- The paper introduces the Feature Learning Equation, showing that gradient descent implicitly updates hidden features via the weight Gram matrix.
- Empirical findings demonstrate that Gram-only updates can match or outperform standard gradient descent on benchmarks like MNIST, SVHN, and CIFAR.
- The study proposes Target Linearity as a universal metric linking representation quality with phenomena such as Neural Collapse and latent space interpolation.
Weight Gram Matrix as the Fundamental Driver of Sequential Feature Linearization in Deep Networks
Feature-Centric Framework: The Feature Learning Equation
The paper develops a feature-centric analysis for training deep neural networks, contrasting with prior parameter-centric perspectives that focus primarily on weights or kernel-based regimes (e.g., NTK). The principal theoretical device is the Feature Learning Equation (FL Equation), which relates gradients in weight space to the evolution of hidden features via the weight Gram matrix. Specifically, it is established that for any layer, the evolution of feature covariance is directly encoded in the Gram matrix update—gradient descent on weights implicitly steers feature representations as if features themselves were optimization variables.
This shift enables formalization of a "virtual trajectory" for features: rather than updating weights, one could envision updating features directly via the gradient of the loss in feature space, yielding a sequence of virtual updates whose covariance structure is characterized as the Virtual Covariance (VC).

Figure 1: The virtual update X~ progressively linearizes Swiss roll data in feature space, showing how GD indirectly affects feature geometry via the weight Gram matrix.
Empirical Sufficiency of Gram-Driven Updates
The FL Equation is empirically validated via a "Gram whitening" experiment. The gradient update is decomposed into Gram-altering and Gram-preserving components; replacing standard gradient descent with updates that solely modify the Gram matrix yields negligible differences in classification performance on MNIST, SVHN, CIFAR-10, and CIFAR-100, with Gram-only updates matching or even outperforming standard GD in some cases. This strongly supports the assertion that the learning signal relevant for feature evolution is carried primarily—or almost exclusively—by Gram dynamics.
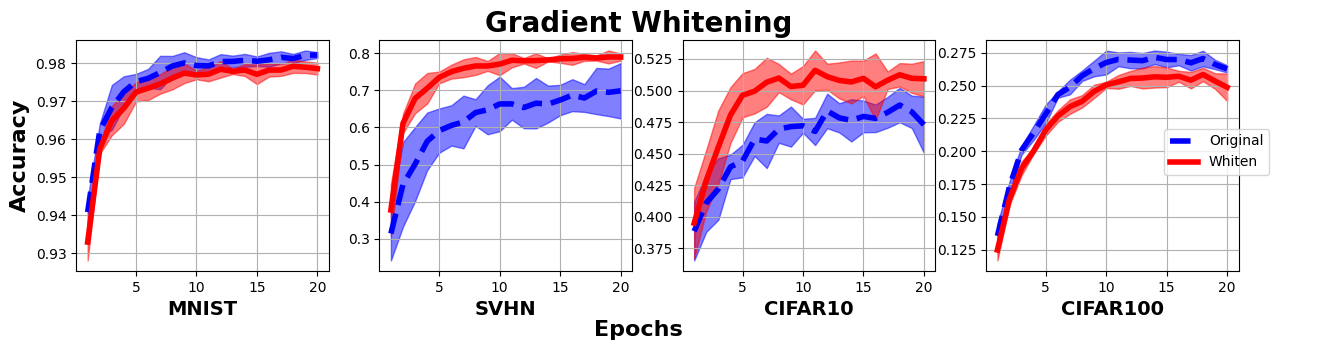
Figure 2: Comparison of test accuracy for standard GD versus Gram-only updates, indicating the sufficiency of Gram-driven updates for feature learning.
Explicit Dynamics: Weight Gram Tracks Virtual Covariance Shift
A central theoretical result formalizes the update: each GD step shifts the weight Gram matrix by an amount equal to the Virtual Covariance Shift (VCS)—the difference in covariance between the virtually updated and original features—up to second-order terms in the learning rate. This is proven for fully connected networks and extended to CNNs. The result is further substantiated by empirical analysis in which the sum of VCS exhibits a Pearson correlation of ρ≈0.98 with the Gram update, surpassing the ρ≈0.71 observed for AGOP (Average Gradient Outer Product), thus emphasizing the precision of the Gram/VCS correspondence.

Figure 3: Diagonal components of the weight Gram, AGOP, and VCS; VCS closely tracks the Gram, outperforming AGOP in correlation.
