtime variance.
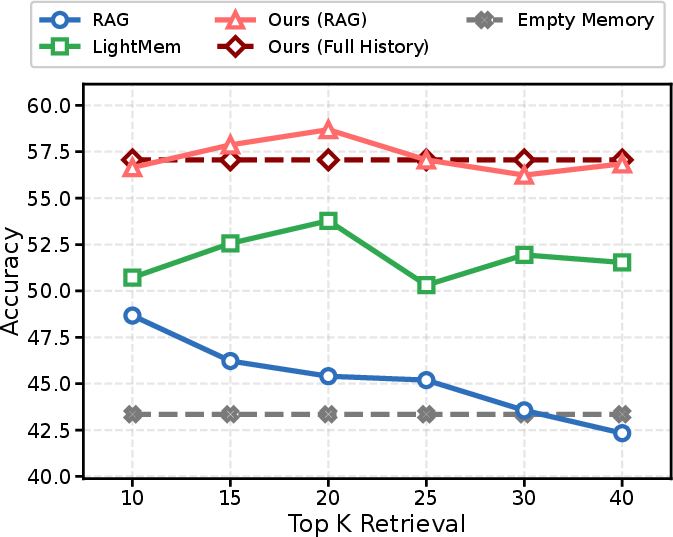
Figure 4: Retrieval Top-K analysis: MemCoE outperforms baselines across all retriever settings, with optimality at K=20 due to effective filtering during memory evolution.
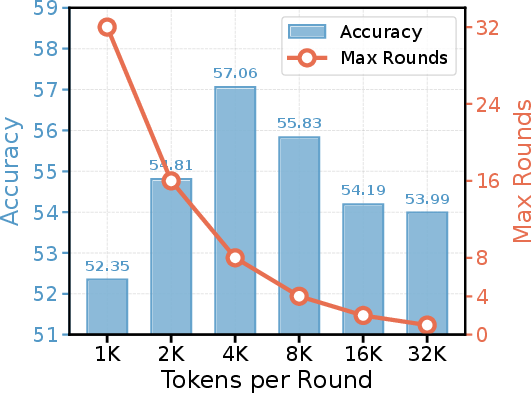
Figure 5: Impact of tokens per memory evolution round: performance is maximized at an intermediate token budget, which balances update frequency and context complexity.
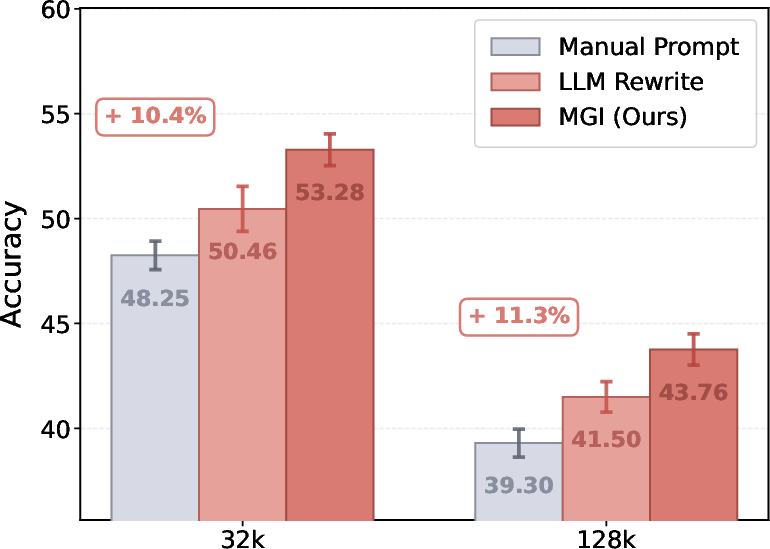
Figure 6: Quality of prompt/guideline directly affects PersonaMem accuracy, with the full MemCoE induction pipeline yielding consistent and significant gains over manual and standard LLM-based prompt optimization.
Preference Retention and Robustness Analysis
Long-horizon retention and resilience to preference forgetting/drift are crucial for agentic personalization. Multi-round analysis (PrefEval, explicit tracking) shows that MemCoE exhibits much slower degradation (from 100% to ≈74% over 10 rounds) in preference retention relative to RL memory agents (which rapidly fall to ≈51%):
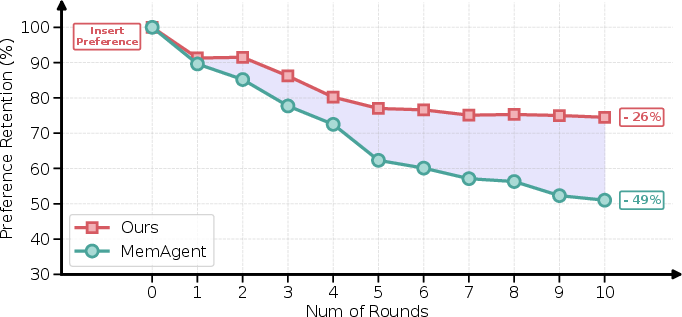
Figure 7: Preference retention curves during multi-round memory evolution: MemCoE retains preference-relevant memory significantly more robustly than RL-based baselines.
