- The paper demonstrates that residual connections ensure cross-layer gradient coherence, which is essential for geometric continuity.
- It shows that symmetry-breaking nonlinearities, not just any nonlinearity, anchor and preserve the weight coordinate frames across layers.
- Empirical analyses on MLPs and transformers highlight practical implications for model compression, parameter sharing, and mitigating rotational drift.
Emergence of Geometric Continuity in Deep Neural Networks: Mechanistic Analysis and Implications
Introduction
The work "Why Geometric Continuity Emerges in Deep Neural Networks: Residual Connections and Rotational Symmetry Breaking" (2605.04971) addresses a significant and previously unresolved phenomenon in the weight geometry of deep neural networks (DNNs), especially in modern residual architectures such as transformers. Empirical analyses of trained models have consistently revealed that principal singular vectors of adjacent layers' weight matrices are highly aligned, an effect termed geometric continuity. This study provides a systematic, mechanistic dissection of the architectural and dynamical underpinnings for the emergence of geometric continuity, distinguishing the orthogonal contributions of residual connections and explicit symmetry-breaking nonlinearities.
Mechanisms Behind Geometric Continuity
Through controlled ablation studies on multilayer perceptrons (MLPs) and transformers, the paper identifies two nontrivial, necessary conditions for the emergence and stability of geometric continuity:
- Residual connections supply cross-layer gradient coherence: Residual pathways enforce the propagation of similar error signals across layers, thereby ensuring that the gradients and, consequently, the weight updates are spatially aligned throughout the depth of the network. Empirically, this gradient coherence is observable from initialization—long before weights accumulate meaningful structure.
- Symmetry-breaking nonlinearities anchor coordinate frames: Nonlinear activation functions (e.g., ReLU, GELU, SiLU), or normalization operations like LayerNorm, restrict the otherwise vast set of rotational symmetries in deep linear or near-linear systems. Specifically, conventional activations reduce the symmetry group from SO(d) down to (essentially) permutations and rescalings, fixing the coordinate system and preventing post-training rotation drift in the weights. In the absence of symmetry breaking, weight structures formed via gradient dynamics are freely rotated by shallow valleys in the optimization landscape and geometric continuity is lost over the course of training.
The sequential action of these mechanisms is essential: residual pathways endow the gradient with directional coherence, but only in the presence of symmetry-breaking does this coherence accumulate and persist as geometric continuity in weight space.
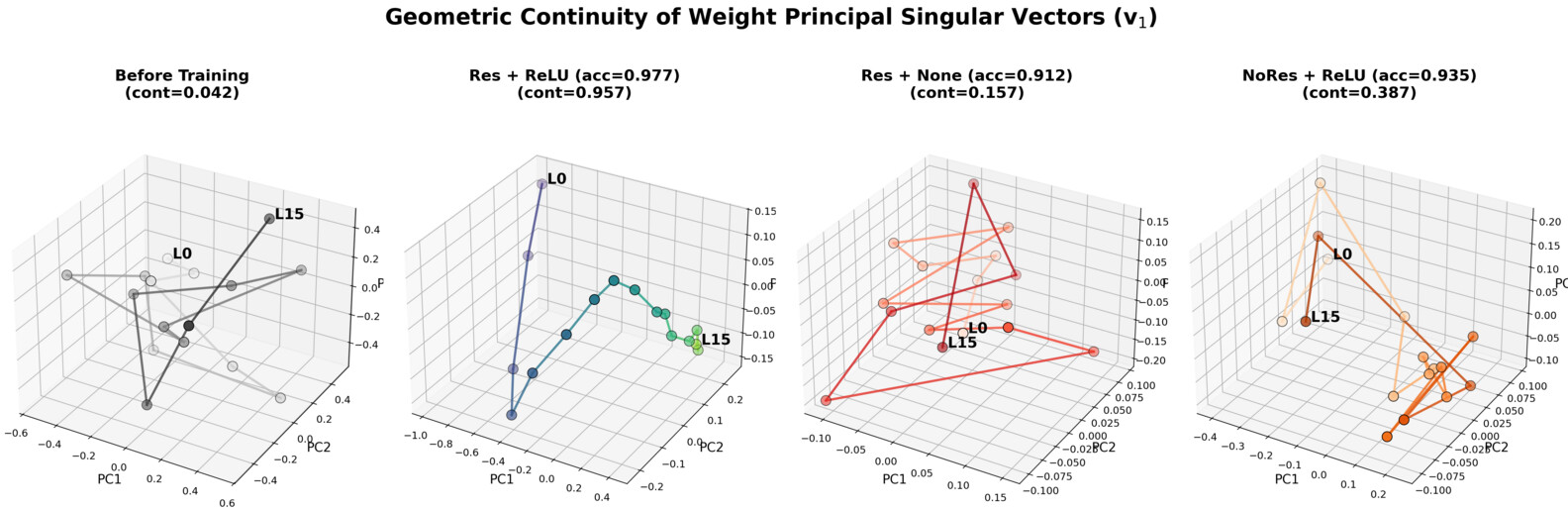
Figure 1: Geometric continuity of weight v1 across layers in a 16-layer residual MLP; continuity emerges only when both residual connections and activation are present.