Additionally, it is shown that the actual hidden state updates induced by weight GD are tightly bounded and aligned (in both sign and magnitude) to the virtual updates, thus bridging abstract feature-centric analysis with concrete realizations in network operation.
Target Linearity: Quantitative Measure for Feature Linearization
The paper introduces Target Linearity (TL), defined via the R2 coefficient of (ridge) regression from features to targets. By leveraging the Woodbury identity, the implicit dependence of TL on the feature Gram is exposed, enabling analysis via a tractable surrogate function S(G)=Y⊤GY, where G is either the nonlinear Gram or its linearized counterpart. The surrogate admits a lower bound relationship to TL, allowing dynamics to be studied through Gram matrices.
Training and Layerwise Dynamics of Target Linearity
The dynamics of TL during training and across layers is analytically and empirically characterized:
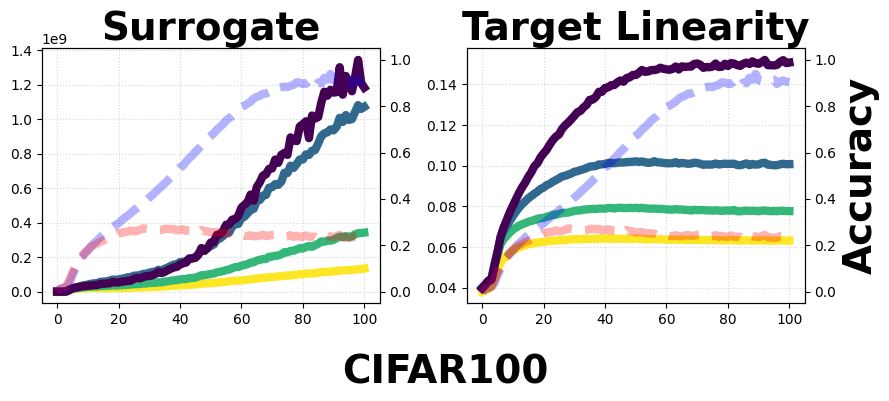
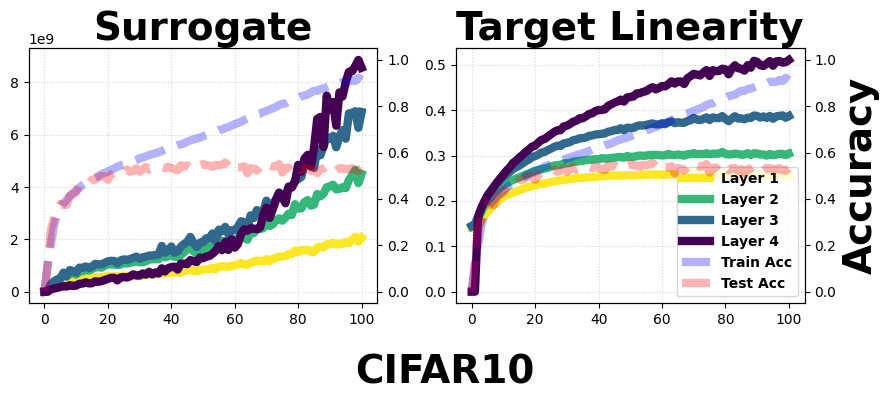
Figure 5: Surrogate and Target Linearity dynamics per layer for a 4-layer FC network on CIFAR-10 and CIFAR-100, exhibiting monotonic growth with depth and training epoch.
The empirical analysis with SGD and Adam optimizers confirms that both TL and its surrogate grow during training and increase with depth, with the surrogate showing exponential growth and TL logarithmic—in agreement with the theoretical lower-bound connection.
Generality and Connections: Neural Collapse and Latent Space Interpolation
The framework is shown to encompass notable phenomena:
Broader Implications: Generalization and Pretraining
The utility of TL as a universal metric for representation quality is highlighted:
- Pretrained Transformers: TL measured across layers of BERT for multiple tasks shows pretraining produces significantly more target-linear representations than random initialization, with fine-tuning quickly saturating TL throughout the network, producing monotonic profiles.
