- The paper's main contribution is the formulation of the Context Gathering Decision Process (CGDP) that models LLM agentic search as a POMDP, introducing modular interventions.
- The Predicate-Based Adaptive Identification algorithm mitigates state tracking failures by explicitly managing belief state and employing a programmatic exhaustion gate.
- Empirical results show up to 11.4% accuracy gains and 39% token savings, demonstrating significant practical improvements in complex, iterative search tasks.
The Context Gathering Decision Process: A POMDP Framework for Agentic Search
This paper addresses a fundamental constraint in the deployment of LLM agents: the inability to load and reason over large, complex environments (e.g., massive codebases, enterprise knowledge repositories, long conversational contexts) within a fixed-length context window. While prior work has extended LLM context windows and built various retrieval-augmented or agentic harnesses, these approaches frequently suffer from state tracking failures, including lossy memory, goal drift, repetitive loops, parametric hallucinations, and premature termination. Such failures undermine the reliability and efficiency of iterative agentic search.
To formalize the iterative information-seeking behavior of LLMs, the authors introduce the Context Gathering Decision Process (CGDP), specified as a specialized POMDP. Here, the hidden state is the full external corpus, actions correspond to tool invocations (e.g., code inspection, search queries), observations are returned documents or corpus fragments, and the agent’s objective is to adaptively refine an internal belief state sufficient for producing a correct answer while balancing exploration costs.
The Predicate-Based Adaptive Identification (PBAI) Algorithm
Leveraging the CGDP formulation, the paper models practical LLM behavior as approximate Thompson Sampling. The Predicate-Based Adaptive Identification (PBAI) framework is proposed to explicate the agent loop as four modular operations:
- Stop?: Assess current belief state for task completion.
- Select Action: Target an unresolved logical predicate with a new environment query.
- Observe: Extract evidence from the environment.
- Update Belief: Integrate new findings, resolve predicates, and expand the set of open questions.
State-of-the-art harnesses (ReAct, IRCoT, Iter-RetGen, MemGPT) are mapped to this paradigm, revealing systemic weaknesses in implicit belief state management, lack of robust stopping criteria, and the absence of explicit exploration strategies.
Modular Interventions: Predicate-Based Belief State and Exhaustion Gates
Two orchestrator-level, plug-and-play interventions are derived:
- Predicate-Based Belief State: The agent’s implicit, unbounded accumulation of context is replaced by an explicitly managed state, consisting of a curated, bounded list of established facts and unresolved predicates. This state is persistently tracked, regularly curated, and injected into the agent's prompt (either as structured JSON or a natural language freeform summary).
- Programmatic Exhaustion Gate: Decoupling search termination from poorly calibrated LLM self-assessments, this gate monitors action similarity (Jaccard overlap between queries) and observation novelty (Unique Passage Rate), exiting the search loop when repetitive behavior and low information gain are detected.
The orchestrator executes lightweight LLM-based extractors for belief updates and maintains strict capacity bounds to prevent unmanageable prompt expansion, ensuring focus on genuinely unresolved task elements.
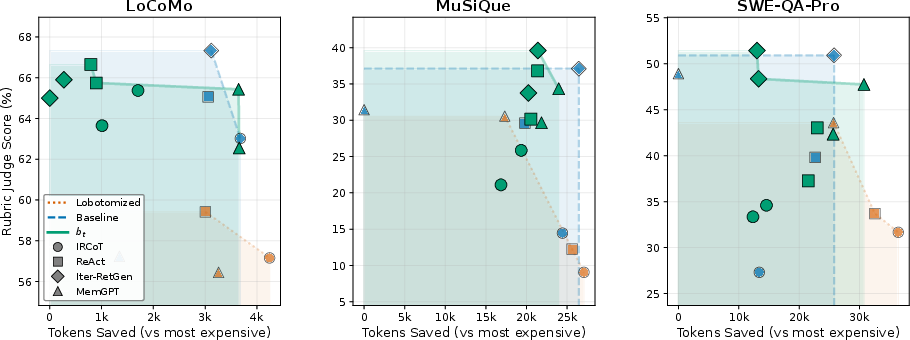
Figure 2: Pareto frontiers of answer quality versus token efficiency for multiple harnesses and memory regimes, demonstrating that predicate-based belief state (green) restores performance lost under lobotomization (orange), approaching the baseline (blue).
Empirical Analysis
Rigorous experiments were conducted on four harnesses (IRCoT, ReAct, MemGPT, Iter-RetGen) and three high-complexity domains (LoCoMo long-term conversational QA, MuSiQue multi-hop QA, SWE-QA-Pro repository-level code QA) using gpt-4o-mini. Agents share identical retriever settings, model prompts, and use programmatic, human-verified metrics for correctness and cost efficiency.
Results on Predicate-Based Belief State
Wiping all agent memory at each step (lobotomization) yields severe performance degradation. Remarkably, injecting a succinct, predicate-based belief state – even without access to the complete search history – not only fully recovers lost performance but, in several cases (e.g., MuSiQue, up to +11.4%), produces statistically significant improvements over unbounded-history baselines. Freeform natural language scratchpad representations consistently outperform rigid JSON schemas, as the latter induce undesirable artifacts (e.g., spurious 'no evidence' tags) and fragment reasoning.
Results on the Exhaustion Gate
Applying the programmatic exhaustion gate yields further accuracy gains (up to +6.9%) and produces substantial token savings (up to 39%) without sacrificing answer quality. In contrast, replacing the gate with LLM-based self-assessment either causes runaway cost increases (when acting conservatively) or induces early terminations and correctness losses (when prompted neutrally). The exhaustion gate is robust across harness designs and parameterizations.
Theoretical and Practical Implications
This work demonstrates that reframing the LLM agent loop as a CGDP exposes infrastructure faults unaddressed by prompt engineering, large context windows, or basic memory management. The explicit, persistent belief state and orchestrator-enforced stagnation detection directly counteract lossy state representations, premature stopping, and repetitive exploration, reducing both error rates and resource consumption.
This approach prescribes that orchestrators should enforce operations (such as belief state curation and search monitoring) rather than rigid representations, allowing LLMs to structure intermediate evidence in the linguistic form most conducive to downstream reasoning. The demonstrated interventions are practical – requiring only modular additions outside the agent's context window – and generalize across search harnesses and tasks with minimal hyperparameter tuning.
Limitations and Future Work
All results focus on a single agent backbone (GPT-4o-mini); generalization to other model families, especially smaller or instruction-tuned LLMs, is likely but untested. While the CGDP abstraction assumes a static, fixed corpus, future work could extend the formalism to evolving or adversarial environments. Further, orchestrator-managed interventions such as coverage tracking, entity-grounded extraction, and parallel trajectory aggregation represent promising extensions. The impact of such modular frameworks on meta-cognitive capabilities, error compounding, and coverage awareness in massive or adversarial search spaces warrants additional exploration.
Conclusion
Formulating LLM agentic search as a CGDP and decomposing it into explicit predicate-driven reasoning and programmatic stagnation detection yields robust, interpretable improvements in long-horizon tasks. This framework systematizes modular, orchestrator-level interventions that are empirically validated to improve accuracy, enhance multi-hop reasoning, and optimize token consumption, setting a new standard for reliability in complex agentic search.