Role of Nonlinearity and Symmetry Breaking
A critical and novel claim is that nonlinearity alone is insufficient for the emergence of geometric continuity. The paper introduces a rotation-equivariant, nonlinear activation ("radial activation": σrad(x)=x⋅tanh(∥x∥)), which preserves the SO(d) symmetry. Despite being nonlinear, models with this activation fail to accumulate geometric continuity, confirming that the essential ingredient is not generic nonlinearity but rather explicit symmetry breaking.
Additionally, ablations demonstrate distinct roles for activations and normalization procedures: activations tend to concentrate continuity in the leading singular direction, while normalization distributes continuity more broadly across multiple singular vectors.
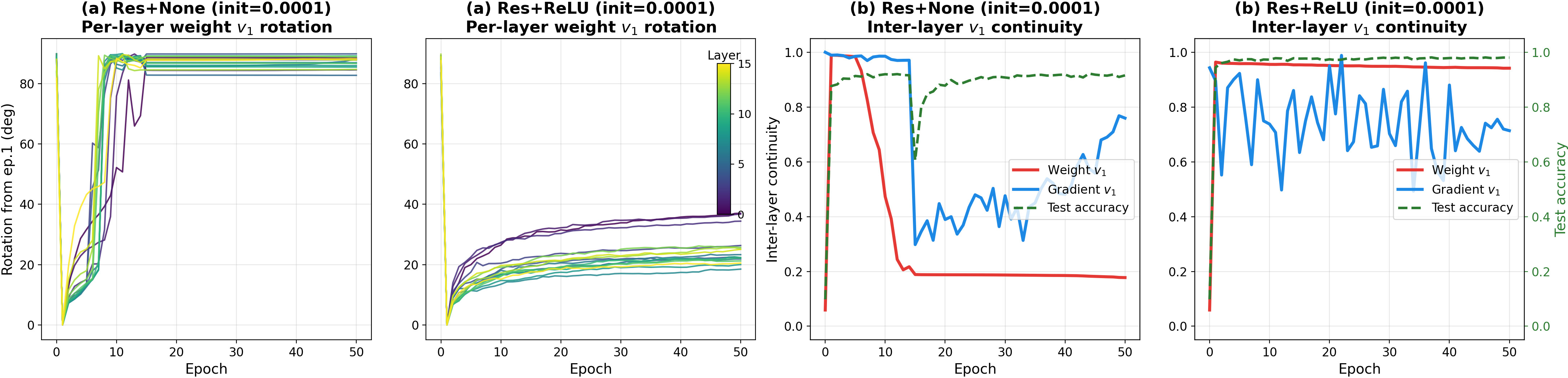
Figure 2: In the absence of explicit activation, inter-layer rotational drift erases geometric continuity, as evidenced by a collapse in singular vector alignment.
The analysis reveals that the leading singular vector of each layer's weight matrix converges to the principal direction of its cumulative gradient over training. This direct relationship between gradient accumulation and emergent weight structure highlights that continuity is primarily a consequence of optimization geometry, rather than an idiosyncratic artifact of particular datasets or architectural details.