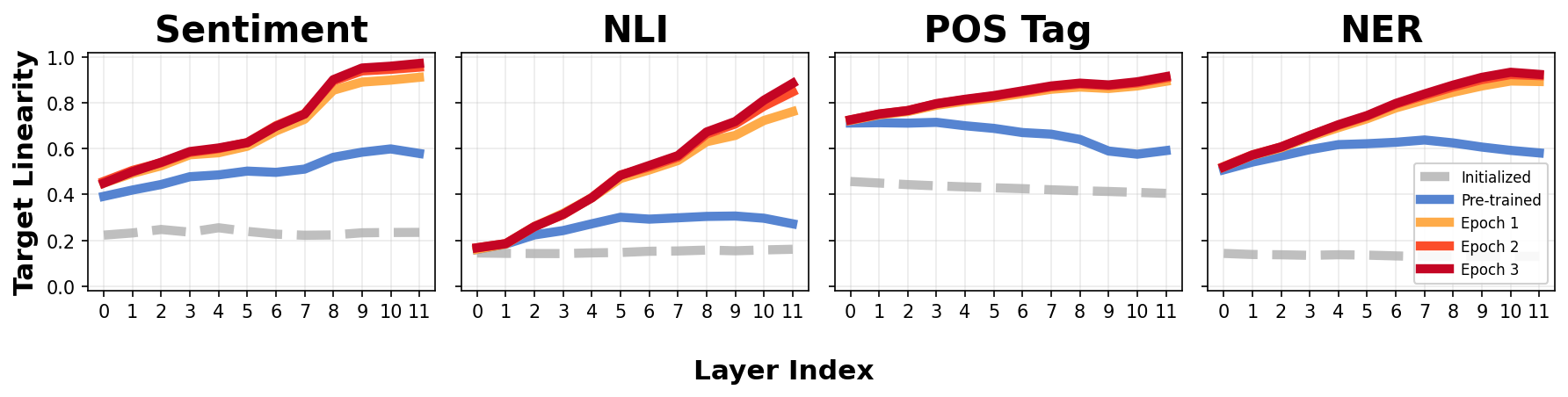
Figure 7: Layerwise TL for BERT across tasks; pretraining achieves substantial target linearity, further increased upon fine-tuning.
- Generalization Measurement: TL exhibits correlation with generalization performance; TL measured on training data is predictive of test accuracy, particularly across regime shifts such as random label memorization and grokking, with TL drop paralleling increased generalization gap.
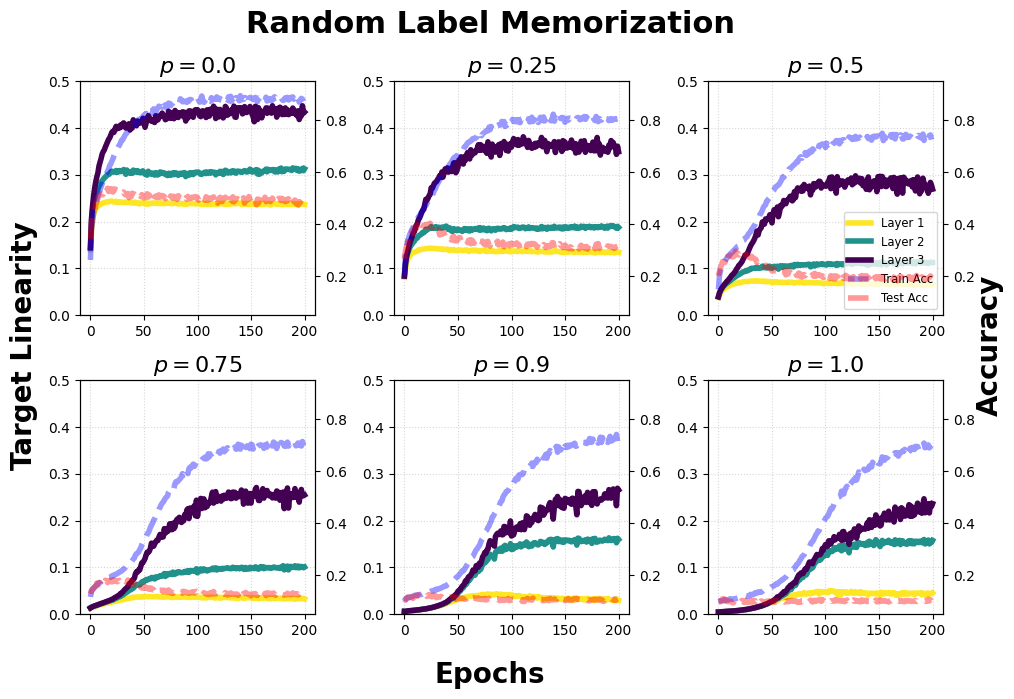
Figure 8: TL dynamics for randomly labeled CIFAR-10; increasing randomization reduces TL and worsens generalization.