Error decomposition reveals most remaining errors are due to memory evolution (rather than answer generation), validating the focus on optimizing the update stage as the primary bottleneck:
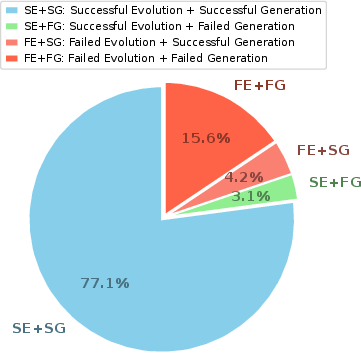
Figure 8: Error analysis: predominant failure mode is at the memory evolution stage, supporting priority of improvement efforts for upstream retention.
Scalability
Evaluation on longer histories (PersonaMem 128K+) indicates sublinear memory bank scaling and stable memory evolution time, confirming the framework is computationally tractable even for million-token corpora:
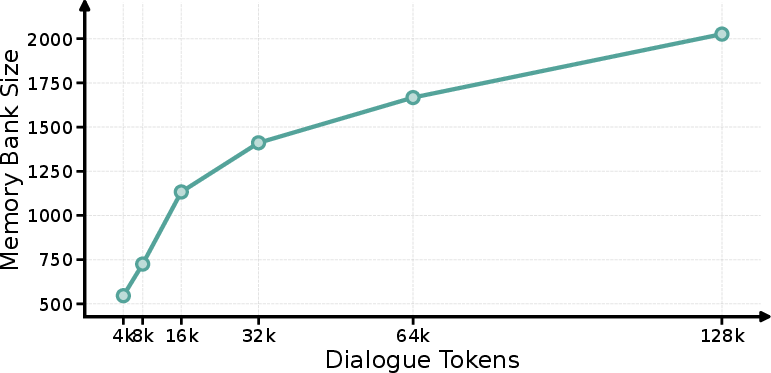
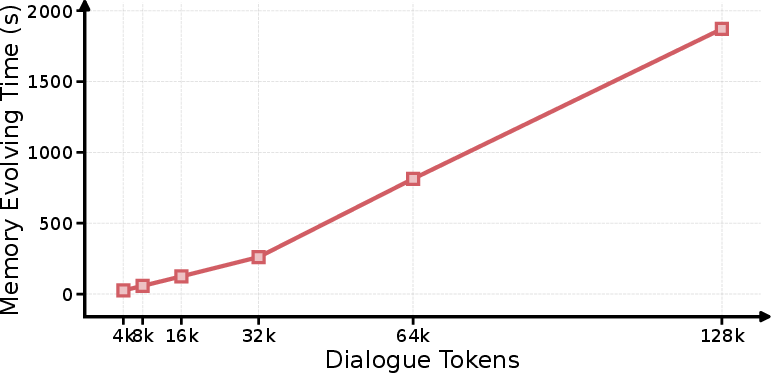
Figure 9: As dialogue context grows, memory bank size and evolving time remain bounded and predictable.
Cross-LLM Transferability and Ablation
Guidelines induced by MemCoE are empirically shown to transfer successfully across diverse backbone LLMs (Qwen2.5-7B, gpt-4o-mini, Gemini-2.5-flash, GPT-5) without retraining RL policies, underlining that the organizational principle is robust and agnostic to underlying model specifics.
Ablations confirm that both contrastive textual feedback in MGI and guideline-aligned RL are essential. Removing either stage significantly degrades performance, and ablation of all structure reduces results to baseline RL-memory agent levels.
Practical and Theoretical Implications
MemCoE presents a paradigm shift in agentic memory modeling for LLM systems—by separating the "how" (organizational schema) and "what" (content update) with explicit, optimizable interfaces. This supports:
- Sample-efficient RL: Dense, process-level rewards (rather than outcome-only) yield more stable updates and require fewer samples.
- Transferable policies: Textual guideline abstraction allows consistent behavior independent of backbone LLM.
- Efficient scaling: Structured, evidence-bounded updates enable tractable scaling to long histories and noisy data with minimal memory bloat.
- Personalization robustness: Stronger long-temporal retention and explicit conflict handling facilitate trustworthy adaptive behavior, necessary for safety-critical or privacy-sensitive personalization.
Potential future extensions include guidelines adaptable to multi-objective trade-offs (e.g., stability vs. plasticity, brevity vs. informativeness), integration with graph-structured or hierarchical memory indices, and joint optimization with user-alignment or privacy objectives.
Conclusion
MemCoE introduces and validates a cognition-inspired, two-stage optimization pipeline for LLM agent memory: first learning robust, generalizable organization schemas via batch textual contrast, then aligning content evolution policies under dense, guideline-aware reward with RL. Across benchmarks, MemCoE achieves leading accuracy, efficiency, and robustness to long-horizon noise and distributional drift. This separation of schema induction and episodic content updating marks a practical advance in memory-augmented dialogue systems, and is directly extensible to next-generation agentic architectures.