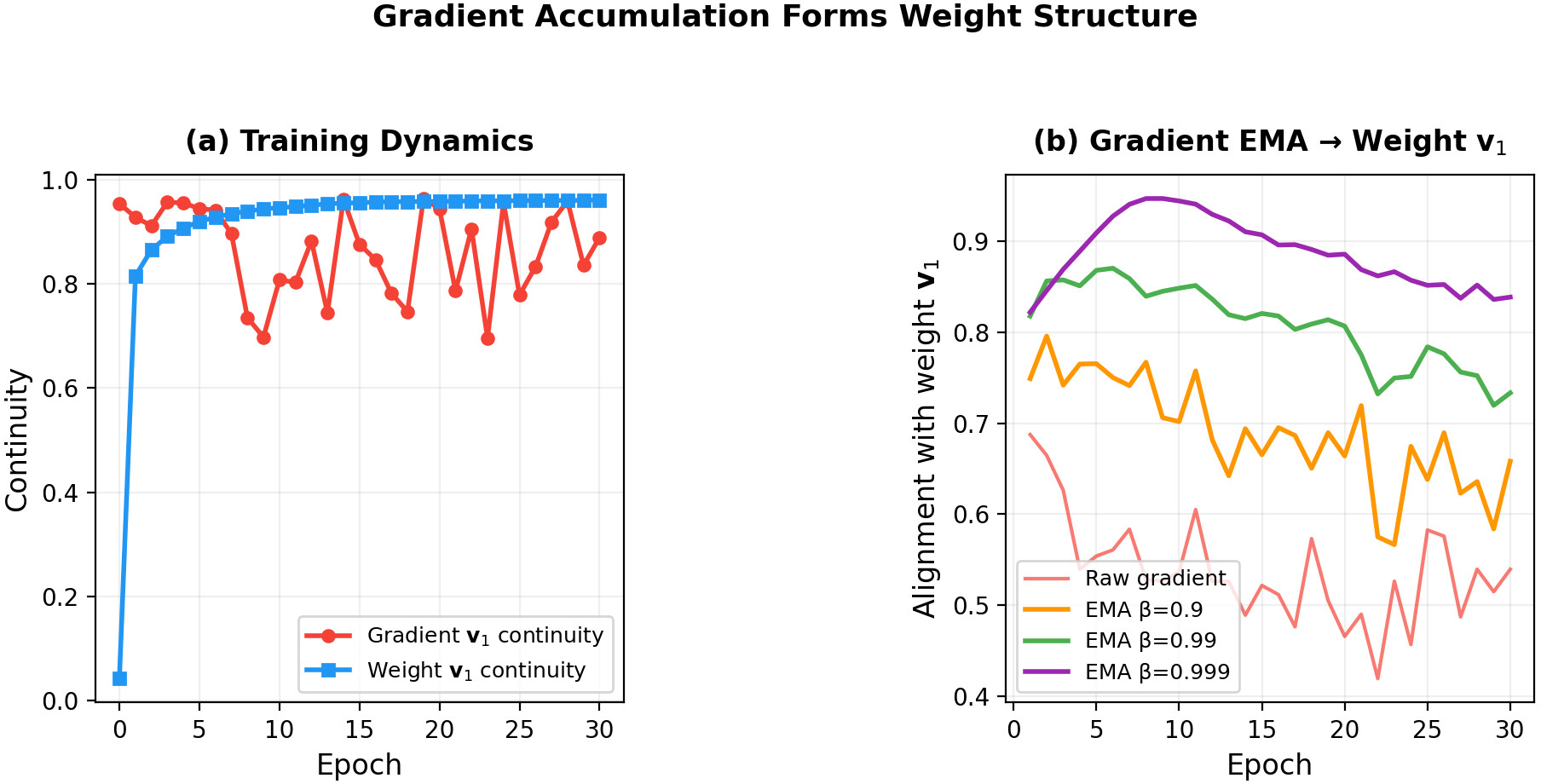
Figure 3: Weight v1 continuity rises through training as weight structure reflects accumulated, cross-layer coherent gradient updates.