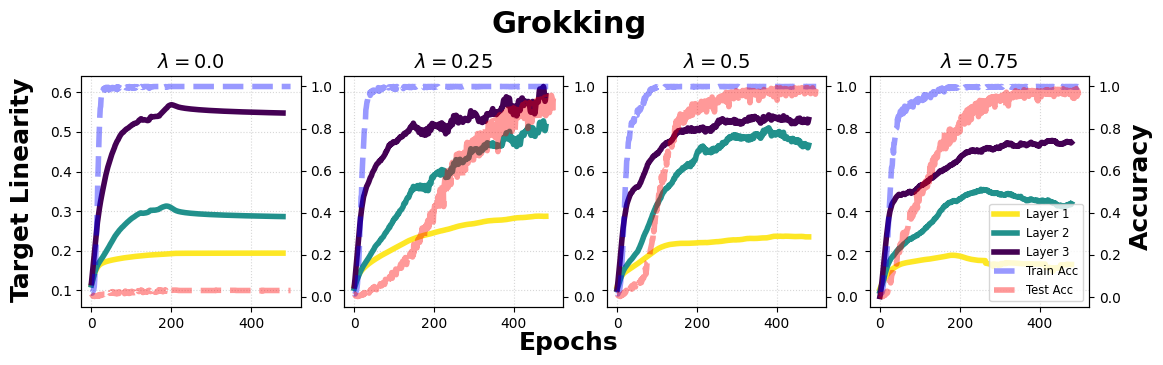
Figure 9: TL under grokking; TL increases during memorization and saturates after generalization, with layerwise TL gap tracking the emergence of grokking.
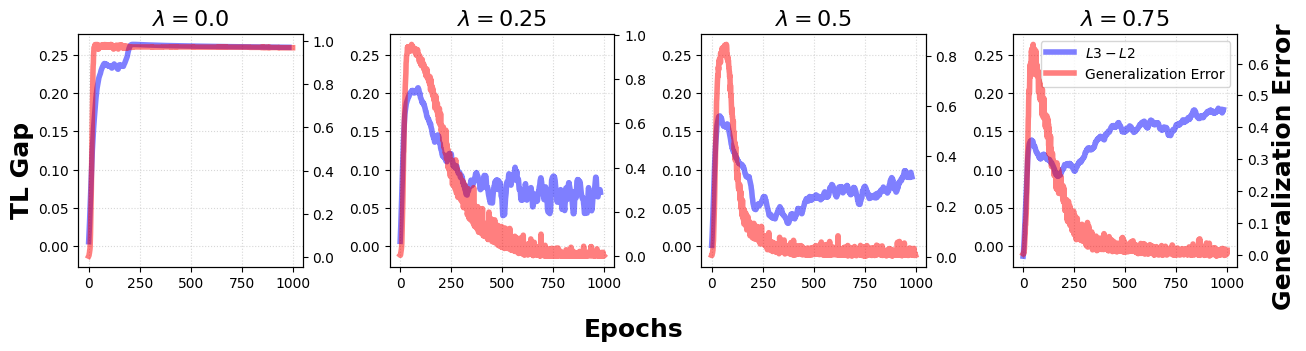
Figure 10: Comparison of TL gap and generalization error under grokking, indicating alignment between TL dynamics and test accuracy.
Conclusion
The paper positions the weight Gram matrix as the central entity controlling sequential feature linearization in deep networks, both theoretically and empirically. This feature-centric perspective, formalized via the Feature Learning Equation and Target Linearity, unifies disparate empirical phenomena (Neural Collapse, linear latent interpolation, linear probe accuracy) under a common framework. The Gram-centric dynamics are sufficient for learning, with Gram-only updates recovering full model performance. Layerwise and training dynamics show sequential linearization and moving-target behavior, distinct from static kernel regimes. Target Linearity emerges as a universal metric for representation quality, with practical implications for pretraining, generalization detection, algorithmic tasks, and model monitoring. Broadly, the results advocate for future analyses and architectures that leverage Gram-centric representation metrics, potentially enabling principled steering and selection of representations in AI systems.
Reference: "The Weight Gram Matrix Captures Sequential Feature Linearization in Deep Networks" (2605.06258).