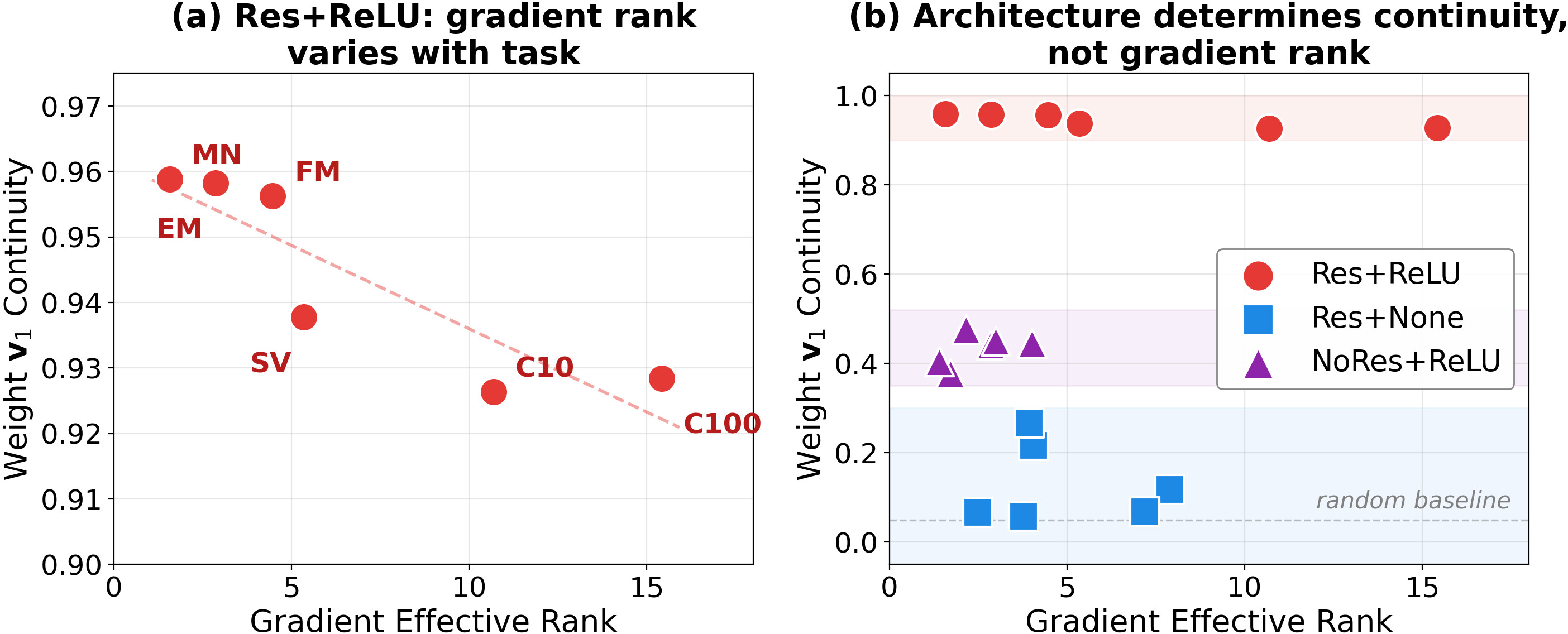
Figure 4: Across different datasets and architectures, only residual networks with symmetry-breaking nonlinearity stably exhibit high continuity, regardless of effective gradient rank.
A comprehensive extension to transformer models uncovers a striking projection-specific continuity pattern, rooted in the read/write semantics of the residual stream and the adjacency of nonlinearities:
- Q, K, Gate, Up projections ("read" from residual): Show high input-space (v1) continuity, consolidated by adjacent nonlinearities.
- O, Down projections ("write" to residual): Exhibit high output-space (u1) continuity.
- V projections: Lack adjacent nonlinearities and display negligible continuity in either space.
Disabling the MLP nonlinearity (e.g., by removing SiLU/GELU from Gate in the transformer MLP) empirically eliminates input-space continuity in Gate without severely degrading perplexity, suggesting that continuity is structural rather than performance-critical.
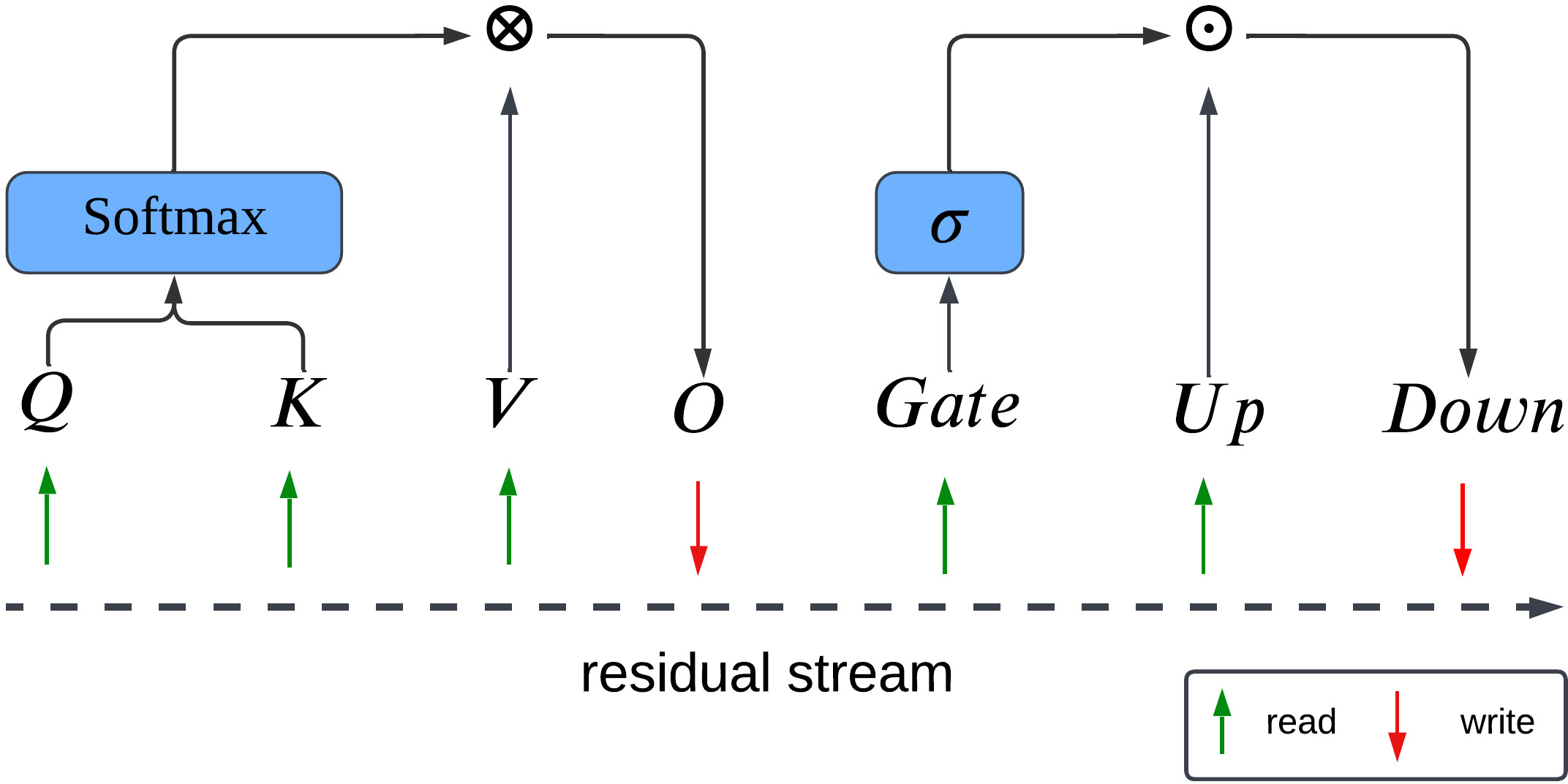
Figure 5: Schematic of projection-residual stream interactions in a transformer; only projections with nearby nonlinearities develop pronounced geometric continuity in the corresponding space.
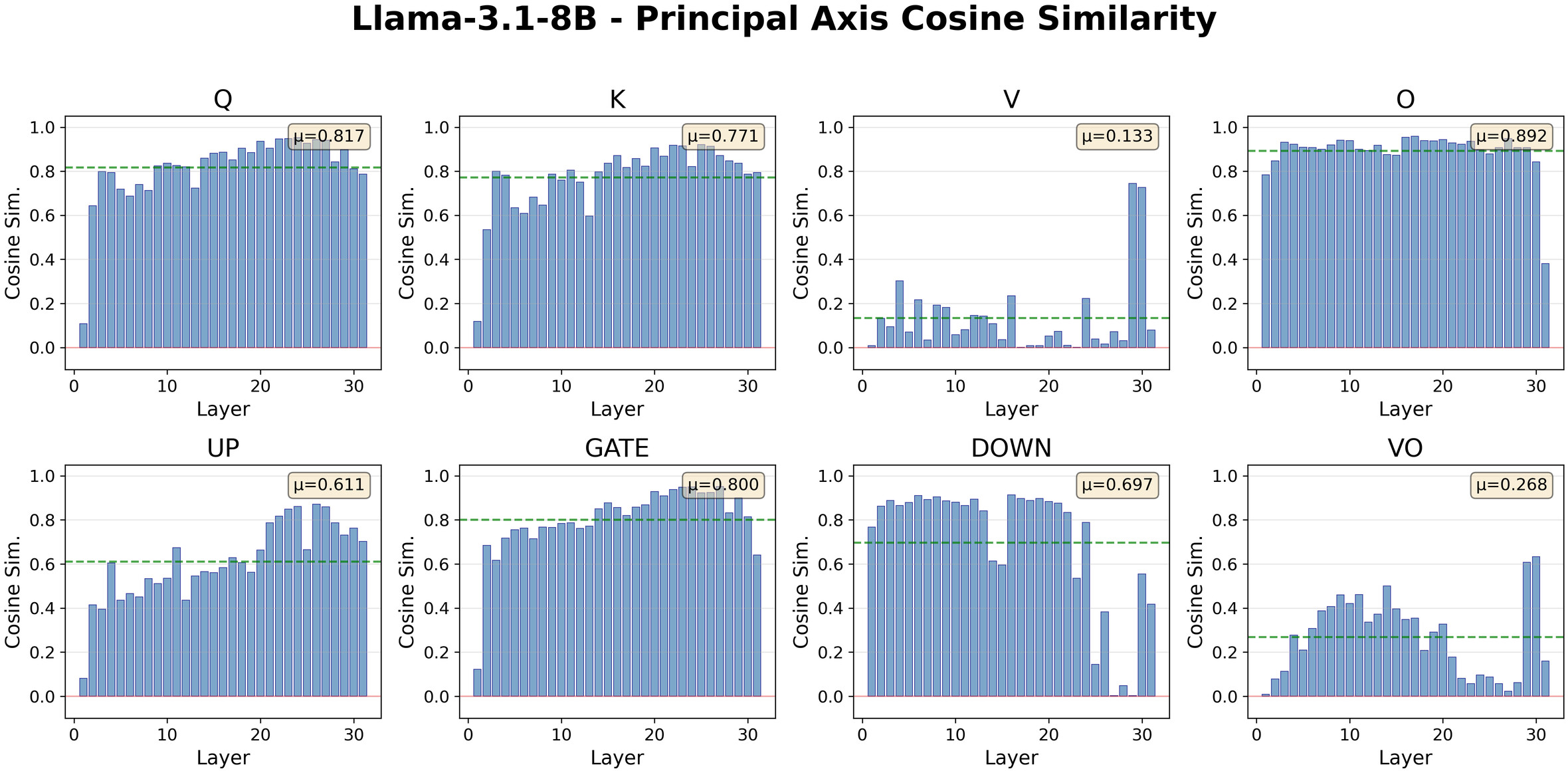
Figure 6: Layer-wise (cosine) continuity of singular vectors—projection-specific continuity emerges in the space (input or output) facing the residual/nonlinearity.
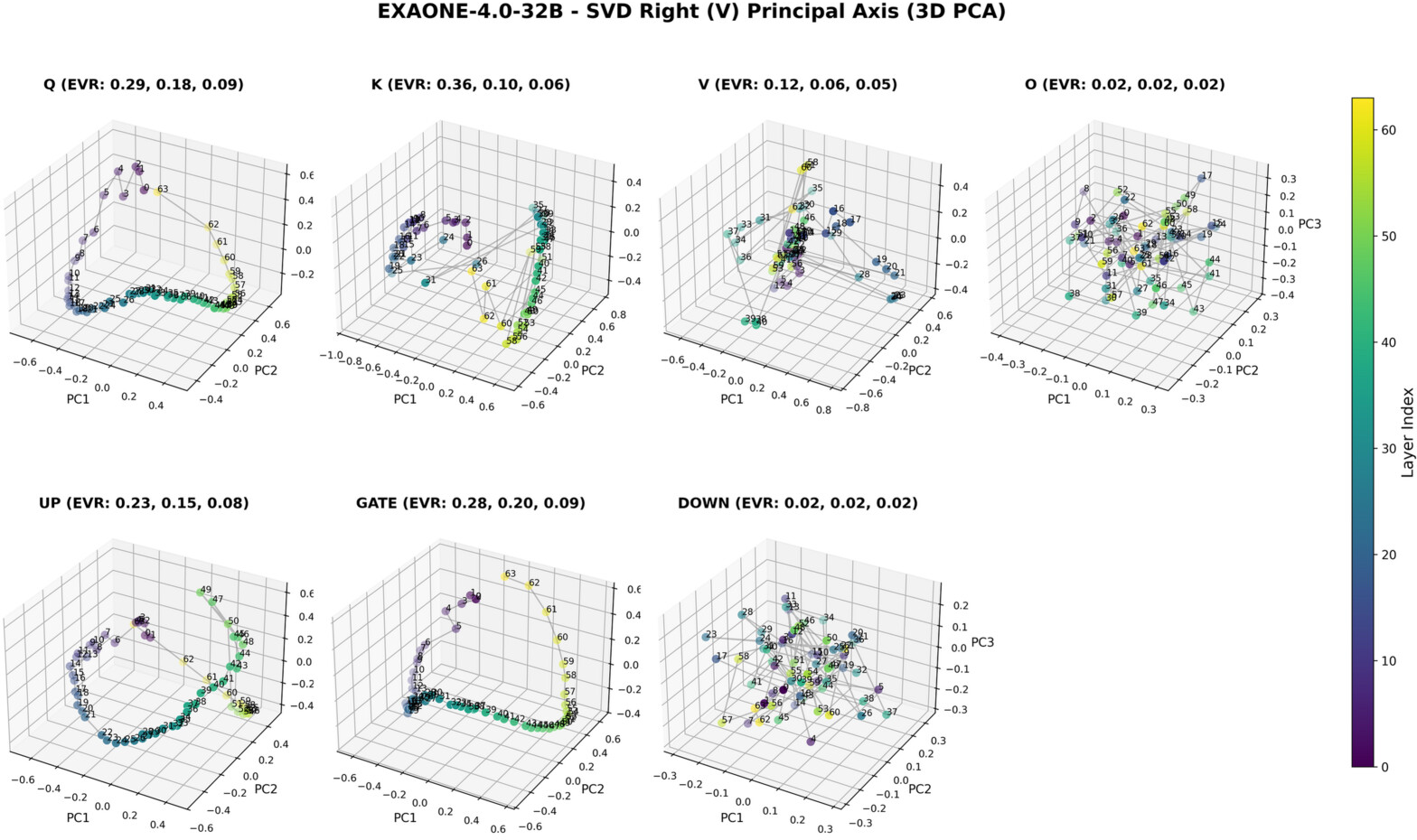
Figure 7: 3D PCA of principal right singular vectors (v1) in a large pretrained LLM reveals smoothly varying, coherent directionality for Q, K, Up, Gate (input space) across depth.
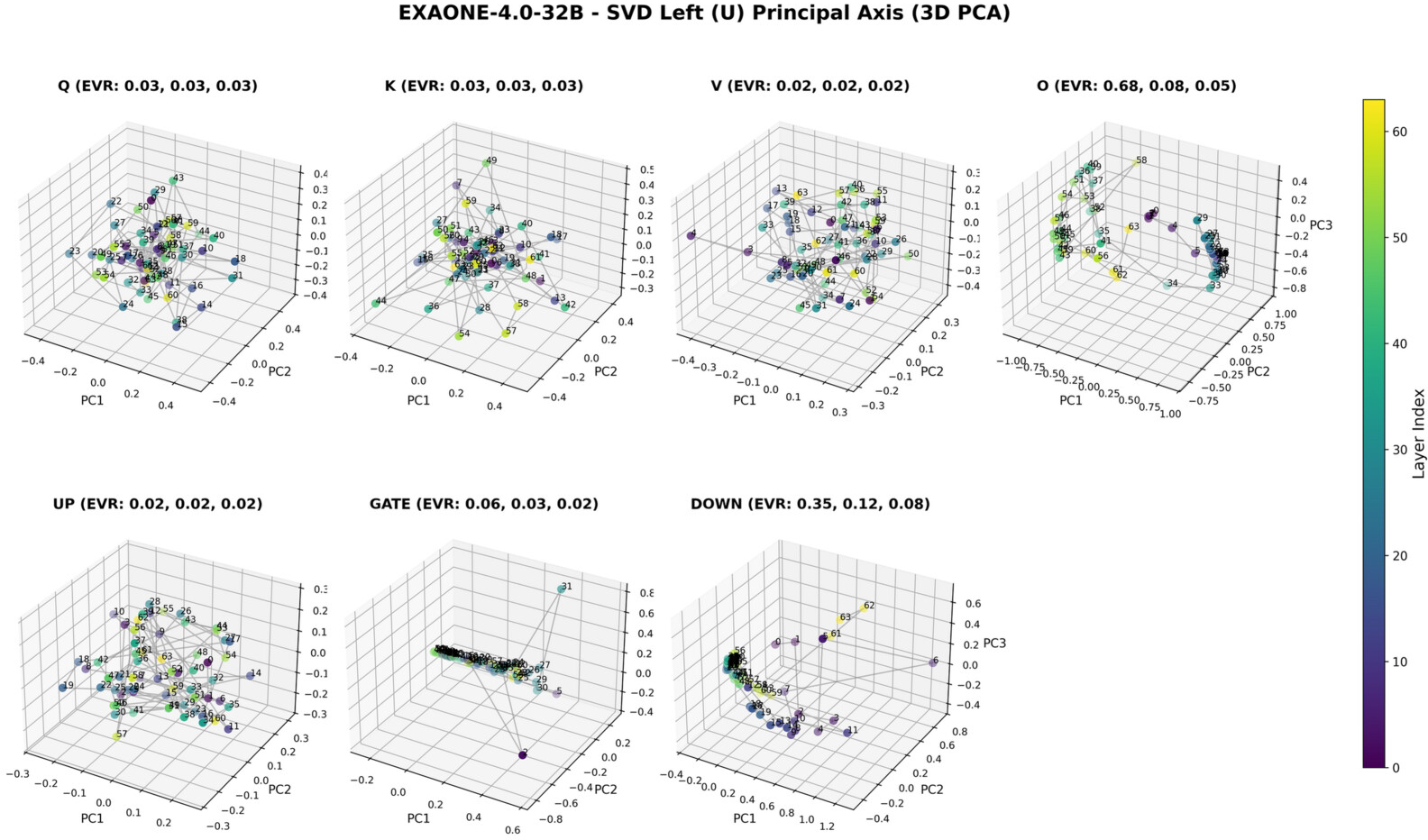
Figure 8: 3D PCA of principal left singular vectors (u1) shows analogous coherence for O, Down (output space).
Implications and Prospective Developments
Model Compression and Architecture
The demonstration that geometric continuity arises inexorably from generic training dynamics—rather than peculiarities of data, scale, or initialization—provides a robust theoretical underpinning for numerous forms of cross-layer parameter sharing, model merging, and layer pruning. Techniques that exploit continuity for model compression gain principled justification, and projection-specific continuity profiles suggest the design of more targeted parameter sharing or structured pruning strategies in complex models.
Rotational Drift and Model Forgetting
The identification of rotational drift, and its quantifiable impact on continuity loss in the absence of symmetry-breaking, opens up avenues for diagnostics in continual learning and fine-tuning contexts. Monitoring rotation drift could serve as a proxy for catastrophic forgetting or structural loss during checkpoint merging and adaptation.
Theoretical Significance
The analysis bridges prior theoretical results on the symmetry of deep linear systems, implicit regularization toward ODE-like solutions in residual networks, and the precise effects of activations on the reduction of symmetry groups. This clarified mechanism for the emergence of geometric continuity provides a unifying framework for interpreting recent empirical findings in weight matrix geometry.
Conclusion
This work rigorously elucidates the mechanisms driving the formation and stabilization of geometric continuity in deep neural networks. Geometric continuity is a robust emergent property of residual architectures with explicit symmetry-breaking nonlinearities, causally traceable to the accumulation of coherent gradients and the anchoring of weight frames. The findings generalize to high-performance transformer models, exhibit architectural specificity, and inform numerous theoretically grounded directions for model design, compression, and diagnostics.

